一种基于核化运动原语的技能学习方法
本发明涉及机械臂控制领域,具体涉及一种基于核化运动基元(kmp)的示教学习(lfd)方法。
背景技术:
1、现代机器人技术的快速发展使机器人进入了新的工作场景,如家庭、医院、健身房、办公室等,这为人类带来了更多的便利和机会,同时也对机器人技术提出了更高的要求。然而,在这些场景中存在许多不可预测的扰动,这使应用预编程方法变得非常困难。相反,从演示中学习(lfd)提供了一种将技能从人类转移到机器人的高效和直观的方法,从而可以在新环境中进行泛化。
2、近十几年来,大量的lfd算法被提出,如动态运动原语(dmp)、动态系统(ds)、高斯混合模型(gmm)和概率运动原语(promp)等。dmp算法将运动轨迹的每个维度建模为二阶吸引子的时间演化系统。在强迫函数项的帮助下,dmp可以学习极其复杂的动作。然而,dmp只能对单一轨迹进行建模,忽略了轨迹维度之间的相关性。此外,强迫函数项是时间编码的,这使得dmp对时间扰动敏感。在前人基础上,一种dmp算法被提出,它结合gmm/gmr提高了轨迹维度建模的能力。promp算法通过应用分层贝叶斯模型对高维空间中的运动轨迹进行编码,提取演示的变异性,并为每个观测提供置信度标准。通过应用贝叶斯定理和轨迹分布的乘积,promp可以泛化技能,包括过点、组合和混合运动基元。然而,promp无法处理高维输入的问题。为了克服这个局限性,huang等提出了核化运动基元(kmp)算法。该算法通过求解一个优化问题得到最优的参数化轨迹分布。然后引入核函数代替人工定义的基函数来处理高维输入。
3、但是,promp和kmp需要广泛的论证来保证技能泛化的可靠性,这导致在很少演示的情况下再现精度不理想。因此,需要提出一种新的方法,以克服现有算法的局限性,提高机器人任务泛化的精度和效率。
技术实现思路
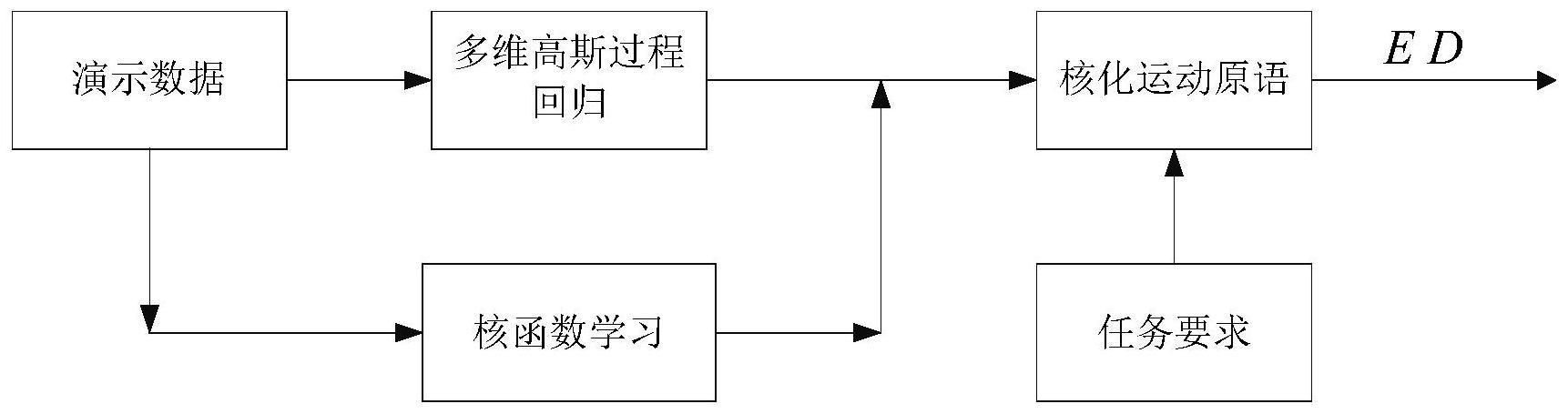
1、为了克服现有技术的机器人任务泛化的精度和效率较低的不足,原始kmp算法在泛化和处理高维输入方面表现优异,但在复现精度方面略显不足,本发明提供一种基于核化运动原语的技能学习方法,本发明对kmp算法进行了两点改进,首先,采用多元高斯过程(mvgp)对参考轨迹进行建模,初步提高了kmp的复现精度;其次,提出了一个优化问题来学习kmp中核函数的超参数,减少了对经验的依赖。结合这两步改进,提出了一种基于kmp的机器人技能学习方法i-kmp,用于学习机器人的运动轨迹,通过估计更可靠的参考轨迹分布和确定最优核函数,i-kmp方法可以更准确地学习技能模型。
2、为了实现上述目的,本发明采用的技术方案如下:
3、一种基于核化运动原语的技能学习方法,包括以下步骤:
4、1)参考轨迹学习:通过机械臂示教得到演示数据集,如式(1-1)所示:
5、
6、其中,d、st,m、ξt,m分别表示演示数据集、第m次演示的第t次采样时刻的时间输入和笛卡尔空间位置输出;t、m、tm、m分别表示当前演示轨迹采样点、第m条演示轨迹、最大采样点数和演示轨迹总数;
7、将演示数据集定义为多元高斯过程如式(1-2)所示:
8、
9、其中f、m、σ、ω分别表示为演示数据集上的多元高斯过程、均值矩阵、列协方差矩阵和行协方差矩阵;ξ、s、f(s)分别表示笛卡尔空间位置向量、笛卡尔空间位置向量的转置、时间输入向量和笛卡尔空间位置输出的拟合函数;设置均值函数m=0,则(1-2)式改写为服从多维正态分布
10、
11、其中ξ、s、k(s,s)分别表示演示数据集的输出矩阵、演示数据集的输入矩阵和核函数矩阵;核函数矩阵k(s,s)由高斯径向基核函数k(·,·)构建,其形式表示为:
12、
