一种结合知识图谱和大语言模型的高校科研管理问答系统
背景技术:
1、在当今信息爆炸的时代,高校面临着大量的信息和知识管理挑战。学生、教师和校园管理人员需要及时、准确地获取有关学校资源、课程、政策等各方面信息。传统的信息检索和问答系统存在着多种限制,包括关键字匹配的局限性、对复杂问题的无法回答、信息更新不及时等问题。
2、知识图谱是一种经过精心构建的知识表示方法,具备高准确性和专业性的优点。知识图谱依赖专业知识和多数据源构建,能够提供高质量、精确的答案。这意味着系统用户可以直接从知识图谱中检索信息,而无需依赖文本数据的模糊匹配。此外,知识图谱具有可扩展性,可以不断更新和扩展,以包含新的信息和知识,使系统能够适应不断变化的问题领域。
3、然而,知识图谱也存在一些局限性。首先,其覆盖范围受限于构建它的数据源和专业知识,可能无法回答某些领域或主题的问题。其次,知识图谱在处理模糊、开放性或歧义性问题方面存在困难,因为这些问题缺乏明确的答案。最后,构建多语言知识图谱和支持多语言的问答系统可能更加复杂,因为需要考虑不同语言之间的语义和文化差异。
4、与此同时,大语言模型(例如chatgpt)具备强大的自然语言理解和生成能力,通用性强,适用于各种不同领域和主题的问题。这种模型基于大规模文本数据训练,具备广泛的背景知识,可以回答各种类型的问题。
5、然而,大语言模型也存在一些限制。首先,它缺乏实时性,因为大语言模型的训练成本极高,无法提供最新的实时信息或针对当前事件的答案。其次,它通常基于表面级别的文本匹配和模式匹配,缺乏深层次的语义理解。另外,生成的答案不一定总是准确的,因为依赖于训练数据中的信息,可能包含错误或不准确的信息。最后,大语言模型可能被滥用,用于生成虚假信息、宣传、欺诈和有害内容,需要监管和管理以减少风险。在高度专业领域,大语言模型可能表现不佳,因为其训练数据可能不足以覆盖这些领域。
技术实现思路
1、针对上述问题,本发明结合知识图谱和大语言模型的优点和缺点,提出一种综合利用两者的科研管理知识问答系统,以实现更高效、准确的自然语言问答服务,同时克服各自的局限性。通过将知识图谱的准确性与大语言模型的通用性相结合,本系统能够处理广泛的问题领域,提供更全面和精确的答案,从而为用户提供卓越的问答体验。
2、为达上述目的,本发明提供如下技术方案:
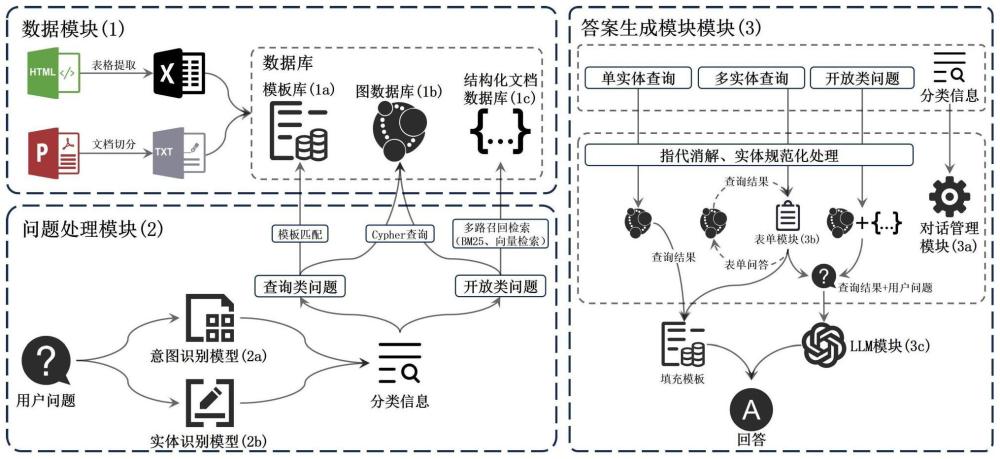
3、一种结合知识图谱和大语言模型的高校科研管理问答系统,其关键技术包括三部分:
4、1.数据模块(1):这一部分负责数据的清洗,将可用的数据进行结构化,并以不同的格式存储在数据库中。这一部分包括以下子模块:
5、1)模板库(1a):用于保存由人工设计和大语言模型生成的回答模板。
6、2)图数据库(1b):以实体-关系-实体和实体-关系-属性的方式保存数据。
7、3)结构化文档数据库(1c):用于结构化保存论文、专利、项目等文档数据。
8、2.问题处理模块(2):这一部分对用户的问题进行处理,以获得问题分类信息。这一部分包括以下子模块:
9、1)意图识别模型(2a):用于对问题进行分类,提高模型的泛化性,简化后续处理流程。
10、2)实体识别模型(2b):用于抽取关键实体,这些实体将用于后续对数据库的查询操作。
11、3.答案生成模块(3):根据数据模块(1)的查询结果和问题处理模块(2)的分类信息,结合相应策略来回答用户的问题。这一部分包括以下子模块:
12、1)对话控制模块(3a):负责指代消解、实体规范化处理,以及根据不同的分类信息执行不同的查询操作等。
13、2)表单模块(3b):根据意图识别模型(2a)的结果生成适当的表单,引导用户填写表单信息,采用一定的策略。
14、3)大语言模型(llm)模块(3c):结合查询结果和模型自身的知识,生成多样性且高质量的回答。
15、进一步的,根据权利要求1所述的一种结合知识图谱和大语言模型的高校科研管理问答系统,其整体过程按照以下步骤进行:
