面向国际中文教育的多义词阅读理解题目生成方法及系统
本发明涉及自然语言,尤其涉及一种面向国际中文教育的多义词阅读理解题目生成方法及系统。
背景技术:
1、汉语是世界上最难学的语言之一,其中的一个重要原因就是汉语中的一字多义现象,即一个词有多个义项,在不同的语境下呈现不同的义项。学习者需要通过大量的辨析练习才能学习、理解、记忆多义词知识。多义词题库的构建对二语教学领域和自然语言处理领域起到了至关重要的作用。在自然语言处理领域,如何识别文本中多义词的词义也一直是一个重要课题。然而多义词题库资源的建设仍然停留在初级和人工阶段,至今市场上仍没有能够实现多义词阅读理解题目的智能生成。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种面向国际中文教育的多义词阅读理解题目生成方法及系统,以改善上述问题。
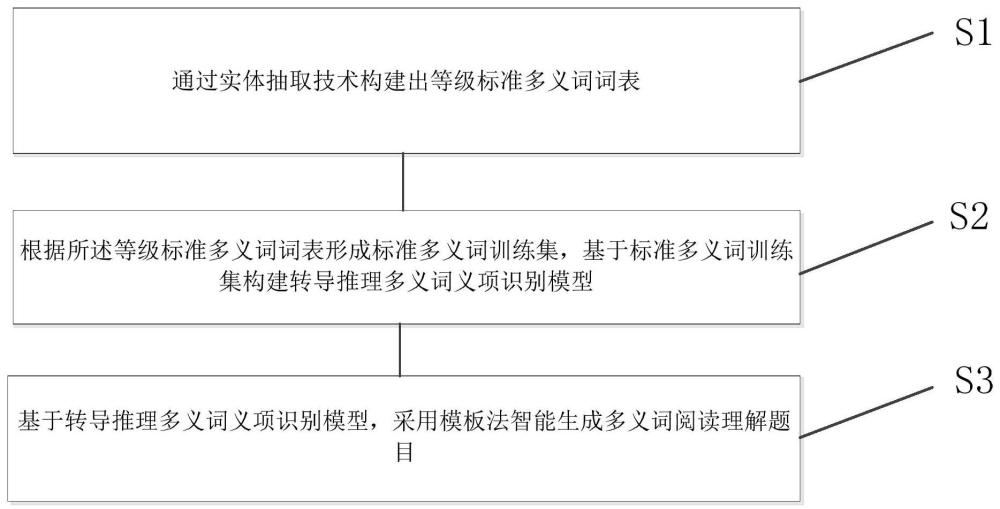
2、本发明实施例提供了一种面向国际中文教育的多义词阅读理解题目生成方法,其包括如下步骤:
3、s1,通过实体抽取技术构建出等级标准多义词词表;
4、s2,根据所述等级标准多义词词表形成标准多义词训练集,基于标准多义词训练集构建转导推理多义词义项识别模型;
5、s3,基于转导推理多义词义项识别模型,采用模板法智能生成多义词阅读理解题目。
6、优选地,步骤s1具体包括:
7、针对《学汉语词典》,采用版面分析与正则匹配方法抽取其中每个词条信息,包括词,拼音,词性,义项编号,义项,例句集,形成结构化的第一学汉语词典数据集learn_dic0;
8、针对《现代汉语词典》,采用版面分析与正则匹配方法抽取其中每个词条信息,包括词,拼音,词性,义项编号,义项,例句集,形成结构化的第二汉语词典数据集learn_dic1;
9、针对《国际中文教育中文水平等级标准》中的每个词汇,首先抽取其在第一学汉语词典数据集learn_dic0的词条信息,若抽取信息为空,则抽取其在第二汉语词典数据集learn_dic1的词条,并将具有2个或以上义项的词条信息进行汇集,形成等级标准多义词词表gs_poly;其中,所述等级标准多义词词表gs_poly的每个词为多义词,并且每个词都属于《国际中文教育中文水平等级标准》中的范畴,具有标准等级词汇要素信息。
10、优选地,步骤s2具体包括:
11、从等级标准多义词词表gs_poly中抽取每个词条中的词、义项和例句集,按照{词,义项,例句}形式构建标准多义词的一条训练数据,形成初始标准多义词训练集gs_poly_tr0;
12、以初始标准多义词训练集中的词为索引,按照{词,义项,例句}的形式到在线汉语词典、百度汉语中爬取训练数据,添加到初始标准多义词训练集,形成最终标准多义词训练集gs_poly_tr1;
13、抽取最终标准多义词训练集gs_poly_tr1的多义词形成多义词词典,添加到jieba分词库中作为用户自定义词典;
14、使用jieba分词库对最终标准多义词训练集gs_poly_tr1的例句str_yu进行分词,将分词结果存储在例句分词列表中sent_words0;
15、在例句分词列表sent_words0中,去掉停用词,形成修正例句分词列表sent_cut;
16、针对被测的多义词例句test={wtest,stest},将待测多义词例句进行jieba分词并去掉停用词,形成待测多义词分词集test_cut;其中,wtest指的是被测的多义词,stest指的是被测的例句文本;
17、设待测多义词wtest的义项集合termtest={ttest1,ttest2,…,ttesti,…ttestn},其中ttesti表示wtest的第i个义项,n表示wtest的义项总数,从修正例句分词列表sent_cut抽取出wtest任一个义项ttest的修正例句分词列表,形成其对应的义项例句分词列表sent_cut_ttest;
18、将待测多义词分词集test_cut加入到义项例句分词列表sent_cut_ttest中,形成义项转导推理例句分词列表sent_cut_ttest_td,并根据义项转导推理例句分词列表sent_cut_ttest_td构建转导推理多义词义项识别模型prg。
