一种基于音频控制的虚拟人生成方法、装置、设备及介质
本发明涉及图像处理,尤其是一种基于音频控制的虚拟人生成方法、装置、设备及介质。
背景技术:
1、虚拟人生成是一种基于音频和图像的视频生成技术,旨在通过音频和图像输入实时生成虚拟人的脸部表情,嘴型和手势等,使其能够以逼真的方式模拟人类的交流和行为。近年来,计算机视觉技术的迅猛发展为虚拟人的生成和应用提供了广阔的空间。虚拟人生成技术的应用潜力巨大。在娱乐领域,它可以应用于电影、游戏和虚拟主播等,使得虚拟角色能够根据语音输入实时生成精准的脸部表情和嘴型运动,增强角色的表现力和情感传递;在教育和培训领域,虚拟人生成技术可以用于虚拟教师,实现脸部表情和动作与说话内容的一致性,提供更加生动和引人入胜的教学体验。此外,虚拟人生成技术还可以应用于人机交互、虚拟现实和增强现实等领域,为用户提供更加自然和真实的交互体验。基于广泛的现实需求,如何生成生动逼真的虚拟人形象、实现更加真实的虚拟交互体验,是人工智能计算机视觉领域的长远目标。现有的虚拟人生成方式存在一定局限性,效率较低。
技术实现思路
1、有鉴于此,本发明实施例提供一种基于音频控制的虚拟人生成方法、装置、设备及介质,能够高效进行基于音频控制的虚拟人生成。
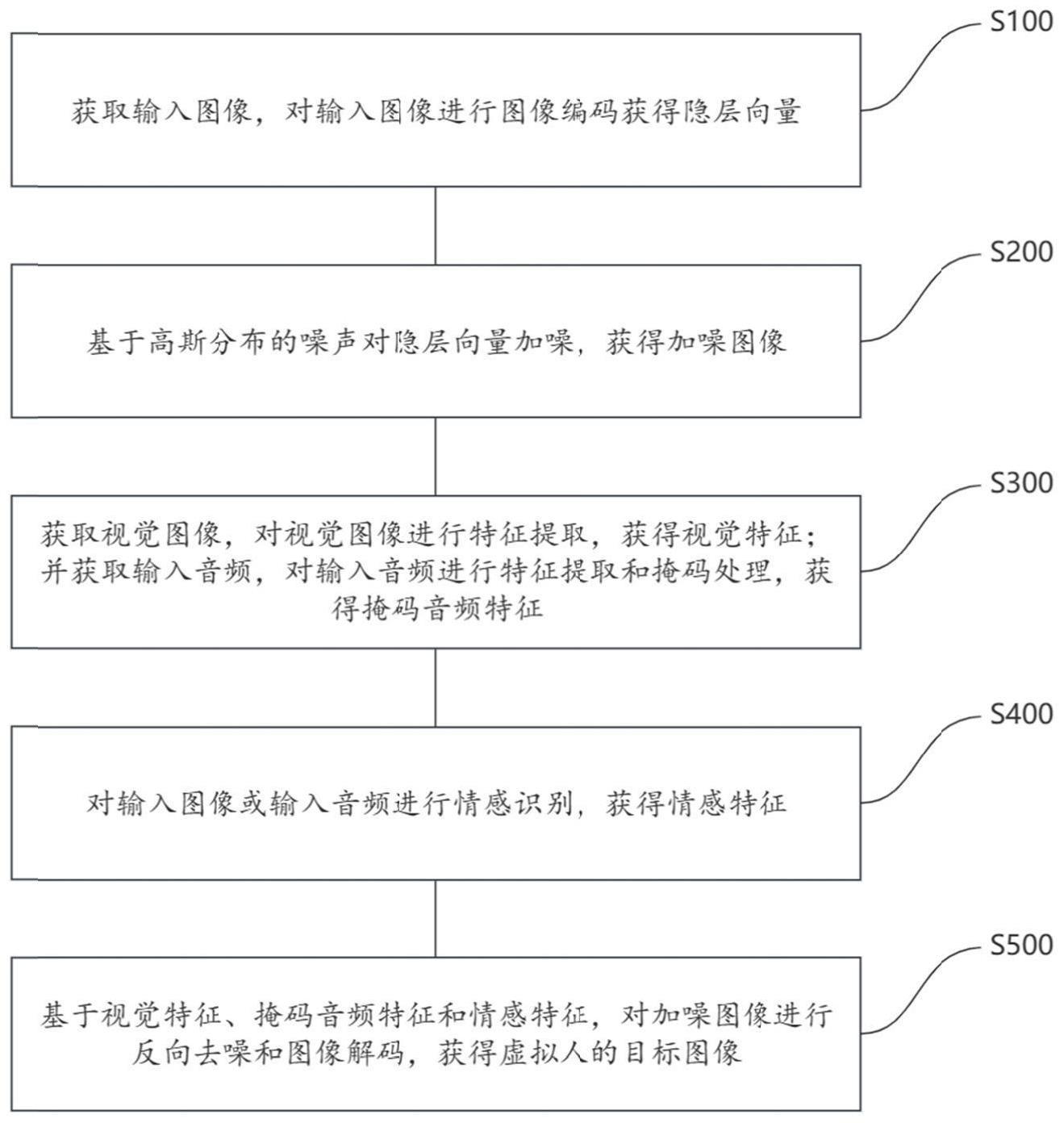
2、一方面,本发明的实施例提供了一种基于音频控制的虚拟人生成方法,包括:
3、获取输入图像,对输入图像进行图像编码获得隐层向量;
4、基于高斯分布的噪声对隐层向量加噪,获得加噪图像;
5、获取视觉图像,对视觉图像进行特征提取,获得视觉特征;并获取输入音频,对输入音频进行特征提取和掩码处理,获得掩码音频特征;
6、对输入图像或输入音频进行情感识别,获得情感特征;
7、基于视觉特征、掩码音频特征和情感特征,对加噪图像进行反向去噪和图像解码,获得虚拟人的目标图像。
8、可选地,对输入图像进行图像编码获得隐层向量,包括:
9、利用预训练的第一图像编码器将输入图像编码到隐层空间,获得隐层向量。
10、可选地,基于高斯分布的噪声对隐层向量加噪,获得加噪图像,包括:
11、在隐层空间对隐层向量进行前向扩散处理,基于预设的高斯分布,在隐层向量上加入来自高斯分布的噪声,获得加噪图像。
12、可选地,视觉图像包括姿态图像和纹理图像,视觉特征包括姿态特征和纹理特征;对视觉图像进行特征提取,获得视觉特征,包括:
13、利用预训练的第二图像编码器,对姿态图像进行特征提取,获得姿态特征;
14、利用预训练的第二图像编码器,对纹理图像进行特征提取,获得纹理特征;
15、其中,姿态特征用于虚拟人的身体姿态生成,纹理特征用于虚拟人的人脸纹理生成。
16、可选地,对输入音频进行特征提取和掩码处理,获得掩码音频特征,包括:
17、利用预训练的音频特征提取器,对输入音频进行特征提取,获得音频特征;
18、在音频特征上添加唇部掩码,获得掩码音频特征;
