一种短文本相似性度量方法及系统
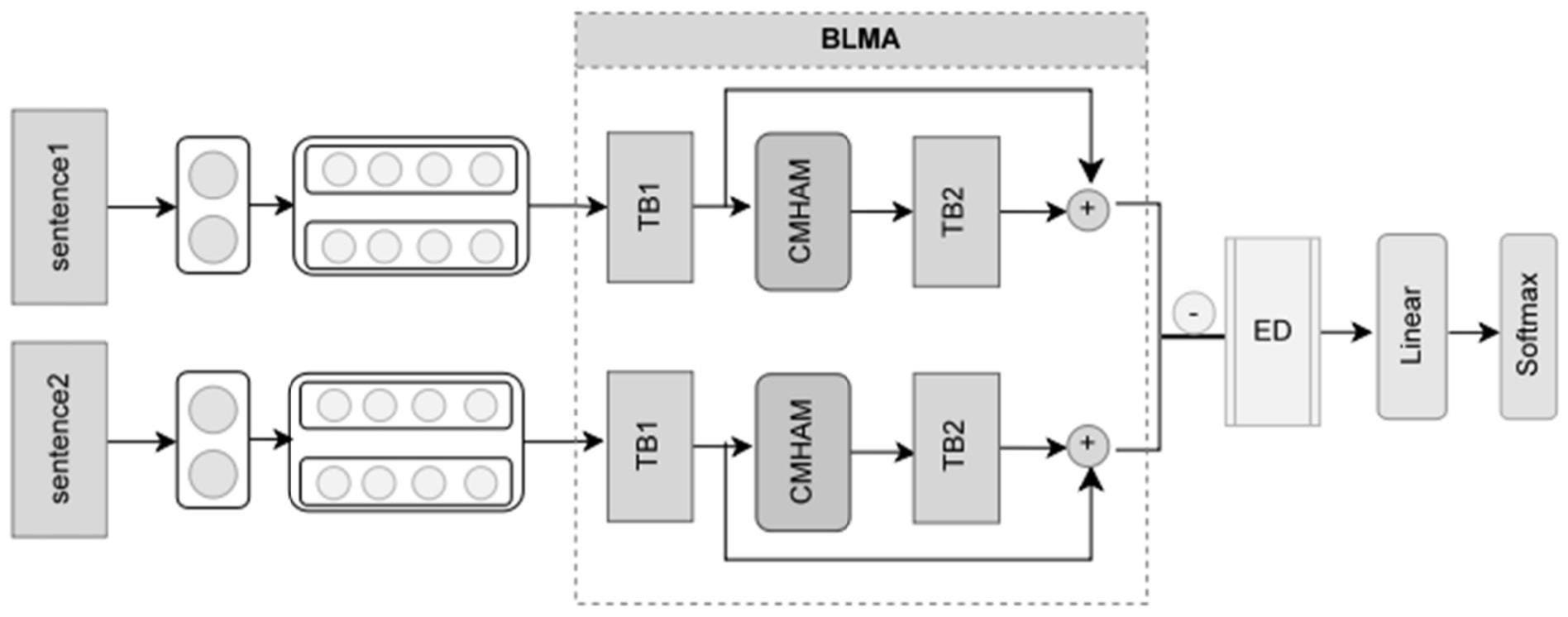
本公开涉及短文本挖掘分析,具体涉及一种短文本相似性度量方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
2、传统的短文本相似性计算技术通常为基于词袋模型和基于统计的方法。这些方法将文本表示为向量,并使用一些距离或相似性度量来计算文本之间的相似性。
3、其中,基于词袋模型:它将文本视为一个词汇的集合,通过计算词汇在文本中的频率或tf-idf值,将文本转换为向量表示。然后使用向量之间的相似性度量(如余弦相似性)来计算文本相似性。但是其忽略了词语的顺序和上下文关系,无法捕捉词语之间的关联和上下文信息,丧失了一部分语义信息。基于统计的方法:如余弦相似性、编辑距离、jaccard系数等。这些方法通过计算文本之间的统计特征或距离度量来评估相似性,但是无法处理语义相似性,只能从表面上比较文本之间的差异。
4、近年来,基于深度学习的方法的兴起为短文本相似性计算带来了新的解决方案,能够更好地处理语义表示和上下文建模,并取得了更好的效果。其中双向长短期记忆网络作为一种基本模型在计算相似性时被广泛应用,但是其也存在一些不足。因为尽管双向长短期记忆网络可以捕捉输入序列的上下文信息,但在处理复杂的语义任务时,其能力可能有限,存在着长期依赖、缺乏全局语义建模、语义歧义处理、语义信息不足等等的问题。基于这些问题,就会导致在计算文本相似性的时候,出现预测不准的结果。
技术实现思路
1、本公开为了解决上述问题,提出了一种短文本相似性度量方法及系统,利用多层双向长短期记忆网络结合残差连接和改进的多头注意力机制构建短文本相似度计算模型,同时从过去和未来的上下文中获取信息,解决短文本通常缺乏上下文信息的问题,使得模型通过多层双向处理获取更全面深层次的语义理解。
2、根据一些实施例,本公开采用如下技术方案:
3、一种短文本相似性度量方法,包括:
4、获取多组待相似性度量的短文本,每组待相似性度量的短文本包括两条文本信息;
5、将每组短文本信息进行嵌入处理,将两个文本信息分别转化为低维度向量词嵌入矩阵表示;分别对两个词嵌入矩阵表示进行特征提取,首先,利用双层的双向长短期记忆网络提取输入词嵌入矩阵表示中的上下文信息,并输出前向和反向的隐藏状态的拼接结果,然后利用多头注意力机制确定输入矩阵表示中的关键部位,动态地调整注意力分布,然后将结果输出至下一个双层的双向长短期记忆网络中,提取语义特征向量,将所述语义特征向量与隐藏状态的拼接结果进行残差连接,获取最终的两个特征向量,利用两个特征向量进行相似性度量。
6、根据一些实施例,本公开采用如下技术方案:
7、一种短文本相似性度量系统,包括:
8、数据获取模块,用于获取多组待相似性度量的短文本,每组待相似性度量的短文本包括两条文本信息;
9、相似性度量模块,用于将每组短文本信息进行嵌入处理,将两个文本信息分别转化为低维度向量词嵌入矩阵表示;分别对两个词嵌入矩阵表示进行特征提取,首先,利用双层的双向长短期记忆网络提取输入词嵌入矩阵表示中的上下文信息,并输出前向和反向的隐藏状态的拼接结果,然后利用多头注意力机制确定输入矩阵表示中的关键部位,动态地调整注意力分布,然后将结果输出至下一个双层的双向长短期记忆网络中,提取语义特征向量,将所述语义特征向量与隐藏状态的拼接结果进行残差连接,获取最终的两个特征向量,利用两个特征向量进行相似性度量。
10、根据一些实施例,本公开采用如下技术方案:
11、一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现所述的一种短文本相似性度量方法。
12、根据一些实施例,本公开采用如下技术方案:
13、一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现所述的一种短文本相似性度量方法。