19、优选地,转导推理多义词义项识别模型prg的构建过程如下:
20、针对义项转导推理例句分词列表sent_cut_ttest_td计算待测多义词wtest的分词集test_cut中每个词的tf-idf值并相加,用于衡量wtest的重要性程度;其中:
21、tf-idf=词频tf*逆文档频率idf
22、针对待测多义词wtest的义项集合termtest={ttest1,ttest2,…,ttesti,…ttestn},遍历n次转导推理多义词识别模型prg,得到相对应的义项重要性值列表termtest-kp={ttest-kp1,ttest-kp2,…,ttest-kpi,…ttest_kpn};
23、取termtest-kp最大值所对应的义项,记为ttest-max,作为转导推理多义词义项识别模型prg的输出,即prg公式如下所示:
24、ttest-max=prg(test)。
25、优选地,步骤s3具体包括:
26、设多义词题目模板test={type,question_content,question,options,answer,level},其中type指的是题目的类型,question_content指的是题目的语料,question指的是题目的题干,options指的是干扰项集合,options进一步表示为options={options1,option2,option3,…},其中options1表示第一个干扰项,option2表示第二个干扰项,option3表示第三个干扰项,干扰项集合最少1个选项,answer指的是答案,level指的是题目的难度等级,其遵从《国际中文教育中文水平等级标准》的规定;
27、选择等级标准多义词词表gs_poly任意词汇的若干要素,形成出题词汇集wp-list={wp,wp_term,wp_term_ot,wp_yu,wp_level},其中wp表示目标多义词,wp_term表示目标多义词的考核义项,wp_term_ot表示考核义项之外的其它义项集合,wp_yu表示目标多义词的例句,wp_level表示目标多义词的标准等级;
28、基于多义词题目模板test进行多义词题目wp-test的智能生成。
29、优选地,基于多义词题目模板test进行多义词题目wp-test的智能生成包括:
30、将出题词汇wp-list中的例句wp_yu中的目标出题多义词wp加上括号,即替换为"(wp)",形成题目语料lj_question_content;
31、将题目的题干lj_question设置为“理解上述句子中括号内词词语的意思,从下列选项中选择该词语正确的义项”;
32、将answer设置为出题词汇wp-list中的考核义项wp_term;
33、将目标出题多义词wp的其它义项集wp_term_ot设置为目标出题多义词wp的干扰项集合wp_options;
34、将出题词汇wp-list中的标准等级wp_level设置为题目的等级level;
35、将多义词题目的题目类型type设置为“理解词语”,即通过阅读语料或题干,理解目标多义词在语料或题干上下文的正确义项。
36、本发明实施例还提供了一种面向国际中文教育的多义词阅读理解题目生成系统,其包括如下步骤:
37、实体抽取单元,用于通过实体抽取技术构建出等级标准多义词词表;
38、模型构建单元,用于根据所述等级标准多义词词表形成标准多义词训练集,基于标准多义词训练集构建转导推理多义词义项识别模型;
39、题目生成单元,用于基于转导推理多义词义项识别模型,采用模板法智能生成多义词阅读理解题目。
40、本发明实施例以《国际中文教育中文水平词汇等级标准》为核心,以多义词智能识别模型为支撑,实现国际中文多义词题目的智能生成。本发明实施例能够为多义词题库智能生成注入新鲜活力,实现汉语资源的科学利用,不仅为多义词题库构建提供可借鉴的技术路线,也扩充了国际中文多义词题库,提供未来研究和应用开发的语料库支持。
- 还没有人留言评论。精彩留言会获得点赞!