一种基于树综合多样性深度森林的图像分类方法
本发明涉及一种基于树综合多样性深度森林的图像分类方法,属于数据挖掘中多类别分类应用。
背景技术:
1、深度森林是近几年提出的一种基于不可微模块实现的深度学习方法,它与深度神经网络相比,拥有更少的超参数,并且它的复杂度可以根据数据集的复杂程度自适应地进行确定,因此更加容易训练。自从深度森林提出以来,它已经得到了学术界和工业界的广泛关注,它被广泛应用于各种领域,如金融应用,疾病分类和计算机视觉等。大量的实验结果表明,深度森林在很多分类任务上相比于深度神经网络有着更好的性能表现。
2、深度森林主要由两个模块组成:多粒度扫描,级联森林。多粒度扫描多用于处理维度较高且特征间存在关联的数据集,它通过使用不同尺度的滑动窗口扫描数据特征,之后输入随机森林或者完全随机森林,最后获得它们输出的特征,以实现转换特征的目的。级联森林是深度森林的核心模块,它由多个级联层组成,每一个级联层包含了一个或者多个独立的随机森林和完全随机森林。其中随机森林和完全随机森林是由多棵决策树构成的。每一个级联层的森林会生成对应的类概率向量,之后拼接原始数据共同作为一个新的训练数据输入到下一层。不断基于新的训练数据对后续的级联层进行训练,直至满足预先设定的结束条件,这样构成了深度学习的模式。
3、深度森林是基于大量决策树的集成模型,能够取得远优于单棵决策树的性能表现。深度森林的特征表示是由预测类概率向量组成,这种基于预测的表示在训练过程中需要保存大量的森林模型,以便在测试期间使用。这将导致训练效率低以及时间、内存和存储开销大的问题。在大型的数据集上,训练一个深度森林模型可能需要几十个gb的运行内存以及几十个小时的运行时间,这很大程度上阻碍了深度森林在实际场景中的应用。
技术实现思路
1、本发明提出一种基于树综合多样性深度森林的图像分类方法,利用剪枝的方法来解决原始的深度森林算法中存在的训练效率低以及时间、内存和存储开销大的问题,将其应用于图像分类,提高图像分类的效率。
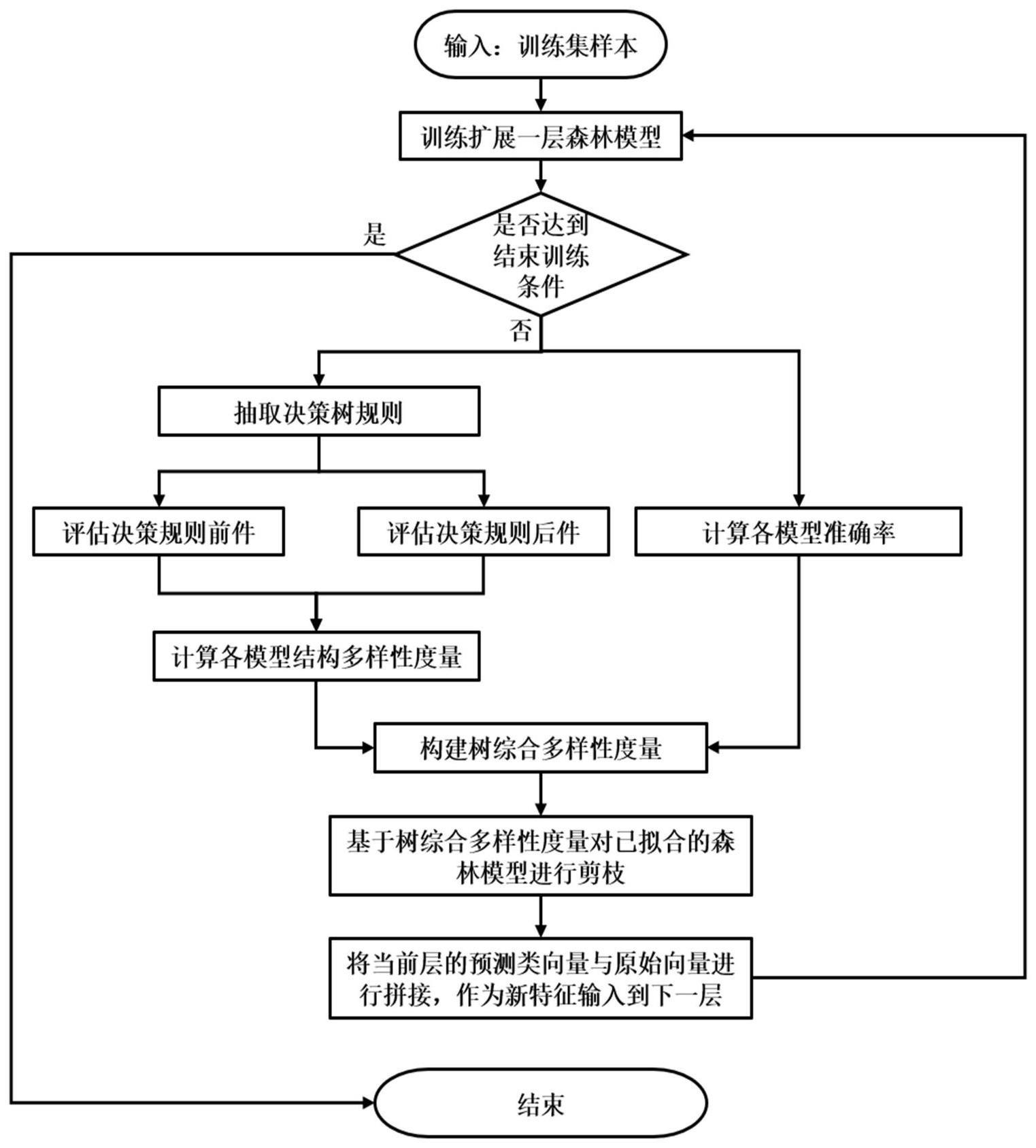
2、本发明的技术方案是:首先根据决策树模型的特点,设计了一种仅针对树模型形态结构的多样性度量标准,计算树模型间的多样性;然后,为综合考虑树模型间的多样性和准确率的关系,提出树综合多样性排序剪枝算法,并将其应用于深度森林中以优化级联层中的随机森林;最后根据剪枝后精简高效的森林模型,完成图像样本分类。所述方法的具体步骤如下:
3、step1获取图像形成训练集;
4、step2将训练集的特征输入到级联森林,对级联层进行训练,级联层中包含随机森林和完全随机森林;
5、step3从已训练好森林中的每棵决策树解析出多条决策规则;
