一种自动弹性伸缩的AI运行时装置的制作方法
本申请涉及一种ai运行时装置,具体是一种自动弹性伸缩的ai运行时装置,属于ai应用服务。
背景技术:
1、在ai应用发展至今日,尤其是aigc应用的快速发展中,gpu资源的不足成为了影响应用性能和部署效果的瓶颈之一,传统的gpu计算方式需要在特定服务器上预配置,运行较为僵化,不便于应用的弹性伸缩和部署,同时,gpu资源价格的高昂也给企业带来了沉重的负担,限制了许多创新应用的发展。
2、另外,在ai应用的发展中,高并发度、内容安全等也成为了ai应用开发者和用户所关注的重点。实现高可用的ai应用构建需要极专业的知识和技能,但很多企业和开发者并不具备这些技术能力和经验,传统的银行卡充值方式多数较为单一,影响人们的使用体验,同时在银行卡丢失后多数难以预防内部的财产丢失,存在一定的安全隐患,同时在银行卡丢失后也缺乏一定的应变手段。
3、当前ai模型或应用托管平台大多采用传统的基于虚拟机(vm)或容器的云计算架构,实现ai训练或推理应用的托管和运行。这些平台需要提前预留计算、存储等各种资源,且需要大量运维人员来进行平台管理和维护。同时,这些平台的计费模式大多是基于虚拟机或容器的数量和时长计费,导致成本较高。详细的已有技术实现ai应用构建和托管的原理大致如下:
4、docker容器技术:使用docker容器技术可以将应用程序和其所需要的依赖项(如库、依赖包等)封装为一个独立的容器,从而实现应用程序的可移植性和隔离性。docker容器化技术通常被用于实现ai应用的构建和托管。
5、kubernetes集群技术:使用kubernetes集群技术可以管理和自动化部署多个docker容器,以实现高可用性和弹性的ai应用部署。
6、云计算平台(特指云主机架构,即便是阿里云pai等也是将模型等直接部署到gpu云服务器):云计算平台提供了一种可扩展的部署解决方案,使得应用程序的资源管理和托管更加简单。
7、以上技术的融合可以实现较为全面和高效的ai应用构建和托管,但需要专业的技术人员进行配置和管理,对一些中小型企业和开发者来说较为困难,现有传统构架部署和维护难度大;gpu资源不足、成本高昂;并发量大导致性能下降和排队、限流、内容安全等能力不足。因此,针对上述问题提出一种基于serverless架构实现的ai应用平台解决方案,具有更低的部署和维护难度、更高的效率和性能、更多的可扩展性、更好的排队、限流和内容安全能力等优势,对其它传统架构的ai应用平台有着极大的优化和提升的自动弹性伸缩的ai运行时装置。
技术实现思路
1、本申请的目的就在于为了解决上述问题而提供一种自动弹性伸缩的ai运行时装置。
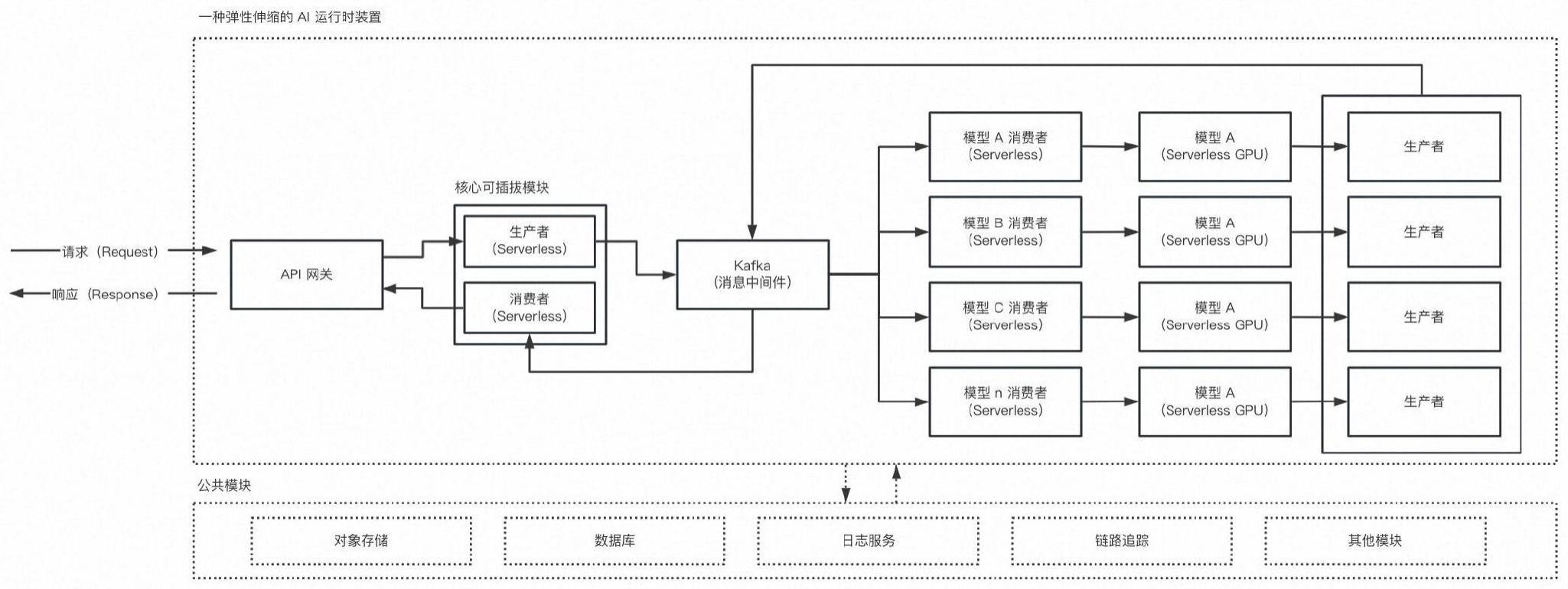
2、本申请通过以下技术方案来实现上述目的,一种自动弹性伸缩的ai运行时装置,包括api网关、核心可插拔模块、kafka消息中间件、模型推理模块和公共模块;所述api网关与客户端同步或异步连接,所述api网关通过核心可插拔模块与kafka消息中间件连接,且所述kafka消息中间件与模型推力模块连接,且所述api网关、核心可插拔模块、kafka消息中间件和模型推理模块都与公共模块连接,所述公共模块包括对象存储单元、数据库单元、日志服务单元、链路追踪和其它模块单元。
