一种融合语义信息行人流量计数方法
本发明属于机器视觉、视频图像处理,尤其涉及一种融合语义信息行人流量计数方法。
背景技术:
1、行人流量计数系统是一种用于统计行人数量和行人运动轨迹的系统,广泛应用于商场、公共交通、旅游景点等场所。其所需要的技术主要包含视频图像处理技术和深度学习技术。
2、视频图像处理技术:行人流量计数系统主要通过视频监控摄像头获取行人的图像信息,经过视频图像处理技术对图像进行预处理和分析,从而实现对行人的检测、跟踪和计数等功能。视觉算法中广泛应用的技术包括特征提取、目标检测、目标跟踪、运动估计等。
3、深度学习技术:为了提高行人检测和跟踪的准确率,行人流量计数系统使用了各种深度学习技术。常用的机器学习算法包括支持向量机、决策树、随机森林等;而深度学习算法则主要使用卷积神经网络(cnn)和循环神经网络(rnn)。这些技术不仅可以提高系统性能,还可以实现更多的功能,如姿态识别、性别识别、年龄识别等。
4、其中多目标跟踪技术是一个极其关键的环节,该技术根据目标检测后的结果,结合跟踪目标的特征相似度进行级联匹配,为每一个目标分配独有的id并生成目标轨迹。目标跟踪技术的应用存在诸多难题和挑战。大多传统方法仅对在目标检测中的到高置信度的检测框分配id,而将置信度低于阈值的检测框丢弃,这可能会导致真正的目标丢失和产生碎片化的轨迹。如何保留低置信度目标检测框恢复真实目标并过滤掉背景检测是当前急需解决的问题。
5、因此,本发明基于bytetrack提出了结合所有检测框并融合语义信息进行目标跟踪的行人流量计数方法。
技术实现思路
1、为解决上述技术问题,本发明提出一种融合语义信息行人流量计数方法,在目标检测框获得低置信度时也对其进行轨迹匹配操作,去除掉低置信度检测框中真正的背景信息,并根据准确的跟踪结果进行计数工作。
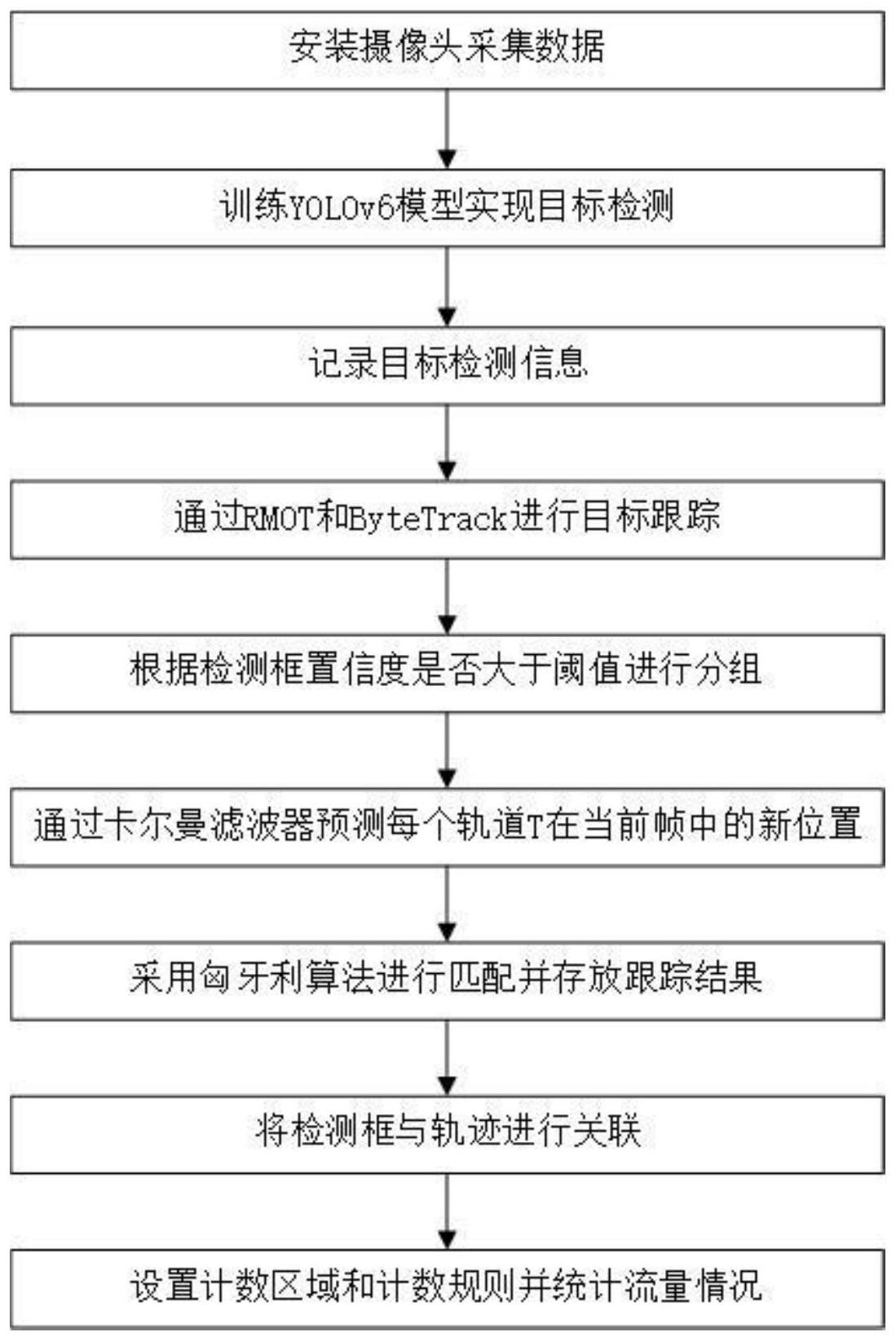
2、为实现上述目的本发明提出了一种融合语义信息行人流量计数方法,包括:
3、采集行人流量的数据信息;
4、对所述数据信息进行目标检测,并记录目标检测信息;
5、基于所述目标检测信息,通过rmot和bytetrack进行目标跟踪;
6、对目标跟踪结果进行阈值分组,并基于所述目标跟踪结果预测对目标在当前帧的位置进行预测,获取目标轨道;
7、将分组后的所述目标跟踪结果与所述目标轨道进行轨迹关联,基于关联结果进行计数。
8、可选地,对所述数据信息进行目标检测包括:
9、对包含目标的图像数据集进行标注;其中,标注内容包括:目标类别、边框位置和目标尺寸;
