一种基于对抗迁移学习的预训练漏洞修复方法
本发明属于软件调试领域,具体涉及一种基于对抗迁移学习的预训练漏洞修复方法。
背景技术:
1、随着软件漏洞的数量和复杂性的增加,开发人员需要对软件漏洞深入了解,并尽可能的减少对系统功能的影响,大大增加了软件漏洞修复的成本。为了减小软件漏洞修复成本,研究人员提出了自动修复软件漏洞的技术。但是从互联网能够采集到的漏洞修复数据集规模小,给研究人员带来了很大的挑战。
2、扬州大学在其申请的专利文献“一种基于树的漏洞修复系统及修复方法”(专利申请号:202210027014.7,公开号:cn114547619a)中提出了一种使用语法树表征代码进行漏洞代码自动修复的技术。该方法首先在github上收集漏洞修复数据集,将漏洞修复数据集中的代码转为具有数据流依赖和控制流依赖的语法树ast,将所述语法树ast进行抽象化和规范化得到token序列,然后将所述token序列划分为训练集和测试集,将训练集和测试集输入具有相同编码器和解码器数量的transformer模型进行训练和测试。该发明利用语法树和transformer模型,实现了对代码的自动修复,提高了代码修复的效率。但是该方法依然存在不足:
3、(1)该方法仅依赖漏洞修复数据集进行模型训练,在漏洞修复数据集规模较小的现状下,个别cwe类型的漏洞在数据集里面数量少或者干扰较强,导致模型未完全学习到该漏洞的特征时,会使模型表现不佳,泛化性、鲁棒性减弱;
4、(2)该方法对代码数据集的抽象化和规范化处理时,会将数据的函数名、变量、值进行替换,不能让模型学习到代码潜在的语意,导致模型的代码理解能力差;
5、(3)该方法过度依赖transformer模型生成修复代码,模型会将部分正确代码错误修复,导致模型过拟合。
6、本发明提出了一种基于对抗迁移学习的预训练漏洞修复方法,其优点在于:
7、(1)本发明通过在大型代码数据集上进行预训练后得到预训练的代码生成器模型,使得模型具备更好的代码理解能力、代码生成和补全能力;
8、(2)本发明借助生成对抗网络架构在漏洞修复数据集上对预训练的代码生成器模型进行微调,通过生成对抗网络的对抗训练机制,提升模型的抗干扰能力和修复能力,使得模型具备更高的鲁棒性、泛化性,同时解决模型过拟合的问题。
9、本发明首先在大型代码数据集上进行预训练后得到预训练的代码生成器模型,然后直接使用漏洞修复数据集进行对抗训练,使得模型减少源领域数据的依赖性,模型能够更好的适应目标领域的数据和特征分布,有助于减小源领域和目标领域的差异,并且提高了模型的训练速度,最终使得模型的漏洞修复准确率提升。
技术实现思路
1、发明目的:本发明的目的是设计一种泛化能力强、鲁棒性强和修复准确率高的漏洞修复方法,以适应漏洞修复数据集规模小的现状。
2、技术方案:为了解决上述技术问题,本发明设计了一种基于对抗迁移学习的预训练漏洞修复方法,包括以下步骤:
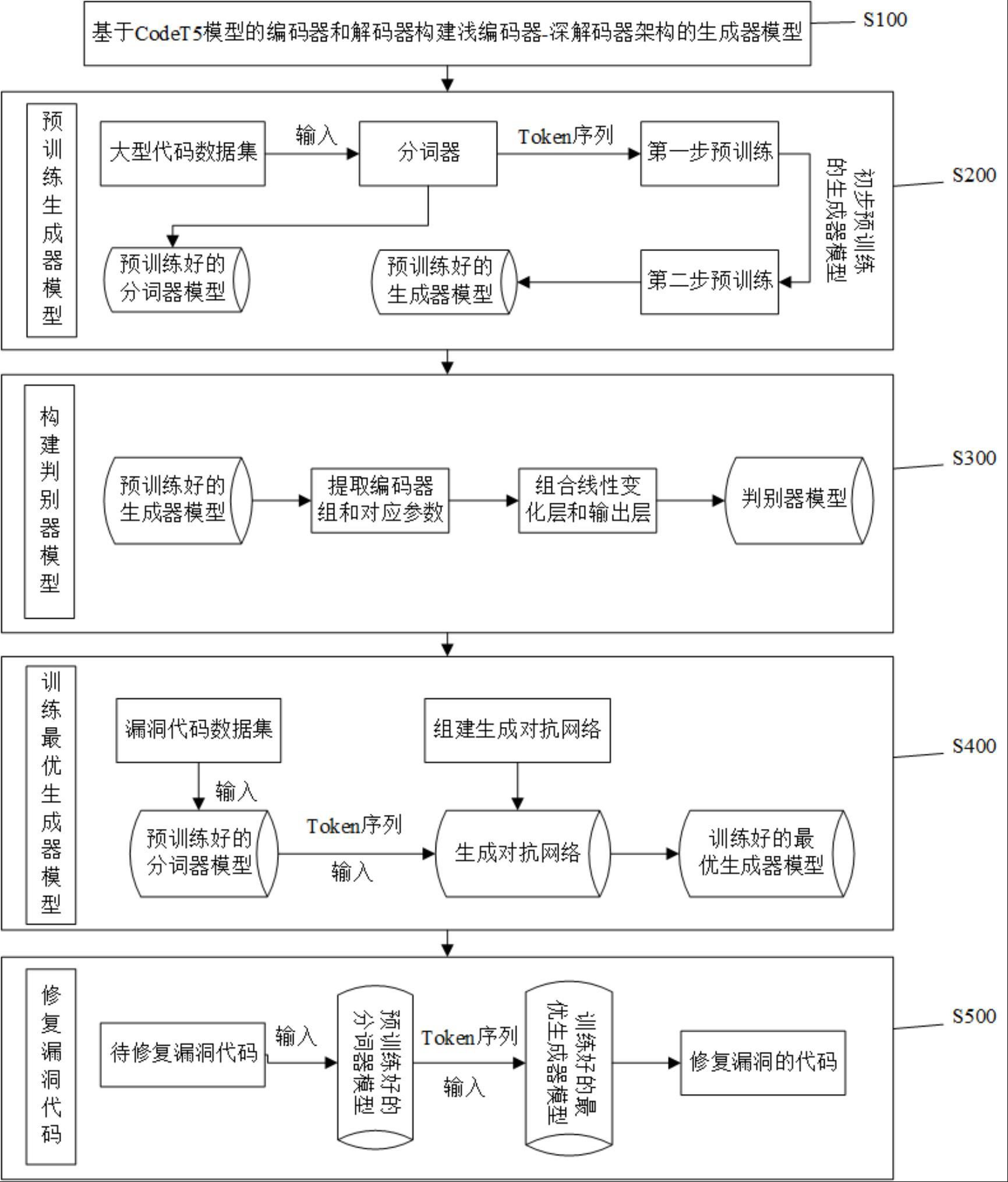