3、进一步的,所述api网关过滤流量后与核心可插拔模块连接,所述api网关用于接收请求和做出响应,且所述api网关还包括鉴权等相关能力。
4、进一步的,所述核心可插拔模块包括内容安全、排队、限流等模块的动态插拔,所述心可插拔模块通过将筛选的数据以事件形式投递到下游kafka消息中间件。
5、进一步的,所述核心可插拔模块包括生产者单元、内容安全单元和其他模块单元,所述生产者单元由serverless架构组成,且所述核心可插拔模块分别与api网关可kafka消息中间件双向连通。
6、进一步的,所述模型推理模块用于对已存在kafka中的任务进行穿行处理,包括单卡串行和多卡并行,所述模型推理模块包括消费者模块、模型处理模块以及生产者模块的结果的投递。
7、进一步的,所述ai运行时装置包括操作系统和基础环境,如ubuntu+python3.8。
8、进一步的,所述ai运行时装置包括基于serverless架构的ai应用平台、ai应用构建插件、开发者上传ai模型及其代码、自动伸缩和按量付费资源管理、ai应用构建插件的自动集成和ai模型的上线及openapi的开放。
9、进一步的,所述serverless架构还具有自动伸缩和按量付费等特点。
10、进一步的,所述ai应用构建插件包括自动集成功能,所述开发者上传ai模型及其代码包括文件或者数据库的配置,根据客户端传递的具体需求,进行对应的模型匹配和业务逻辑的加载。
11、进一步的,所述ai模型的上线及openapi的开放使用openapi对外暴露ai应用接口,从而能够将ai技术奉献给更多的开发者和用户。
12、本申请的有益效果是:本申请解决了传统架构下ai应用部署和维护难度大的问题,用户只需要上传ai模型和基础业务逻辑就可以获得部署好的应用,从而方便了用户的使用和管理,提供了gpu资源的自动弹性伸缩,用户只需根据实际需求分配gpu资源,避免了gpu资源浪费和高成本问题,基于本申请的serverless架构的ai应用平台天然集成了弹性伸缩的特性,能够快速响应客户需求,且能够保证高效稳定的性能,从而解决了传统架构下因为高并发导致的性能下降的问题,且提供插件思路,使得ai应用平台具备排队、限流、内容安全等能力,在ai应用中,可以最大化地发挥异步排队的特性,通过整合这些功能,本申请平台能够为用户提供更好的服务质量,防止恶意用户攻击和非节点合理占用等情况。
技术特征:
1.一种自动弹性伸缩的ai运行时装置,包括api网关、核心可插拔模块、kafka消息中间件、模型推理模块和公共模块;所述api网关与客户端同步或异步连接,所述api网关通过核心可插拔模块与kafka消息中间件连接,且所述kafka消息中间件与模型推力模块连接,且所述api网关、核心可插拔模块、kafka消息中间件和模型推理模块都与公共模块连接,所述公共模块包括对象存储单元、数据库单元、日志服务单元、链路追踪和其它模块单元。
2.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述api网关过滤流量后与核心可插拔模块连接,所述api网关用于接收请求和做出响应,且所述api网关还包括鉴权等相关能力。