6、给定d个特征,c个类别的分类数据集构建决策树森林模型,对于森林中的每棵决策树都能解析出r条决策规则,只使用决策树分裂结点所使用的分裂特征来描述,从树模型的根结点出发进行深度遍历,在遍历过程中获取决策路径上的分裂特征,一条包含d个分裂特征和对应类标签c的决策规则的简单形式如下所示:
7、ruler:if feature1&feature2,...,&featured|then response class c
8、整条决策规则分为前件和后件两个部分,即前半部分的分裂特征和后半部分的对应类别,单棵决策树会产生的r条包含不同特征的决策规则,对r条决策规则取交集,得到包含单棵决策树所使用的全部分裂特征的序列,对于含有n个决策树的森林模型,则会产生n条规则序列。
9、step4针对决策规则的前件和后件分别进行度量,得到对称的jaccard相似性矩阵p和cosine相似度矩阵q;
10、对于决策规则前件,使用词袋模型将每一个序列转换成一个固定长度的特征向量。规则特征向量是一个二进制向量,如果向量中的某元素值为1,代表决策规则使用了对应的特征;值为0则代表未使用。通过决策规则向量化,决策规则间的相似度比较则可以转化为特征向量间的相似度比较。为了能够在使用较小的内存空间和在线性时间内估计任意长度的向量间的jaccard相似性,使用最小哈希算法进行计算,得到大小为n×n对称的jaccard相似性矩阵p。
11、对于决策规则后件,统计单棵决策树中各个类别对应决策规则的数量,并生成对应的规则数向量sn=[sn0,sn1,...,snc],snc代表第n棵决策树中属于类别c的规则数量。规则数向量snc的维度是动态变化的,向量维度随不同数据集的类别数量的改变而改变。得到n个规则数向量后,采用余弦相似度进行度量,假设有两个向量a和b,它们间的余弦相似度定义如下所示:
12、
13、其中c是向量维度,ai和bi分别是向量a和b在第i维的元素,通过计算可得到大小为n×n对称的cosine相似性度量矩阵q。
14、step5同时权衡关于决策规则前件和后件的两个相似性矩阵,计算获得树模型在形态结构上的相似性度量;
15、得到的两个对称相似性度量矩阵p和q,分别对应着决策规则的前件与后件,即树模型结构中的分裂结点和叶子结点。这两个矩阵中的相似性的度量值的范围都处于[0,1]之间,其值越大,相似性越大。应用如下公式进行计算得到关于决策树形态结构的相似性矩阵t
16、t=αp+(1-α)q,α∈[0,1]
17、α为权衡参数,其取值范围在[0,1]之间。α的值越靠近0则更注重规则数度量,越靠近1则更关注决策规则特征的度量。此度量独立于具体的样本数据,仅代表着随机森林中成对决策树间形态结构上的差异。
18、step6综合考虑树模型内部形态结构的相似性和准确率,从中挑选出准确率高且多样性大的决策树;