3、s100.构建浅编码器-深解码器架构的代码生成器模型;
4、s200.基于步骤s100,利用函数级别的大型代码数据集对所述代码生成器模型使用改进的预训练技术进行预训练,得到预训练的代码生成器模型;
5、s300.基于步骤s200,提取所述代码生成器模型的编码器组构建判别器模型;
6、s400.基于步骤s200和步骤s300,利用所述预训练代码生成器模型和判别器模型构建生成对抗网络;利用函数级别的漏洞修复数据集对所述生成对抗网络进行再训练,得到适用于修复漏洞代码的最优代码生成器模型;
7、s500.基于步骤s400,将函数级别的漏洞代码输入所述最优代码生成器模型,得到修复的代码。
8、进一步的,在步骤s100中,步骤s100具体为:
9、所述编码器和解码器是基于codet5模型中的编码器和解码器,所述浅编码器-深解码器架构表示代码生成器模型中解码器数量多于编码器数量。
10、进一步的,在步骤s200中,步骤s200包括以下步骤:
11、s210.利用初始unigram lm(一元语言模型)分词器将所述函数级别的大型代码数据集转为代码token序列,得到预训练的分词器、代码token序列;
12、s220.基于步骤s100和步骤s210,利用改进的因果语言建模技术对所述代码生成器模型进行第一步预训练,得到初步预训练的代码生成器模型;
13、s230.基于步骤s210和步骤s220,利用改进的span denoising(跨度去噪)技术对所述初步预训练的代码生成器模型进行第二步预训练,得到预训练的代码生成器模型;
14、其中,所述改进的span denoising技术包括:
15、在编码器的输入token序列中按50%的概率替换10%的token“[token 0],,,[token n]”为预定义token“[label 0],,,[label n]”,并在其之前添加特殊token“[som]”;在正确的token序列之前添加特殊token“[eom]”作为解码器输出的目标token序列;让解码器生成被替换的token序列“[token 0],,,[ token n]”,得到预训练的代码生成器模型。
16、进一步的,在步骤s220中,步骤s220包括以下步骤:
17、s221.在所述代码token序列中的5%到100%之间按照50%的概率选择一个token;在所选token之前的token序列的后面添加一个特殊token“[gob]”;将添加特殊token后的token序列作为模型输入,将所选token之后的token序列作为模型输出;
18、s222.在所述代码token序列中的5%到100%之间按照50%的概率选择一个token;在所选token之后的token序列的前面添加一个特殊token“[gof]”;将添加特殊token后的token序列作为模型输入,将所选token之前的token序列作为模型输出,得到初步预训练的代码生成器模型。
19、进一步的,在步骤s300中,步骤s300包括以下步骤:
20、s310.基于步骤s200,提取所述预训练的代码生成器模型的编码器,得到编码器组;
21、其中,所述编码器组包含所述预训练的代码生成器模型编码器组的参数;
22、s320.基于步骤s310,将所述编码器组与线性变化层、输出层组合,得到判别器模型;
23、进一步的,在步骤s400中,步骤s400包括以下步骤:
24、s410.基于步骤s200和步骤s300,利用所述预训练代码生成器模型和判别器模型构建生成对抗网络;
25、s420.基于步骤s210,利用所述预训练的分词器对函数级别的漏洞修复数据集分词得到漏洞代码token序列和修复代码token序列;
26、s430.基于步骤s410和步骤s420,将所述漏洞代码token序列和修复代码token序列同时输入所述生成对抗网络的代码生成器模型得到生成概率序列;
27、同时,所述代码生成器模型学习所述生成概率序列与输入的修复代码token序列之间的差异,得到损失值a;
28、s440.基于步骤s410、步骤s420和步骤s430,利用nucleus sampling(又称top-psampling,核心采样)算法对所述生成概率序列进行最优排列得到漏洞代码修复token序列;
29、同时,将所述修复代码token序列和漏洞代码修复token序列输入所述生成对抗网络的判别器模型,判别器模型学习修复代码token序列和漏洞代码修复token序列的差异,得到损失值b;
30、s450.优化器根据损失值a和损失值b,优化代码生成器模型,得到最优的代码生成器模型。
31、进一步的,在步骤s500中,步骤s500包括以下步骤:
32、s510.基于步骤s210,利用所述预训练的分词器对函数级别的漏洞代码进行分词得到待修复漏洞代码token序列;
33、s520.基于步骤s400和步骤s510,将所述待修复漏洞代码token序列输入最优的代码生成器模型,得到修复代码概率序列;
34、s530.基于步骤s520,再次利用nucleus sampling算法对所述修复代码概率序列进行最优排列得到修复的代码。
35、本发明与现有技术相比的有益效果是:
36、(1)本发明使用的浅编码器-深解码器架构进行概率序列生成,相较于使用编码器和解码器数量一致的transformer模型而言,浅编码器-深解码器架构对于代码生成任务具有更好的表现;
37、(2)本发明使用函数级别的大型代码数据集进行代码生成器模型预训练,相较于将漏洞修复数据集抽象化和规范化后用于transformer模型训练而言,代码生成器模型可以学到更广泛的代码结构、语意和特征,以适应在漏洞修复数据集小的现状下修复漏洞的任务;
38、(3)本发明使用对抗迁移学习来进行模型训练,相较于直接训练transformer模型训练而言,对抗训练可以通过将生成的错误修复代码用于反向训练代码生成器模型,迁移学习可以将代码生成领域知识迁移至漏洞代码修复领域中,提高了模型的鲁棒性、泛化性。
- 还没有人留言评论。精彩留言会获得点赞!