19、其中,掩码音频特征用于虚拟人的嘴型部分生成。
20、可选地,对输入图像或输入音频进行情感识别,获得情感特征,包括:
21、利用预训练的表情识别模型对输入图像或输入音频进行情感识别,获得情感特征;
22、其中,表情识别模型利用已标注情感标签的输入图像和基于输入图像得到的视频特征和音频特征,通过情感分类损失函数训练生成。
23、可选地,基于视觉特征、掩码音频特征和情感特征,对加噪图像进行反向去噪和图像解码,获得虚拟人的目标图像,包括:
24、将视觉特征、掩码音频特征和情感特征输入预训练的反向去噪模块,对加噪图像进行反向去噪;
25、其中,反向去噪模块包括若干u-net,每个u-net用于预测加噪图像在不同阶段去噪的向量,得到不同阶段预测的噪声图像;反向去噪模块基于噪声重构损失函数训练生成;
26、反向去噪的流程包括:
27、将视觉特征与不同阶段的噪声图像进行拼接,基于拼接特征生成虚拟人的身体姿态和人脸纹理;其中,每个阶段的u-net的输入为上一阶段的噪声图像与视觉特征的拼接特征;
28、将掩码音频特征输入到每个u-net,并与拼接特征进行注意力机制处理,生成虚拟人的嘴型部分,并得到多模态特征;
29、将情感特征输入到每个u-net,并与u-net的多模态特征进行特征融合,生成虚拟人的脸部,进而获得虚拟人的目标图像。
30、另一方面,本发明的实施例提供了一种基于音频控制的虚拟人生成装置,包括:
31、第一模块,用于获取输入图像,对输入图像进行图像编码获得隐层向量;
32、第二模块,用于基于高斯分布的噪声对隐层向量加噪,获得加噪图像;
33、第三模块,用于获取视觉图像,对视觉图像进行特征提取,获得视觉特征;并获取输入音频,对输入音频进行特征提取和掩码处理,获得掩码音频特征;
34、第四模块,用于对输入图像或输入音频进行情感识别,获得情感特征;
35、第五模块,用于基于视觉特征、掩码音频特征和情感特征,对加噪图像进行反向去噪和图像解码,获得虚拟人的目标图像。
36、另一方面,本发明的实施例提供了一种电子设备,包括处理器以及存储器;
37、存储器用于存储程序;
38、处理器执行程序实现如前面的方法。
39、另一方面,本发明的实施例提供了一种计算机可读存储介质,存储介质存储有程序,程序被处理器执行实现如前面的方法。
40、本发明实施例还公开了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器可以从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行前面的方法。
