基于图在线哈希模型的图像检索方法
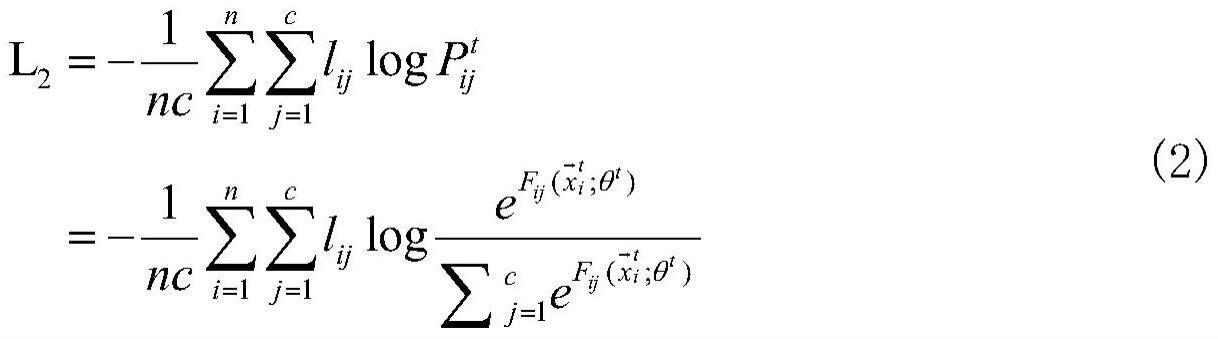
本发明属于图像检索,具体涉及一种基于图在线哈希模型的图像检索方法。
背景技术:
1、在线哈希以流式方式进行大规模图像检索引起了很多研究关注。许多研究人员旨在保持检索准确性和哈希函数更新效率之间的平衡。因此,由于哈希函数更新成本高,几乎所有的在线哈希方法都基于浅层模型而不是深度网络,在线案例中需要考虑这一点。此外,现有的在线哈希方法将整个哈希过程分为两个相互独立的部分:特征提取和哈希函数更新,这限制了高判别性哈希码的生成。
2、随着图像数据的爆炸式增长,针对大规模数据的高效检索技术变得越来越迫切。哈希是最流行和最有效的策略之一,因为它通过将高维特征向量编码成一组紧凑的二进制代码来实现查询速度快和存储成本低。传统的哈希方法主要是从固定的训练数据集学习哈希函数。显然,当数据库的数据越来越多时,训练数据集变得非常庞大。结果,计算和内存的训练成本会很高,从而导致效率低下。在许多实际应用场景中,图像数据通常是周期性或随时间流式采集的,目标数据需要在短时间内或实时检索。但是,在离线哈希的设置下,无法处理这种动态场景。
3、因此,在线哈希最近受到了广泛的研究关注。这些方法通过一次处理一个块的数据以在线方式学习哈希函数。通过训练新到达的数据,他们逐渐更新哈希模型以适应数据流的变化,并将新数据编码成哈希码。由于哈希模型仅由当前数据块更新,所以计算和内存成本远低于基于批处理的哈希。这些方法也能够以低成本有效地处理流数据和大规模数据集。
4、理想情况下,在线哈希应该能够根据新数据动态学习哈希函数。现有的在线哈希算法可以分为有监督的和无监督的。无监督在线哈希主要考虑数据固有属性的分布和方差来分析数据之间的相似程度。主要思想来自数据草图策略。一个例子是在线草图哈希,它使用较小的草图矩阵来存储数据的主要特征,并通过最大化草图矩阵中每个哈希位的方差并采用矩阵分解来学习哈希函数。快速在线草图哈希(frosh)通过使用二次抽样随机阿达玛变换的方法加快了矩阵分解的过程和学习速度。与无监督方法相比,有监督方法可以通过使用语义标签信息获得更好的性能。huang等人提出的在线核哈希算法首次利用对数据设计损失提出了基于被动攻击策略的哈希函数在线学习方法。自适应哈希(adapthash)利用相似性信息进行随机梯度下降,找到适应数据变化的哈希函数。损失函数用于减小相似对之间的汉明距离并扩大不同对之间的汉明距离。cakir等人提出了一个两步哈希框架,在线监督哈希(osh),引入了纠错输出码(ecoc)来表示每个新类别。然后使用增强学习哈希函数来拟合二进制ecoc。互信息哈希提出了一种具有互信息的在线哈希方法,旨在分离汉明空间中相似和不相似数据的分布。为了解决“数据不平衡”问题,在在线离散哈希(bsodh)中引入了平衡因子,解决新旧类型数据、同异数据不平衡的问题在训练过程中调整。lin等人提出了一种基于hadamard码本(hcoh)的在线哈希方法,可以离线生成判别码本,也可以缓解在线学习带来的不稳定性。快速类更新在线哈希首先开发了一种基于类的更新方案,该方法以更少的训练数据和存储消耗实现更好的性能。解决了现有在线哈希方法普遍存在的在线适应性差、训练效率低的问题。
5、然而,几乎所有的在线哈希方法都是基于浅层模型而不是深层网络,这是由于哈希函数更新成本较高,这需要在在线情况下加以考虑。
技术实现思路
1、本发明的目的是提供一种基于图在线哈希模型的图像检索方法,以弥补现有技术的不足。
2、本发明提出了一种新的基于图神经网络的监督在线哈希方法,一方面,将每幅图像分成多个小块作为节点,采用视觉图形神经网络模型来提取图像特征;此外,将每张图像作为节点输入到图在线哈希模型中,通过学习相邻节点的聚合表示函数,构建gnn哈希模型来生成目标节点的特征向量;再设计由相似保持损失、分类损失和知识保持损失组成的目标函数,学习到具有强大语义表示能力的紧凑哈希码用于图像检索。
3、为达到上述目的,本发明采取的具体技术方案为:
4、一种基于图在线哈希模型的图像检索方法,包括以下步骤:
5、s1:首先获取原始图像及其对应的标签向量;
6、s2:提取原始图像特征:将原始图像划分为多个块,通过预训练好的视觉图形神经网络模型(如vig模型)提取原始图像特征;
7、s3:构建图在线哈希模型,划分基础数据库并构建图结构,使用基础数据库训练该图在线哈希模型;