13、其中k(s1,s1)、k(sn,sn)为核函数矩阵对角线上的值,表示数据样本与自身的相似度,而k(s1,sn)、k(sn,s1)是核函数矩阵非对角线元素上的值表示不同样本之间的相似度;
14、针对式(1-3)中的分布,利用极大似然法估计求解最优参数,其中未知参数包括核中的超参数、噪声和行协方差矩阵ω;求解得到最优参数后,给定一组新的轨迹输入矩阵s*,预测的位置输出矩阵ξ*将服从联合矩阵变量高斯分布:
15、
16、其中k(s+s*,s+s*)、ω*分别表示演示数据集和预测数据集构建的核函数矩阵、最优行协方差矩阵;
17、同时,预测的轨迹分布p(ξ*|s,ξ,s*)仍然满足矩阵变量高斯分布:
18、
19、其中分别代表预测的均值,列协方差矩阵和行协方差矩阵;k(s,s)-1、k(s*,s*)、k(s,s*)、k(s*,s)分别表示由演示数据集与其自身构建的核函数矩阵的逆矩阵、由预测数据集与其自身构建的核函数矩阵、由演示数据集与预测数据集构建的核函数矩阵、由预测数据集与演示数据集构建的核函数矩阵;
20、计算得到上述参数后,新的轨迹的ξ*的期望和协方差表示为:
21、
22、其中表示kronecker内积;
23、2)改进核化运动基元的技能学习:对于(1-1)中的演示数据集d,使用分层贝叶斯模型建模轨迹概率模型,其运动轨迹可以被表示为其中ξi(s)表示对应轨迹的输出,φ(s)表示对应输入的基函数向量,符号表示转置,wi是一个权重向量;扩展到多维轨迹,模型可以被表示为:
24、
25、其中ξ(s),φ(s)分别是输出和对应的基函数对角矩阵,是权重向量矩阵;w服从参数为θw的正态分布,即其中μw,σw分别是w的均值和方差;p(w|θw)、θw分别表示轨迹的分布和需要求解的参数;
26、则轨迹分布p(ξ(s)|θw)表示为正态分布,如下:
27、
28、其中表示一个正态分布,第一项代表均值,第二项代表协方差;
29、不同于原始的核化运动原语(kmp)利用高斯混合模型(gmm)对(1-9)式进行建模,并使用高斯混合回归(gmr)估计其条件概率分布p(ξ|s),这里使用1)中的多元高斯过程回归(mvgp)估计p(ξ|s):
30、
31、其中分别是(1-7)式中得到轨迹的均值和协方差
32、然后在选择好参考点之后,μw,σw的最优解可以通过求解如下的优化问题来得到:
33、
34、其中t是总的参考点的数量,dkl(·||·)表示分布和分布p(ξ|s)之间的库尔贝克-莱布勒散度,p(ξ|s)分别是(1-9)和(1-10)表示的概率分布;
35、得到μw,σw的最优解后,将其代入式(1-9)中,由(1-9)式解得在新的时间输入s*下的轨迹分布如下:
36、
37、其中e表示预测得到的轨迹的均值,d表示预测得到的轨迹的协方差,代表不确定性。
38、由于核化运动原语(kmp)算法的超参数θ是人工指定的,为解决这个问题,设计构造了如下优化问题去自动学习核函数中的超参数,这里使用高斯核作为kmp的核函数:
39、
40、其中j(θ),θ,分别表示目标损失函数,核函数的超参数和演示轨迹点的总数量,是式(1-12)估计的轨迹概率分布,直接受到θ的影响;
41、通过使用连续二次规划(sqp)算法求解优化问题(1-13),解得最优参数θ;
42、本发明有益效果主要表现在:
43、1)提出了一种基于核化运动原语的技能学习方法,首次将多元高斯过程回归(mv-gpr)用于kmp的初始化,以较少的实验次数获得了较高的学习精度。
44、2)提出了一种基于核化运动原语的技能学习方法,kmp中核函数的超参数是通过求解一个优化问题来学习的,而不是通过经验指定。
- 还没有人留言评论。精彩留言会获得点赞!