一种基于记忆共享和注意力增强的人脸动画生成方法
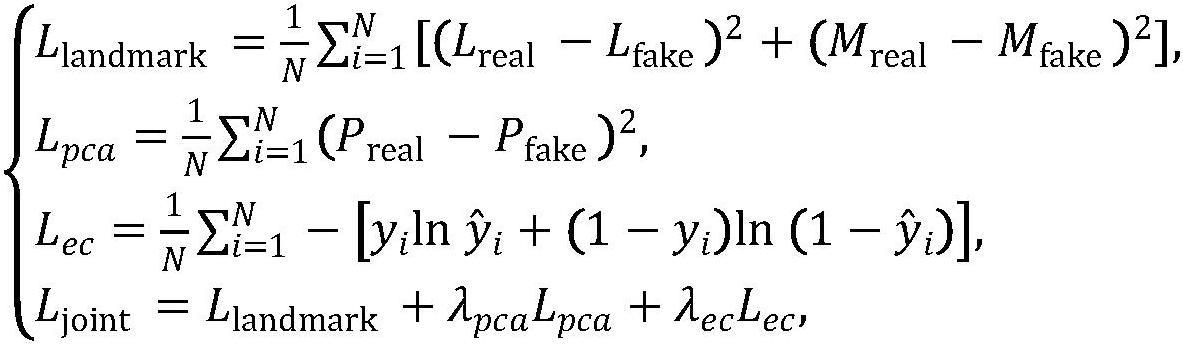
本发明属于语音驱动的人脸动画生成,具体涉及一种基于记忆共享和注意力增强的人脸动画生成方法。
背景技术:
1、传统的语音驱动的人脸动画生成方法依赖于机器学习,提出了基于混合高斯模型(gaussian mixture models,gmm)、动态贝叶斯网络(dynamic bayesian network,dbn)和耦合隐马尔可夫模型(coupled hidden markov model,chmm)等经典方法的人脸动画生成系统。但是gmm模型参数量过多,需要消耗大量的计算资源和时间,对于小数据集很容易出现过拟合问题。此外,gmm假设各个高斯分布的数据是独立同分布的,当数据分布不均匀或者数据间存在相关性时,会导致人脸动画生成效果不佳。chmm构建语音驱动的人脸动画生成系统,该方法显式地对视听特征进行建模,学习两者之间的映射关系。但由于chmm是基于hmm和gmm的混合模型,训练时同样需要较大的计算资源。同时,chmm对训练数据的质量和数量要求较高,对多模态数据建模困难。综上所述,基于传统机器学习的人脸动画生成方法具有一定的局限性。
2、近年来,深度学习的飞速发展和各种多模态数据库的出现为语音驱动的人脸动画生成任务提供了强大的技术支持,越来越多的方法开始应用深度学习来提高人脸动画生成的效果。基于深度学习的语音驱动的人脸动画生成任务可以细分为两种类型:(1)端到端生成语音驱动的人脸动画;(2)基于中间特征生成语音驱动的人脸动画,但两者各有不足。
3、(1)端到端生成语音驱动的人脸动画:该技术通过输入音频和参考图像,模型经过计算直接输出最终想要的像素级人脸动画。但是目前常见的端到端的人脸动画生成模型参数量大,往往导致模型过度拟合训练数据,生成过程中需要大量的计算资源和时间。
4、(2)基于中间特征生成语音驱动的人脸动画:该技术引入中间特征作为语音到人脸动画映射的桥梁。中间特征通常包括以下两种:基于2d人脸关键点和基于3dmm参数。它们各自存在局限:基于2d人脸关键点的方法,由于忽略面部表情导致存在一定的失真,并且生成人脸动画面部情绪表现力不足,也没有考虑到不同人的面部结构和外观特征的差异性,使得出现视频中人脸的皮肤纹理不一致,造成明显的伪影等问题。基于3dmm参数的方法,需要较高的计算成本,并且泛化性能无法得到保证。此外,3dmm参数只能表示人脸的几何形状,对具有高质量皮肤纹理的人脸动画渲染能力不佳。因此,基于3dmm参数的模型会不可避免地造成一定程度上的信息损失。
5、总而言之,目前关于语音驱动的人脸动画生成方法主要集中在提升唇部形状的准确度上,而忽略了对面部的高精细建模。一部分方法尝试通过生成自然的眨眼动作和头部姿势等来增强人脸动画的逼真度,但它们忽视了面部表情对人脸动画真实度的重要影响,在目标人物的身份保持度上也无法令人满意。最近的一些方法尝试通过视频驱动来生成具有可控表情的人脸动画,但生成的结果往往面部过于平滑,导致情绪表现力较弱。此外,丰富的面部表情会导致人物面部出现复杂的皮肤纹理和面部阴影,因此提升模型对这些细节的渲染能力也是要解决的问题之一。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于记忆共享和注意力增强的人脸动画生成方法,考虑了音频中情绪信息与人脸动画的相关性,针对音频情绪信息的特点提出了基于记忆共享的情绪特征提取器的人脸关键点回归方法;还提出了联合损失进一步优化人脸关键点回归网络。
2、本发明解决其技术问题是通过以下技术方案实现的:
3、一种基于记忆共享和注意力增强的人脸动画生成方法,其特征在于:所述方法包括:
4、(1)基于记忆共享的人脸关键点回归:系统地考虑音频中情绪信息与人脸动画的相关性,针对音频情绪信息的特点提出了基于记忆共享的情绪特征提取器的人脸关键点回归方法,还提出联合损失,进一步优化人脸关键点回归网络;