8、s4:在每个阶段,采样旧图像数据和新图像数据构建图结构;
9、s5:将s4构建的图结构输入到所述图在线哈希模型中,训练该模型,根据目标函数对哈希函数进行更新;
10、s6:将训练后的流数据块及其对应哈希码更新旧数据库;
11、s7:返回s4步骤,直到所有数据块训练完成,即完成了对图在线哈希模型的训练;
12、s8:基于训练好的图在线哈希模型,输入检索需求,输出检索结果,完成图像数据检索。
13、进一步的,所述s3具体为:
14、s3-1:构建图在线哈希模型:该模型结构包括两层聚合层,两层全连接层,一层哈希层;每个图像数据被看作节点,对节点做聚合时,先使用两层聚合函数对其邻居节点的特征做聚合得到特征向量,再输入两个全连接层和一层哈希层得到每个节点的哈希码;
15、s3-2:在图像数据中随机划分出基础数据库,根据标签信息构建图结构,即每个图像数据被看作节点,如果两个图像数据之间有公共标签则用一条无向边连接起来;此外,采用小批量的训练方式,每个小批量的大小为n;为了有效的初步训练网络模型,定义为内积最小化问题,同时添加量化误差:
16、
17、其中,f(·)表示要学习的哈希函数,表示第t阶段的i个新图像特征,θt表示第t阶段的学习的网络模型参数,表示第t阶段的j个新图像对应的哈希码,k代表哈希码长度,s表示图像数据之间的相似度矩阵,λ0为权重参数,||·||f为f范数;公式(1)的目的是保持原始空间的相似性;为了学习出更具语义性的哈希码,还使用了分类损失:
18、
19、其中,c代表类别数量,l表示数据对应的标签向量,由{0,1}组成。
20、进一步的,所述s4中:在第t阶段新数据到达时,从现有数据块中以适当的比例对图像数据进行采样,以保持对旧数据的理解;新的图像数据和对应于采样图像的信息被用于训练模型;在这个阶段,只学习新数据块的哈希码,旧数据的现有哈希码不变;类似地,标签信息用于构建图形结构;构建方法与s3中相同,使用第一阶段中的相似性保持损失和分类损失作为目标函数的一部分;为了避免灾难性的遗忘问题,新旧哈希码的内积应该尽可能接近对应图像的语义相似度:
21、
22、其中,m表示来自基础数据库的采样数据的大小,代表旧数据第t阶段之前的j个旧图像对应的哈希码。
23、进一步的,所述s5中:
24、s5-1:首先划分基础数据库,将构建好的图结构输入到模型中的聚合层,得到聚合后的特征映射,再经过两层全连接层和一层哈希层得到对应的二值哈希码;为了学习出更具语义性的哈希函数,使用标签信息构建的相似度矩阵来保持原始空间的相似性,同时加入分类损失加强对哈希码的学习;对于基础数据库训练的目标函数为:
25、
26、其中,λ1,λ2分别为权重参数;
27、s5-2:当有新的流数据出现时,采样部分旧数据与新数据构建图结构,并输入到模型中的聚合层,得到聚合后的特征映射,再经过两层全连接层和一层哈希层得到对应的二值哈希码,学习新的流数据对应的哈希码,旧数据的现有哈希码不变;为了学习出更具语义性的哈希函数,使用标签信息构建的相似度矩阵来保持新数据之间原始空间的相似性以及新旧数据原始空间的相似性,同时加入分类损失加强对哈希码的学习;对于流数据训练的目标函数为:
28、
29、其中,λ3为权重参数。
30、进一步的,所述s6中:在当前阶段训练完成后,得到的哈希码及其标签会被保存到旧数据库中,为后续训练采样使用。
31、进一步的,所述s8中:
32、s8-1:当有查询数据xq出现时,使用余弦距离作为度量,选择k个最接近的节点作为其邻居,并且在它们之间添加无向边来构建图;通过当前阶段训练好的网络模型对查询数据进行哈希编码:
33、bq=sign(f(xq;θt)) (6)
34、其中,bq表示查询数据对应的哈希码;
35、s8-2:通过计算查询和数据库之间的哈希代码的汉明距离来度量相似性;
36、s8-3:被认为相似的实例作为搜索结果返回。
37、本发明的优点和技术效果:
38、本发明通过构造视觉gnn和图在线哈希模型来同时提取图像特征和更新哈希函数;还通过聚合扩展到样本外图像,以确保灵活性;本发明综合考虑了相似性矩阵和分类损失,构造了一个综合损失函数,使得哈希码更具区分性。本发明真正实现了深度在线哈希的方法,利用深度网络能够挖掘更具语义性特征的优势,极大地提高了针对图像流数据的在线检索精度。
39、实验结果表明,在两个基准数据集上,利用本发明,图像数据的在线查询精度显著提高。
- 还没有人留言评论。精彩留言会获得点赞!