19、假设一个具有n个基分类器的集成其中单个分类器hi的多样性被定义为除本身之外的所有成对度量的平均值,定义如下:
20、
21、公式中similarity(ti,tj)是结构相似性矩阵t中第i行,第j列的值。由于不同数据集的准确率和多样性的数值范围处于不同区间,直接对其进行加权计算是不合适的。计算得出集成模型中各基分类器的准确率和多样性之后,使用min-max缩放方法对数据进行缩放,将准确率和多样性的值各自映射到[0,1]的区间范围,具体的缩放公式如下:
22、
23、变量x’代表的是某个基分类器在区间缩放之后的准确率值或多样性值,其值越大,代表准确率越高或多样性越大。最后给出综合结构多样性div(hi)和模型准确性acc(hi)的剪枝方法评估准则,其定义如下:
24、
25、通过给定合适的权衡参数ρ计算树综合多样性的值,从树综合多样性度量的排序列表中,挑选出个具有最大位序的基分类器构成集成修剪后集成子集。
26、step7根据剪枝后的森林模型,对待分类图像分类。
27、进一步地,所述step3中计算jaccard相似性所使用的最小哈希算法具体包括以下步骤:
28、(1)首先定义k个独立且均匀的随机哈希函数。对于第i个规则特征向量,需要迭代向量中的每个元素并选取该元素在第k个哈希函数中的最小哈希值作为签名,最终可得到k个最小哈希值组成的k维签名向量mi=[mi0,mi1,...,mik]。
29、(2)对于n个规则特征向量,重复步骤(1)即可得到一个大小为n×k的minhash签名矩阵m,矩阵中的每个元素是相应散列函数的最小散列值。该签名矩阵可以用来计算n个向量间的jaccard相似度估计。
30、(3)假设签名矩阵m中的两个向量mi和mj,它们间的相似度估计根据如下公式计算得到,其中i(.)是指示函数,用来统计两向量中具有相同哈希值的元素个数。该计数除以签名向量的长度是对两个向量之间的jaccard相似性的估计值。所有向量间的成对相似性计算结果存储在大小为n×n的对称的相似度矩阵p中,其值越大,代表相似性越大。
31、
32、本发明与现有技术相比,具有以下优点:
33、本发明设计了一种针对树模型形态结构的多样性度量标准,其中将决策树的分裂结点和叶子结点分别进行了衡量,使得树模型间关于形态结构的多样性能够全面且准确地度量。本发明综合考虑树模型间的多样性和准确率的关系,并通过树综合多样性排序剪枝算法对深度森林中的随机森林进行剪枝,能够有效地减少级联层中产生的时间、内存和存储开销。相比于原始深度森林模型,通过剪枝操作可以从原本的集成模型中选出多样性大且准确率高的集成子集,有效提高了图像分类任务的预测性能和效率。
- 还没有人留言评论。精彩留言会获得点赞!