16、s1:数据模块(1)使用网络爬虫在各个网站上爬取学校、专业、论文、专利、项目的html网页和pdf文档。随后,对这些网页和文档进行表格提取和文档切分操作,以获得学校、专业、教师等结构化数据,以及论文、专利、项目等的txt格式数据。
17、s2:人工构建回答模板的模板库(1a)。这些模板将用于生成回答,涵盖了不同类型的问题和回答结构,以提高回答的多样性和准确性。
18、s3:通过结构化数据构建实体-关系-实体,实体-关系-属性的图数据库(1b)。
19、s4:对txt格式的数据进行进一步的数据清洗,以生成结构化文档数据库(1c),并将其保存为json格式,以便使用bm25、向量检索等多路召回检索技术进行信息检索。这个文档数据库将包含论文、专利、项目等信息,以便系统能够检索和提供相关信息的答案。
20、s5:意图识别模型(2a)的构建。首先,使用少量人工标注数据、chatito生成的模板数据以及由llm生成的多样化数据构建训练数据集。接下来,使用预训练好的中文bert模型(例如hugging face提供的bert-chinese)来初始化模型的参数。随后,在bert模型之后添加一个用于文本分类的全连接层,其输出大小等于分类类别的数量。这个全连接层将bert的输出转换为分类概率分布。最后,使用交叉熵损失函数对模型进行训练和优化,以提高其意图识别的准确性。
21、假设有c个类别,模型的输出是一个大小为c的向量,表示每个类别的分数(logits),并且有一个真实的类别标签y,取值范围从1到c。交叉摘损失函数的表达式如下:
22、
23、其中,yi表示真实的标签,是一个c维的one-hot向量,其中第i个元素为1,其余元素为0;z是模型的输出向量,包含了每个类别的分数(logits);softmax(z)i表示softmax函数应用在模型输出的第i个元素上,用于将分数转换为类别概率。其数学表达式为:
24、s6:实体识别模型(2b)的构建。首先,使用少量人工标注数据、chatito生成的模板数据以及由llm生成的多样化数据构建训练数据集。接下来,使用预训练好的中文bert模型(例如hugging face提供的bert-chinese)来初始化模型的参数。然后,在bert模型之后添加一层全连接层和条件随机场(crf)层。全连接层用于将bert的输出映射到命名实体识别(ner)任务的标签空间。条件随机场层用于建模标签之间的依赖关系。最后,结合bert模型使用交叉熵损失进行优化,同时crf部分使用crf损失进行优化。此外,在对新的文本进行预测时,本专利使用维特比算法来找到最佳的标签序列,以实现高效的实体识别。
25、对于ner任务,假设有c个可能的标签,并且对于每个标记,模型输出一个c维的概率分布向量。真实的标签序列表示为y,模型的输出表示为p。交叉摘损失的数学表达式为:
26、
27、其中,yi是真实标签序列的第i个元素,是一个one-hot向量,其中只有一个元素为1,表示真实标签;pi是模型的输出概率分布向量的第i个元素,表示模型对第i个标签的预测概率。
28、条件随机场(crf)的损失函数是基于概率的,它用于模拟和优化标签序列的分布概率,以最大化真实标签序列的概率。
29、假设有一个观测序列x,其中x包含n个标记,表示为x=(x1,x2,…,xn)。假设有一个标签序列y,其中y包含n个标签,表示为y=(y1,y2,…,yn)。这些标签对应于观测序列x中的每个标记。条件随机场的目标是计算给定观测序列x的条件下,标签序列y的条件概率p(y∣x)。这可以表示为:
30、
31、其中,z(x)是归一化因子,确保所有标签序列的概率之和为1;λi是模型参数,用于权衡不同特征函数的贡献;fi(yi,yi-1,x)是特征函数,它度量了标签yi和yi-1与观测序列x的关系。模型的目标是通过学习合适的参数λi,以最大化真实标签序列的条件概率p(y∣x)。奔放使用负对数似然损失(negative log-likelihood loss)来表示crf的损失函数:
32、
33、这个损失函数的目标是最小化负对数似然,以优化模型参数,使得真实标签序列的条件概率最大化。