41、本发明实施例首先获取输入图像,对输入图像进行图像编码获得隐层向量;基于高斯分布的噪声对隐层向量加噪,获得加噪图像;获取视觉图像,对视觉图像进行特征提取,获得视觉特征;并获取输入音频,对输入音频进行特征提取和掩码处理,获得掩码音频特征;对输入图像或输入音频进行情感识别,获得情感特征;基于视觉特征、掩码音频特征和情感特征,对加噪图像进行反向去噪和图像解码,获得虚拟人的目标图像。本发明实施例通过从高斯分布采样的噪声,利用反向去噪对高斯噪声进行去噪,将去噪的隐层向量用图像的解码器进行解码,得到最终的图像;通过将视觉特征和掩码音频特征融合,增强了对特征信息的建模能力;并且在反向去噪过程中引入了情感特征引导的语义建模,成功提高了半身虚拟人生成的质量,有效解决了现有的虚拟人生成方法仅限于脸部建模的局限性。本发明实施例能够高效实现基于音频控制的虚拟人生成。
技术特征:
1.一种基于音频控制的虚拟人生成方法,其特征在于,包括:
2.根据权利要求1所述的一种基于音频控制的虚拟人生成方法,其特征在于,所述对所述输入图像进行图像编码获得隐层向量,包括:
3.根据权利要求2所述的一种基于音频控制的虚拟人生成方法,其特征在于,所述基于高斯分布的噪声对所述隐层向量加噪,获得加噪图像,包括:
4.根据权利要求1所述的一种基于音频控制的虚拟人生成方法,其特征在于,所述视觉图像包括姿态图像和纹理图像,所述视觉特征包括姿态特征和纹理特征;所述对所述视觉图像进行特征提取,获得视觉特征,包括:
5.根据权利要求1所述的一种基于音频控制的虚拟人生成方法,其特征在于,所述对所述输入音频进行特征提取和掩码处理,获得掩码音频特征,包括:
6.根据权利要求1所述的一种基于音频控制的虚拟人生成方法,其特征在于,所述对所述输入图像或所述输入音频进行情感识别,获得情感特征,包括:
7.根据权利要求1所述的一种基于音频控制的虚拟人生成方法,其特征在于,所述基于所述视觉特征、所述掩码音频特征和所述情感特征,对所述加噪图像进行反向去噪和图像解码,获得虚拟人的目标图像,包括:
8.一种基于音频控制的虚拟人生成装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括处理器以及存储器;
10.一种计算机可读存储介质,其特征在于,所述存储介质存储有程序,所述程序被处理器执行实现如权利要求1至7中任一项所述的方法。
技术总结
本发明公开了一种基于音频控制的虚拟人生成方法、装置、设备及介质,方法包括:获取输入图像,对输入图像进行图像编码获得隐层向量;基于高斯分布的噪声对隐层向量加噪,获得加噪图像;获取视觉图像,对视觉图像进行特征提取,获得视觉特征;并获取输入音频,对输入音频进行特征提取和掩码处理,获得掩码音频特征;对输入图像或输入音频进行情感识别,获得情感特征;基于视觉特征、掩码音频特征和情感特征,对加噪图像进行反向去噪和图像解码,获得虚拟人的目标图像。本发明能够有效解决现有的虚拟人生成方法仅限于脸部建模的局限性,高效实现基于音频控制的虚拟人生成,可广泛应用于图像处理技术领域。
技术研发人员:林洛阳,梁小丹,操晓春,陈定纬
受保护的技术使用者:中山大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!