3.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述核心可插拔模块包括内容安全、排队、限流等模块的动态插拔,所述心可插拔模块通过将筛选的数据以事件形式投递到下游kafka消息中间件。
4.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述核心可插拔模块包括生产者单元、内容安全单元和其他模块单元,所述生产者单元由serverless架构组成,且所述核心可插拔模块分别与api网关可kafka消息中间件双向连通。
5.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述模型推理模块用于对已存在kafka中的任务进行穿行处理,包括单卡串行和多卡并行,所述模型推理模块包括消费者模块、模型处理模块以及生产者模块的结果的投递。
6.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述ai运行时装置包括操作系统和基础环境,如ubuntu+python3.8。
7.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述ai运行时装置包括基于serverless架构的ai应用平台、ai应用构建插件、开发者上传ai模型及其代码、自动伸缩和按量付费资源管理、ai应用构建插件的自动集成和ai模型的上线及openapi的开放。
8.根据权利要求7所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述serverless架构还具有自动伸缩和按量付费等特点。
9.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述ai应用构建插件包括自动集成功能,所述开发者上传ai模型及其代码包括文件或者数据库的配置,根据客户端传递的具体需求,进行对应的模型匹配和业务逻辑的加载。
10.根据权利要求1所述的一种自动弹性伸缩的ai运行时装置,其特征在于:所述ai模型的上线及openapi的开放使用openapi对外暴露ai应用接口,从而能够将ai技术奉献给更多的开发者和用户。
技术总结
本申请公开了一种自动弹性伸缩的AI运行时装置,包括API网关、核心可插拔模块、Kafka消息中间件、模型推理模块和公共模块。本申请天然集成了弹性伸缩的特性,能够快速响应客户需求,且能够保证高效稳定的性能,从而解决了传统架构下因为高并发导致的性能下降的问题,且提供插件思路,使得AI应用平台具备排队、限流、内容安全等能力,在AI应用中,可以最大化地发挥异步排队的特性,通过整合这些功能,本申请平台能够为用户提供更好的服务质量,防止恶意用户攻击和非节点合理占用等情况,本申请具有较高技术实用性和商业价值,可以降低应用平台的部署和维护难度,节省了时间和人力成本,提高了效率,同时也有较强的商业化应用前景。
技术研发人员:刘宇,边江
受保护的技术使用者:刘宇
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!