34、维特比算法是一种用于解码条件随机场(crf)的标签序列的动态规划算法,它寻找在给定观测序列下具有最高条件概率的标签序列,对于维特比算法:
35、假设有一个观测序列x,其中x包含n个标记,表示为x=(x1,x2,…,xn)。假设有一个标签序列y,其中y包含n个标签,表示为y=(y1,y2,…,yn)。这些标签对应于观测序列x中的每个标记。
36、在维特比算法中,目标是找到具有最高条件概率p(y|x)的标签序列y。这可以表示为:
37、
38、维特比算法的核心思想是利用动态规划来计算每个位置i处的最佳标签yi,并逐步构建最佳标签序列。算法步骤如下:
39、1)初始化步骤:初始化一个矩阵(表格)v,其中v[i][j]表示在位置i处选择标签j的最大条件概率。初始化一个回溯矩阵b,其中b[i][j]存储在位置i处选择标签j时的前一个最佳标签。
40、2)递推步骤:从左到右遍历观测序列x中的每个位置i。对于每个位置i,对于每个可能的标签j,计算v[i][j]和b[i][j]:
41、
42、
43、其中k表示在位置i-1处的标签。
44、3)终止步骤:在观测序列的末尾n,找到具有最大条件概率的最后一个标签yn:
45、
46、4)回溯步骤:其中k表示在位置i-1处的标签。
47、最终,维特比算法会返回具有最高条件概率p(y|x)的标签序列y*。这个序列是通过在每个位置选择具有最大条件概率的标签来构建的。
48、s7:对话管理模块(3a)首先对用户的问题进行指代消解,以解决问题中的指代词汇,并将指代消解的结果也作为实体进行查询。随后,对实体识别模型(2b)提取的实体进行规范化处理,以确保获得准确的查询结果。这些步骤有助于提高对用户问题的理解和信息检索的准确性。
49、s8:对话管理模块(3a)根据问题处理模块(2a)的分类信息,选择不同的策略来生成答案,具体如下:
50、1)对于单实体查询类问题,系统会首先尝试模板匹配,然后在图数据库中执行cypher查询,将图数据库查询结果填充到匹配的模板中,从而生成答案。
51、2)对于多实体查询类问题,系统会使用表单模块(3b)根据意图识别模型(2a)的结果生成合适的表单,然后将实体识别模型(2b)提供的实体信息填入表单中。如果表单信息不完整,系统将启动表单问答,直到表单信息填写完整。随后,对话管理模块(3a)将执行下一步操作,即在图数据库中执行cypher查询,并将查询结果作为提示(prompt)与用户问题拼接后输入到llm模块(3c),以生成答案。
52、3)对于开放类问题,系统将分别在图数据库中执行cypher查询和在结构化文档数据库(1c)上执行多路召回检索(例如bm25、向量检索)。然后,系统将将这两个查询结果作为提示(prompt)与用户问题拼接后输入到llm模块(3c),以生成答案。
53、与现有技术相比,本发明有益效果在于:
54、1)充分模型利用:本系统充分利用大语言模型,有效整合了问答的各个环节,发挥了模型的高度理解、分析和推理能力。这使得用户能够获得更深入和准确的答案,提高了问答服务的质量和效果。
55、2)高度可控性:通过采用规范化的问题回答模板,系统确保了生成答案的可控性。这有助于防止模型编造虚假信息或提供不准确的答案,为用户提供了更可信赖的问答服务。可控性也有助于系统在专业领域提供精确的答案。
56、3)广泛的问题覆盖:本系统综合利用知识图谱和大语言模型的特点,能够覆盖广泛的问题领域,包括专业领域和通用知识。这为用户提供了全面的答案,不受领域限制,增加了问答系统的适用性。
57、4)高准确性的答案:通过结合知识图谱的高准确性和大语言模型的深度背景知识,本系统能够提供高度准确的答案,满足用户对信息准确性的需求。这有助于用户更好地理解和解决问题。
58、5)实时性:尽管大语言模型存在实时性挑战,但本系统通过知识图谱实现对最新信息的追踪和更新。这使系统能够满足用户的实时需求,提供更广泛的服务范围,尤其在需要及时信息的情况下具有重要价值。
- 还没有人留言评论。精彩留言会获得点赞!