10、基于标注后的数据集对yolov6模型进行训练;
11、基于训练后的所述yolov6模型,进行目标检测。
12、可选地,记录所述目标检测信息包括:记录目标位置信息、目标尺寸信息和边界框置信度;
13、记录所述目标位置信息包括:记录目标的像素坐标、边界框位置和中心点位置;
14、记录所述目标尺寸信息包括:记录目标的宽度和高度;
15、记录所述边界框置信度包括:为检测到的每个目标分配一个边界框,并为每个边界框分配一个置信度得分。
16、可选地,通过rmot和bytetrack进行目标跟踪包括:
17、利用rmot进行目标跟踪,获取目标的位置和运动状态;在rmot中使用早期融合模块来整合可变形编码器层之前的视觉和语言特征,给定第i层特征图使用1×1卷积将其通道数减少到d=128,并将其展平为二维张量wi和hi分别为第i层特征图的宽和高;并使用全连接层将语言特征投影到中,三个独立的全连接层将视觉和语言特征转换为q、k和v:
18、
19、
20、
21、其中w是权重,pv和pl是视觉和语言特征的位置嵌入;
22、在k和v上做矩阵积,并使用生成的相似度矩阵对语言特征进行加权,即d为特征维数,然后将原始的视觉特征与语言特征相加,形成融合特征
23、
24、在融合两个模态后使用一堆可变形的编码器层来促进跨模态交互:
25、
26、其中编码为跨模态嵌入,便于后续解码器的引用预测;
27、设表示第t-1帧的解码器嵌入,利用自注意前馈网络将其进一步转化为第t帧的轨迹查询,即部分n解码器嵌入对应于空目标或退出的目标,因此过滤掉他们并仅保留n个真实嵌入,以根据其类分数生成跟踪查询令表示检测查询,该查询是为检测新出现目标而随机初始化;将这两种查询被连接在一起并输入到解码器中以学习目标表示dt:
28、
29、其中,输出嵌入次数为nt,包括跟踪对象和检测对象,得到目标的位置和运动状态;
30、将目标的位置和运动状态输入所述bytetrack,使用bytetrack算法对视频中的目标进行实时跟踪,以获得目标的位置和运动信息。
31、可选地,对目标跟踪结果进行阈值分组包括:
32、预设置信度阈值τ;
33、基于所述边界框置信度对所述数据信息中的每一帧所有的检测框进行划分,检测框的置信度大于等于阈值τ的,将检测框存入到高分检测框dhigh中,检测框的置信度小于阈值τ的,将检测框存入低分检测框dlow中。
34、可选地,对目标在当前帧的位置进行预测包括:
35、初始化:在跟踪开始时,为目标检测获得的每个目标轨道t初始化卡尔曼滤波器;其中,所述卡尔曼滤波器包括状态向量、状态转移矩阵、观测矩阵、协方差矩阵;其中,所述状态向量表示目标在当前帧的状态,包括位置、速度等信息;所述状态转移矩阵表示目标状态的演化规律;所述观测矩阵表示目标在当前帧的观测值;所述协方差矩阵表示状态向量和观测值的误差协方差;
36、预测:所述卡尔曼滤波器根据当前帧的所述状态向量和所述状态转移矩阵预测目标在下一帧的状态,并估计预测状态的所述协方差矩阵;
37、更新:在下一帧中,会观测到目标的位置,观测值用所述观测矩阵表示;卡尔曼滤波器会根据所述观测矩阵和观测值对预测状态进行修正,从而得到状态估计;
38、循环:在下一帧中,利用更新后的所述状态向量和所述状态转移矩阵对目标在下一帧的状态进行预测,并重复上述步骤直到跟踪结束。
39、可选地,将分组后的所述目标跟踪结果与所述目标轨道进行轨迹关联包括:
40、在所述高分检测框dhigh和所有轨道t之间进行第一次关联,并将不匹配的轨迹保留;
41、在所述低分检测框dlow和保留的不匹配的轨迹之间进行第二次关联;
42、基于两次关联结果完成所述轨迹关联。
43、可选地,在所述高分检测框dhigh和所有轨迹t之间进行第一次关联包括:
44、检测所述高分检测框dhigh和轨迹t的预测框之间的iou;
45、所述iou:
46、
47、其中,area_inter表示预测框与真实框的交集,area_union表示预测框与真实框的并集;
48、使用匈牙利算法根据所述iou,完成匹配,将不匹配的检测保留在dremain中,在tremain中保留不匹配的轨迹。
49、可选地,在所述低分检测框dlow和保留的不匹配的轨迹之间进行第二次关联包括:
50、检测所述低分检测框dlow和保留的不匹配的轨迹的预测框之间的所述iou;
51、使用匈牙利算法根据所述iou,完成匹配,将仍然未匹配到检测框的轨迹保留在tre-remain中,对于tre-remain中的每个轨迹,当轨迹存在超过预设帧数时,从轨迹中删除,并删除仍未匹配到轨迹的低分检测框dlow。
52、与现有技术相比,本发明具有如下优点和技术效果:
53、1、通过使用rmot进行强大的跨模态学习,解决了现有引用理解任务中的限制,并提供了多对象和临时状态变化的环境。
54、2、为解决仅保留高分检测框而导致的不可忽略的真正目标缺失和轨迹碎片化的问题,使用bytetrack通过关联几乎所有的检测框来进行跟踪,而不是仅仅关联得分高的检测框,利用其与tracklet的相似性来恢复真实目标并过滤掉背景检测框。
- 还没有人留言评论。精彩留言会获得点赞!