5、(2)基于注意力增强的人脸动画生成;提出基于残差u-net的注意力增强转译器,充分结合图片的浅层细节特征和深层语义特征,可以生成高度逼真的人脸动画。
6、而且,所述基于记忆共享的人脸关键点回归具体为:
7、1)两阶段人脸动画生成网络
8、在第一阶段人脸关键点回归网络中,接受音频和图像两种数据类型作为输入,分别对其进行特征编码,将提取到的特征拼接后作为关键点解码器的输入,输出与音频内容和参考人脸图片匹配的动态人脸关键点序列;
9、在第二阶段图像转译网络中,将预测的人脸关键点序列分别与参考人脸图片按通道拼接,作为图像转译器的输入,该模块输出与人脸关键点动作一致的像素级人脸动画;
10、2)记忆共享的情绪特征提取器
11、在提取情绪特征的卷积网络模块之间引入两个记忆共享单元m1和m2,记忆单元m1和m2采用两个级联的线性层实现,不会增加额外的计算复杂度;m1和m2是独立于输入的外部可学习参数,并被整个数据集所共享,具体来讲:
12、该情绪特征提取器将编码后的mfcc特征作为输入,经过多层感知机编码得到特征图,该特征图即为自身查询向量f∈rc×h×w(128×1×1),将其与外部可学习的记忆单元m1∈rd×c(64×128)计算相似度,将得到的结果进行双重归一化,即分别对行和列进行标准化,得到权重f1;之后将该权重图与另一个外部可学习记忆单元m2∈rd×c(64×128)相乘再进行卷积操作,得到精细化之后的权重,将f2与初始特征图f相加得到最终的情绪特征fe,具体公式如下:
13、
14、其中:g(·)表示卷积操作;
15、表示特征向量f第h个元素和m1的第w行之间的相似性;
16、norm(·)表示softmax归一化操作;
17、此外,在记忆共享的情绪特征提取器之后,还添加一个额外的情绪分类器,对于包含8种情绪类别的mead数据集,该分类器采用全连接层将情绪特征fe降为8维特征向量,对于包含6种情绪类别的crema-d数据集将其降为6维特征向量,降维后的特征经过softmax函数归一化之后,通过lec损失函数梯度下降来训练模型的参数;
18、为了使记忆共享的情绪特征提取器模型能够在精确拟合面部轮廓的同时,一定程度上保证唇部精度,提出联合损失函数,该损失函数主要由三个部分组成:llandmark,lpca和lcc;
19、首先,llandmark是人脸关键点回归网络的主要损失函数,用于衡量生成的关键点和真实关键点在像素空间中的距离,通过优化这个损失函数,网络可以在一定程度上拟合人脸关键点;此外,llandmark中增加了唇部关键点的权重,使得网络能够在关注人脸面部轮廓的同时,一定程度上保证唇部的精确度;
20、其次,lpca是真实人脸关键点和生成的人脸关键点在降维后的特征空间中的均方误差,用来衡量生成的关键点和真实关键点在特征空间中的距离;
21、最后,lcc是情绪分类损失,用于有监督地训练情绪特征提取器,目的是通过情绪分类任务来强制特征提取器学习音频中情绪相关的特征,具体公式如下:
22、
23、其中:n表示人脸关键点序列总帧数;
24、超参数λpca和λec表示缩放因子,用来平衡不同部分的重要性;
25、lreal表示真正的68个目标人脸关键点;
26、lfake表示预测的68个人脸关键点;
27、mreal表示真正的目标人脸关键点的唇部区域;
28、mfake表示预测的目标人脸关键点的唇部区域;
29、preal和pfake表示降维后的真实人脸关键点和生成的人脸关键点;人脸关键点回归网络采用联合损失函数ljoint,通过梯度下降的方式训练模型参数。
30、而且,所述基于注意力增强的人脸动画生成具体为:
31、1)基于残差u-net的注意力增强转译器
32、该注意力增强转译器整体结构基于u-net,包括编码器和解码器,编码器由6个下采样卷积块组成,解码器为与编码器结构对称的上采样卷积块,编解码器之间通过跳跃连接保留了浅层局部特征,有助于捕捉图像的风格和内容信息,提高人脸动画的逼真度;