14、与现有技术相比,本公开的有益效果为:
15、本公开使用多层的双向长短期记忆网络来进行对短文本的特征提取,可以同时从过去和未来的上下文中获取信息,解决了短文本通常缺乏上下文信息的问题,使得模型通过多层双向处理获取更全面深层次的语义理解。
16、本公开引入的改进的多头注意力机制,可以增强短文本相似性计算模型对于不同关注点的处理能力,提高模型的表达能力、鲁棒性和泛化能力。通过综合考虑不同的关注点和信息子空间,使得模型可以更好地捕捉文本中的语义信息,从而提高短文本相似性计算的准确性和效果;机制中的每个注意力头都可以学习到不同的关注权重分布,从而提取不同的语义信息,通过注意力机制能够解决对于重要词语和不重要词语分配不同的权重的问题,以此来提高文本相似性的准确率。
17、本公开引入的残差连接模块,使得模型在之前顺序网络的基础上能够结合多层的网络输出,从而使得模型可以更深层地进行特征学习和表示学习,捕捉更丰富、更复杂的特征和模式;能够更加全面丰富的结合短文本的浅层和深层特征信息,解决了短文本的长度过短,提取特征信息不足的问题。
技术特征:
1.一种短文本相似性度量方法,其特征在于,包括:
2.如权利要求1所述的一种短文本相似性度量方法,其特征在于,所述嵌入处理为利用word2vec词向量模型,将获取的文本信息进行处理,将文本信息转化为低维度向量词嵌入矩阵表示。
3.如权利要求1所述的一种短文本相似性度量方法,其特征在于,所述特征提取的过程依次通过多层双向长短期记忆网络、多头注意力机制和残差连接进行,所述双向长短期记忆网络包括了前向lstm、反向lstm和输出合并三个部分。
4.如权利要求3所述的一种短文本相似性度量方法,其特征在于,所述多头注意力机制中,计算多头注意力值的公式如下:
5.如权利要求4所述的一种短文本相似性度量方法,其特征在于,在多头注意力机制中加入单层的cnn和mlp结构,通过cnn进行卷积运算降低输入v和q的维度,提取输入序列中的局部模式和特征,捕捉输入序列的局部相关性;使用mlp,结合多个头的注意力表征,捕捉序列中的输入序列中的信息。
6.如权利要求1所述的一种短文本相似性度量方法,其特征在于,所述下一个双层的双向长短期记忆网络的结构与双层的双向长短期记忆网络结构相同,下一个双层的双向长短期记忆网络用来对注意力层的输出进一步进行特征提取,得到更深层次的语义特征向量。
7.如权利要求1所述的一种短文本相似性度量方法,其特征在于,所述残差连接是将两个双层的双向长短期记忆网络的输出进行拼接,获取最终的特征向量,具体为:
8.一种短文本相似性度量系统,其特征在于,包括:
9.一种非暂态计算机可读存储介质,其特征在于,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如权利要求1-7任一项所述的一种短文本相似性度量方法。
10.一种电子设备,其特征在于,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如权利要求1-7任一项所述的一种短文本相似性度量方法。
技术总结
本公开提供了一种短文本相似性度量方法及系统,涉及短文本挖掘分析技术领域,包括获取多组待相似性度量的短文本,每组待相似性度量的短文本包括两条文本信息;将每组短文本信息进行嵌入处理,将两个文本信息分别转化为低维度向量词嵌入矩阵表示;分别对两个词嵌入矩阵表示进行特征提取,将所述语义特征向量与隐藏状态的拼接结果进行残差连接,获取最终的两个特征向量,利用两个特征向量进行相似性度量。本公开解决短文本通常缺乏上下文信息的问题,使得模型通过多层双向处理获取更全面深层次的语义理解。
技术研发人员:鲁芹,赵硕
受保护的技术使用者:齐鲁工业大学(山东省科学院)
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!