文本匹配方法、装置和计算机可读存储介质与流程
本技术涉及计算机,具体涉及一种文本匹配方法、装置和计算机可读存储介质。
背景技术:
1、随着计算机技术的快速发展,文本匹配的要求越来越高,文本匹配是指对文本语义关系建模的一种被广泛使用的nlp(natural language processing)技术,主要应用在信息检索、文档系统、对话系统等领域。在这些应用场景下,均希望文本匹配的分数可以体现文本间语义的相似程度,即文本匹配分数越高,文本间语义应越相似。
2、在对现有技术的研究和实践过程中发现,现有的文本匹配方法在确定文本间匹配分数时极易受到两个文本间重复字词数量的影响,例如,文本对(适合情侣看的电影,适合儿童看的电影)将会具有较高的匹配分数,因此,采用现有文本匹配方法确定的文本匹配分数来衡量文本间的相似度,会导致文本匹配的准确性较低。
技术实现思路
1、本技术实施例提供一种文本匹配方法、装置和计算机可读存储介质,可以提高文本匹配的准确性。
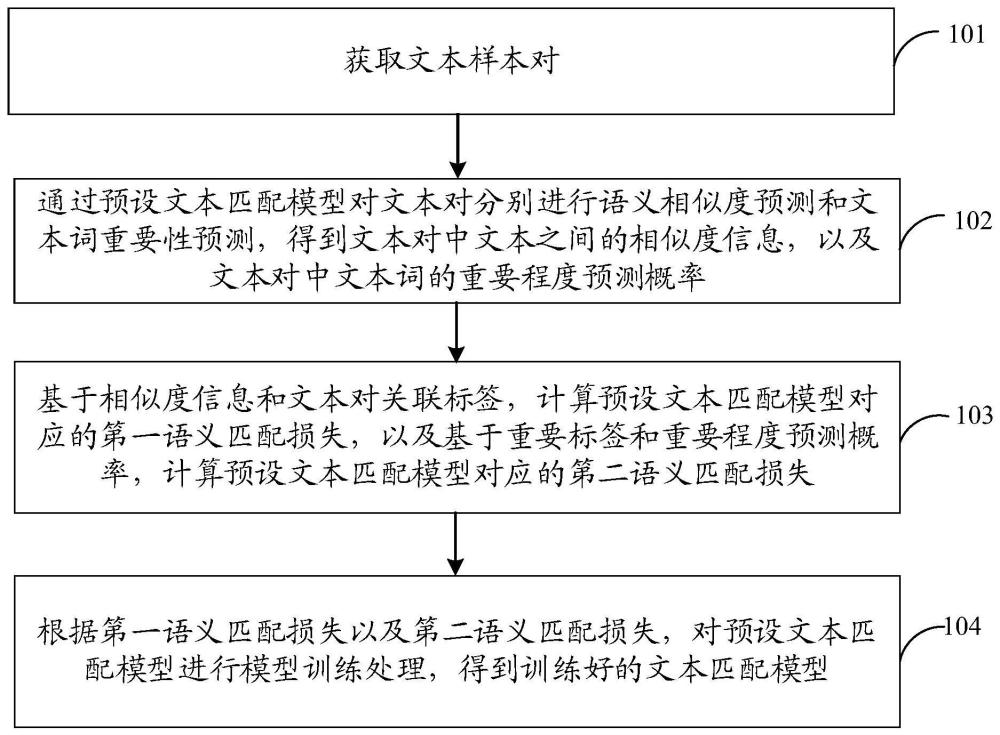
2、本技术实施例提供一种文本匹配方法,包括:
3、获取文本样本对,所述文本样本对包括文本对、所述文本对的文本对关联标签以及所述文本对中文本词的重要标签,所述文本对关联标签指示所述文本对中文本的语义相似程度,所述重要标签指示所述文本对中的文本词在其所属文本中的重要程度;
4、通过预设文本匹配模型对所述文本对分别进行语义相似度预测和文本词重要性预测,得到所述文本对中文本之间的相似度信息,以及所述文本对中文本词的重要程度预测概率;
5、基于所述相似度信息和所述文本对关联标签,计算所述预设文本匹配模型对应的第一语义匹配损失,以及基于所述重要标签和所述重要程度预测概率,计算所述预设文本匹配模型对应的第二语义匹配损失;
6、根据所述第一语义匹配损失以及所述第二语义匹配损失,对所述预设文本匹配模型进行模型训练处理,得到训练好的文本匹配模型,所述训练好的文本匹配模型用于对待识别文本对进行文本匹配处理。
7、相应的,本技术实施例提供一种文本匹配装置,包括:
8、获取单元,用于获取文本样本对,所述文本样本对包括文本对、所述文本对的文本对关联标签以及所述文本对中文本词的重要标签,所述文本对关联标签指示所述文本对中文本的语义相似程度,所述重要标签指示所述文本对中的文本词在其所属文本中的重要程度;
9、预测单元,用于通过预设文本匹配模型对所述文本对分别进行语义相似度预测和文本词重要性预测,得到所述文本对中文本之间的相似度信息,以及所述文本对中文本词的重要程度预测概率;
10、计算单元,用于基于所述相似度信息和所述文本对关联标签,计算所述预设文本匹配模型对应的第一语义匹配损失,以及基于所述重要标签和所述重要程度预测概率,计算所述预设文本匹配模型对应的第二语义匹配损失;
11、训练单元,用于根据所述第一语义匹配损失以及所述第二语义匹配损失,对所述预设文本匹配模型进行模型训练处理,得到训练好的文本匹配模型,所述训练好的文本匹配模型用于对待识别文本对进行文本匹配处理。
12、在一实施例中,所述计算单元,包括:
13、文本对组合构建子单元,用于在所述文本对中构建文本对组合,所述文本对组合中文本对具有不同的文本对关联标签;
14、相似度差值计算子单元,用于基于所述文本对关联标签,计算所述文本对组合中文本对的相似度信息之间的相似度差值;
15、第一语义匹配损失计算子单元,用于根据所述相似度差值确定所述预设文本匹配模型对应的第一语义匹配损失。
16、在一实施例中,所述文本对关联标签包括多个语义相似程度等级的关联标签,所述文本对组合构建子单元,用于:
17、基于所述文本对关联标签中多个语义相似程度等级的关联标签,将所述文本对划分为每一语义相似程度等级对应的文本对集合;
18、在任意两个文本对集合中确定出文本对,并将确定出的文本对构建为文本对组合;
19、所述相似度差值计算子单元,用于:
20、根据所述关联标签对应的语义相似程度等级,在所述文本对组合中确定出第一文本对以及第二文本对,所述第一文本对的语义相似程度等级小于所述第二文本对;
21、将所述第一文本对的相似度信息减去所述第二文本对的相似度信息,得到所述文本对组合中文本对的相似度信息之间的相似度差值。
22、在一实施例中,所述多个语义相似程度等级的关联标签包括同义文本对标签、上下位关系文本对标签、意图相关文本对标签以及无关文本对标签。
23、在一实施例中,所述计算单元,包括:
24、概率分布确定子单元,用于基于所述重要标签和所述重要程度预测概率,确定所述文本对中每一文本对应的真实重要程度概率分布以及预测重要程度概率分布;
25、重要程度差异信息计算子单元,用于计算真实重要程度概率分布以及预测重要程度概率分布之间的重要程度差异信息;
26、差异累加子单元,用于将所述文本对对应的重要程度预测差异信息进行累加处理,得到所述预设文本匹配模型对应的第二语义匹配损失。
27、在一实施例中,所述文本匹配装置,还包括:
28、文本增强单元,用于基于所述重要标签对所述文本对中文本进行增强处理,得到增强后文本对;
29、文本对确定单元,用于基于所述增强后文本对和所述文本样本对中文本对,确定用于预设文本匹配模型处理的文本对。
30、在一实施例中,所述文本增强单元,用于:
31、对所述文本对中文本的文本词进行顺序调节,得到增强后文本对;
32、或者;
33、基于所述重要标签,在所述文本对的文本词中确定出非核心文本词;
34、在所述文本对中对所述非核心文本词进行随机删除,得到增强后文本对。
35、此外,本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有多条指令,所述指令适于处理器进行加载,以执行本技术实施例所提供的任一种文本匹配方法中的步骤。
36、此外,本技术实施例还提供一种计算机设备,包括处理器和存储器,所述存储器存储有应用程序,所述处理器用于运行所述存储器内的应用程序实现本技术实施例提供的文本匹配方法。
37、本技术实施例还提供一种计算机程序产品或计算机程序,所述计算机程序产品或计算机程序包括计算机指令,所述计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取所述计算机指令,处理器执行所述计算机指令,使得所述计算机设备执行本技术实施例提供的文本匹配方法中的步骤。
38、本技术实施例通过获取文本样本对,文本样本对包括文本对、文本对的文本对关联标签以及文本对中文本词的重要标签,文本对关联标签指示文本对中文本的语义相似程度,重要标签指示文本对中的文本词在其所属文本中的重要程度;通过预设文本匹配模型对文本对分别进行语义相似度预测和文本词重要性预测,得到文本对中文本之间的相似度信息,以及文本对中文本词的重要程度预测概率;基于相似度信息和文本对关联标签,计算预设文本匹配模型对应的第一语义匹配损失,以及基于重要标签和重要程度预测概率,计算预设文本匹配模型对应的第二语义匹配损失;根据第一语义匹配损失以及第二语义匹配损失,对预设文本匹配模型进行模型训练处理,得到训练好的文本匹配模型,训练好的文本匹配模型用于对待识别文本对进行文本匹配处理。以此,通过预设文本匹配模型对文本对进行语义相似度预测和文本词重要性预测,从而根据文本对关联标签和语义相似度预测任务得到的相似度信息,计算预设文本匹配模型对应的第一语义匹配损失,以及根据重要标签和文本词重要性预测任务预测得到的重要程度预测概率,计算预设文本匹配模型对应的第二语义匹配损失,根据第一语义匹配损失和第二语义匹配损失对预设文本匹配模型进行模型训练处理,可以加强预设文本匹配模型对文本中重要词的语义的捕捉能力,进而在文本匹配时可以考虑文本的整体语义以及文本中重要词的语义,从而可以更加准确的获取到文本语义进行文本匹配处理,提高文本匹配的准确性。
- 还没有人留言评论。精彩留言会获得点赞!