面向联邦学习的博弈驱动隐私自适应定价方法和装置
本发明涉及网络安全,尤其涉及一种面向联邦学习的博弈驱动隐私自适应定价方法和装置。
背景技术:
1、由于在联邦学习中,进行本地训练的客户不可避免地承担了计算和通信开销以及本地数据隐私泄露的风险。在联邦学习的过程中,为了激励客户积极地参与联邦学习,许多研究人员设计相应的激励机制来提高客户参与模型训练的积极性。
2、然而,现有的激励机制只考虑到客户在联合学习产生的的训练成本和通信成本,客户在联合学习中个人隐私泄露风险并没有得到补偿。
技术实现思路
1、本发明提供一种面向联邦学习的博弈驱动隐私自适应定价方法和装置,用以解决现有技术联邦学习激励机制只考虑到客户在联合学习产生的的训练成本和通信成本,导致客户在联合学习中个人隐私泄露风险并没有得到补偿的缺陷,分别通过选择服务器总隐私支付和客户个人隐私预算,最大化自身效用,平衡客户隐私和模型性能。
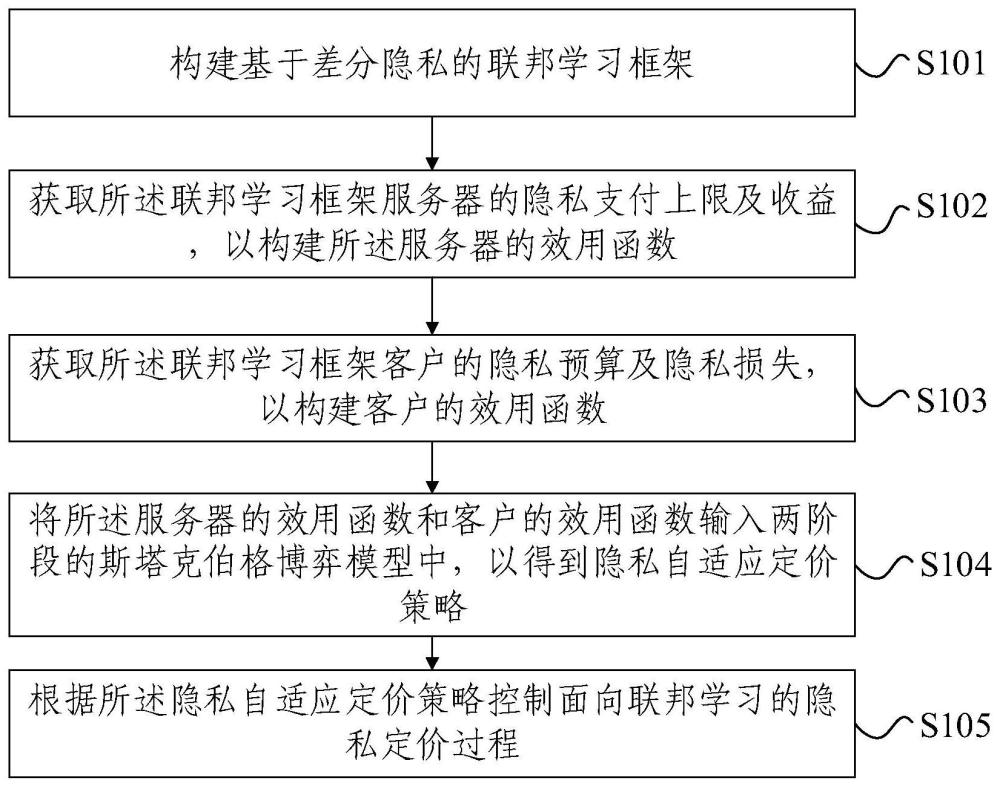
2、本发明提供一种面向联邦学习的博弈驱动隐私自适应定价方法,包括:
3、构建基于差分隐私的联邦学习框架;
4、获取所述联邦学习框架服务器的隐私支付上限及收益,以构建所述服务器的效用函数;
5、获取所述联邦学习框架客户的隐私预算及隐私损失,以构建客户的效用函数;
6、将所述服务器的效用函数和客户的效用函数输入两阶段的斯塔克伯格博弈模型中,以得到隐私自适应定价策略;
7、根据所述隐私自适应定价策略控制面向联邦学习的隐私定价过程。
8、根据本发明提供的面向联邦学习的博弈驱动隐私自适应定价方法,所述差分隐私为高斯差分隐私。
9、根据本发明提供的面向联邦学习的博弈驱动隐私自适应定价方法,所述将所述服务器的效用函数和客户的效用函数输入两阶段的斯塔克伯格博弈模型中,以得到隐私自适应定价策略,包括:
10、s31、求解服务器的效用函数最大值及该条件下支付上限的值,将该条件下支付上限的值减去客户隐私损失,得到客户的隐私预算;
11、s32、基于s31得到的支付上限和客户的隐私预算,在支付上限一定时,求解客户效用函数的最大值时客户的隐私预算。
12、根据本发明提供的面向联邦学习的博弈驱动隐私自适应定价方法,所述获取所述联邦学习框架服务器的隐私支付上限及收益,以构建所述服务器的效用函数,包括:
13、s41、所述服务器的支付上限为b,则服务器向客户ci支付的报酬表示为:
14、
15、其中,∈i是客户ci向服务器提交的预期隐私预算,代表了客户ci期望达到的隐私保护级别;
16、s42、在所述基于差分隐私的联邦学习框架中,将服务器的收益es表示为全局模型的收益f(∈g),即:
17、
18、其中,为全局模型的平均隐私预算,α,β>0是模型收益函数的系数,n为参加联邦学习的客户数量,∈i是客户ci向服务器提交的预期隐私预算,代表了客户ci期望达到的隐私保护级别;
19、s43、将服务器对客户隐私的总支付作为服务器的成本,定义为:
20、
21、其中,为服务器向客户ci支付的报酬,b为服务器的支付上限。
22、s44、服务器的效用函数us表示为:
23、
24、根据本发明提供的面向联邦学习的博弈驱动隐私自适应定价方法,所述获取所述联邦学习框架客户的隐私预算及隐私损失,以构建客户的效用函数,包括:
25、s51、客户ci的收益ec,i为服务器对其上报隐私预算支付的报酬pi,即:
26、
27、s52、客户ci的成本为客户参与联邦学习的隐私损失,表示为:
28、cc,i=ρi∈i
29、其中,ρi>0是客户成本参数,用于描述客户单位隐私预算的隐私损失;
30、s53、客户ci的效用函数uc,i定义为:
31、
32、本发明还提供一种面向联邦学习的博弈驱动隐私自适应定价装置,包括:
33、联邦学习框架构建模块,用于构建基于差分隐私的联邦学习框架;
34、服务器效用函数构建模块,用于获取所述联邦学习框架服务器的隐私支付上限及收益,以构建所述服务器的效用函数;
35、客户效用函数构建模块,用于获取所述联邦学习框架客户的隐私预算及隐私损失,以构建客户的效用函数;
36、隐私自适应定价策略输出模块,用于将所述服务器的效用函数和客户的效用函数输入两阶段的斯塔克伯格博弈模型中,以得到隐私自适应定价策略;
37、隐私定价过程控制模块,用于根据所述隐私自适应定价策略控制面向联邦学习的隐私定价过程。
38、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种面向联邦学习的博弈驱动隐私自适应定价方法。
39、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种面向联邦学习的博弈驱动隐私自适应定价方法。
40、本发明提供的面向联邦学习的博弈驱动隐私自适应定价方法和装置,通过构建博弈驱动隐私自适应定价下的联邦学习机制,保障客户的隐私安全,防止攻击者在梯度聚合、传输的过程中窃取梯度信息,还原客户隐私数据。本发明针对包含隐私的联邦学习中客户隐私和全局服务器性能相互制衡的问题,设计了面向联邦学习的博弈驱动隐私自适应定价方法,通过支付报酬的方式,补偿客户参与联邦学习承担的隐私泄漏风险,激励客户积极参与联合学习。同时,本发明还设计了客户和服务器的效用函数,让客户和服务器在优化各自效用的同时实现客户隐私和服务器性能的平衡。
技术特征:
1.一种面向联邦学习的博弈驱动隐私自适应定价方法,其特征在于,包括:
2.根据权利要求1所述的面向联邦学习的博弈驱动隐私自适应定价方法,其特征在于,所述差分隐私为高斯差分隐私。
3.根据权利要求1所述的面向联邦学习的博弈驱动隐私自适应定价方法,其特征在于,所述将所述服务器的效用函数和客户的效用函数输入两阶段的斯塔克伯格博弈模型中,以得到隐私自适应定价策略,包括:
4.根据权利要求1所述的面向联邦学习的博弈驱动隐私自适应定价方法,其特征在于,所述获取所述联邦学习框架服务器的隐私支付上限及收益,以构建所述服务器的效用函数,包括:
5.根据权利要求1所述的面向联邦学习的博弈驱动隐私自适应定价方法,其特征在于,所述获取所述联邦学习框架客户的隐私预算及隐私损失,以构建客户的效用函数,包括:
6.一种面向联邦学习的博弈驱动隐私自适应定价装置,其特征在于,包括:
7.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至5任一项所述面向联邦学习的博弈驱动隐私自适应定价方法。
8.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至5任一项所述面向联邦学习的博弈驱动隐私自适应定价方法。
技术总结
本发明提供一种面向联邦学习的博弈驱动隐私自适应定价方法和装置,方法包括:构建基于差分隐私的联邦学习框架;获取联邦学习框架服务器的隐私支付上限及收益,构建所述服务器的效用函数;获取所述联邦学习框架客户的隐私预算及隐私损失,构建客户的效用函数;将服务器的效用函数和客户的效用函数输入两阶段的斯塔克伯格博弈模型中,以得到隐私自适应定价策略;根据所述隐私自适应定价策略控制面向联邦学习的隐私定价过程。该方法可以最大化服务器和客户自身效用,平衡客户隐私和模型性能。本发明针对联邦学习中客户隐私和全局服务器性能相互制衡的问题,设计了客户和服务器的效用函数,通过优化效用函数来实现客户隐私和服务器性能的平衡。
技术研发人员:杨树杰,李鸿婧,周赞,许长桥
受保护的技术使用者:北京邮电大学
技术研发日:
技术公布日:2024/1/22
- 还没有人留言评论。精彩留言会获得点赞!