33、在编解码器的前四层之间,引入了卷积块注意力模块,这个注意力模块包括通道注意力模块和空间注意力模块,用于自适应地调整关键特征的权重,以提高生成图像的质量;通道注意力模块根据不同通道的重要性和关系,调整人脸关键点和参考人脸图像拼接后的权重,以更好地捕捉人脸的姿态信息;空间注意力模块则根据人脸形态的变化,自适应地调整关键点附近像素的权重,抑制与人脸形态不相关的像素权重,从而消除噪声和冗余信息;
34、通道注意力模块将特征图分别进行最大池化和平均池化,然后将处理后的特征图输入权重共享的全连接层,得到两个特征向量,最后将其拼接并经过sigmoid函数激活,得到通道维度上的注意力权重mcam;原始特征图与mcam相乘后得到特征图fcam,作为空间注意力模块的输入,同样进行平均池化和最大池化之后将得到的特征图按通道维度拼接,然后经过卷积层并进行sigmoid函数激活,得到空间维度上的注意力权重msam,将fcam与msam相乘即为最终输出的特征图fcbam,具体计算过程如下:
35、
36、其中:avgpool和maxpool分别表示平均池化和最大池化;
37、g3×3(·)表示卷积层操作;
38、空间注意力权重使得模型能够更加关注图像中变化最为频繁的一部分;通道注意力用于计算特征图通道之间的分布关系,计算出其中关键信息包含最多的通道,从而提高特征表示能力,卷积块注意力模块通过增强特征表示和提高定位精度,有效增强模型对于人脸面部表情的渲染能力,提升了人脸动画的逼真度;
39、为进一步提高生成的人脸动画的逼真度,增加额外的感知损失函数,该损失函数通过计算真实图像和生成图像之间在特征空间上的差异来评估生成图像的质量,具体而言,该感知损失函数使用预训练的vgg-19网络作为特征提取器,将真实图像和生成图像都输入该网络,并在不同的卷积层处提取特征;然后,通过计算这些特征之间的l1损失函数和风格损失函数来度量真实图像和生成图像之间的相似度,vgg-19网络包含19个卷积层,网络结构只包含卷积层和池化层,且每个卷积核大小均为3×3,每个池化核大小均为2×2,本专利将整个vgg-19网络划分为5组,感知损失函数具体公式如下:
40、
41、其中:n表示网络划分组数;
42、φ表示vgg-19特征提取网络;
43、g表示gram矩阵;
44、图像转译网络的最终损失函数为:
45、l=l1+lperceptual。
46、本发明的优点和有益效果为:
47、1、本发明基于记忆共享和注意力增强的人脸动画生成方法,提出了基于记忆共享的人脸关键点回归方法,该方法通过显式提取音频中隐含的情绪特征,增强模型对分布在全局的音频情绪特征的捕获能力,从而实现在不同情绪下实现高精度的人脸关键点预测。相比于现有模型缺乏对情绪特征的捕获能力,该方法设计了记忆共享的情绪特征提取器,确保模型对情绪特征的捕获能力,同时不降低原有模型关键点回归能力,确保模型对情绪特征的捕获能力,最终实现高精度情绪人脸关键点回归。基于记忆共享情绪特征提取器的人脸关键点回归方法相较于仅提取音频内容特征的方法,在人脸关键点回归中,特别是在面部轮廓f-lmd和唇部轮廓m-lmd方面,性能均得到明显提升。
48、2、本发明基于记忆共享和注意力增强的人脸动画生成方法,提出基于残差u-net的注意力增强转译器,用于像素级人脸动画生成,该模块采用残差u-net架构,并加入卷积块注意力模块,同时关注图像的浅层细节特征和深层语义特征,增强模型对重要信息的关注能力,抑制无用特征。通过以上两点,该方法有效提升了人脸动画的皮肤纹理、光影等细节的渲染能力,并增强目标人物面部情绪的表现力,从而进一步提高了人脸动画的逼真度。
49、3、本发明基于记忆共享和注意力增强的人脸动画生成方法,提升了图像质量和接受度,基于残差u-net的注意力增强转译器有效提升了生成人脸动画的图像质量。通过主观实验验证,提升人脸动画的面部情绪表现力后,人们对于生成人脸动画的接受度明显提高。这意味着该方法能够产生更具情感表达和真实的人脸动画,增强了用户对动画角色的共情能力,提升了观众的观赏体验和接受度。
- 还没有人留言评论。精彩留言会获得点赞!