嵌入特权信息进行强化的面部表情识别方法和系统
本发明涉及一种嵌入特权信息进行强化的面部表情识别方法和系统,属于图像处理。
背景技术:
1、面部表情是人类情感的重要表达方法,基于人脸图像面部表情识别一直是情感计算领域中的热点研究问题。研究人员为了提升面部表情识别在人机交互,医疗服务,智能机器人等实际应用中的有效性和可靠性,进行了大量的研究工作。但是,复杂的光照条件、不确定的姿态和遮挡等,对表情识别的准确率造成了极大的影响。并且人类情感的表达是复合的,微妙,且多模态的。内在情感除了会在人脸面部呈现不同的外在表情之外,往往还会伴随着相应的语音、语义和姿态的变化。结合多种情感模态数据对对象内在情感进行综合研判,用情感特征辅助提升表情识别的性能,将大大提升识别的可靠性。
2、现有的基于深度学习的表情识别主要依赖于广泛使用的cnn模型为模型骨干,从人脸图像中更可靠地(相对浅层方法而言)提取面部表情特征。而在多模态方面,通常通过语音,文本和脑电等异构的多模态情感数据来与表情图像数据进行融合互补。研究表明,多模态表情识别相比与单模态在数据互补性、模型可靠性和性能优越性等方面有明显的优势。但是,多模态表情识别一般的范式是利用多模态数据训练,多模态数据测试。但是一般情况下,并不能总是提供多种模态的数据,因为通常只有一个视觉接收器,而缺乏语音和语义的信息。因此,多模态数据训练,单模态数据测试尤为重要。
3、随着特权信息这个思想的首次提出,在情感识别领域,也有越来越多利用特权信息的尝试。特权信息的定义是模型在训练阶段可以访问关于训练样本的额外信息,而这些信息在测试期间是不可用的。在表情识别领域,可以使用深度神经网络提取人脸图像的表情特征,并利用特权信息损失(辅助信息损失)实现将特权信息中包含的表情特征传递到人脸图像特征提取中。
4、有鉴于此,确有必要提出一种嵌入特权信息进行强化的面部表情识别方法和系统,以解决上述问题。
技术实现思路
1、本发明目的在于提供一种嵌入特权信息进行强化的面部表情识别方法,能够通过将多模态情感数据作为特权信息嵌入进行强化。
2、为实现上述目的,本发明提供了一种嵌入特权信息进行强化的面部表情识别方法,包括如下步骤:
3、步骤1:一方面对真实环境人脸面部表情图像进行预处理,另一方面对另外两种模态的语音数据和文本数据进行表观转换,分别得到语音特征梅尔图谱和文本特征语义张量;
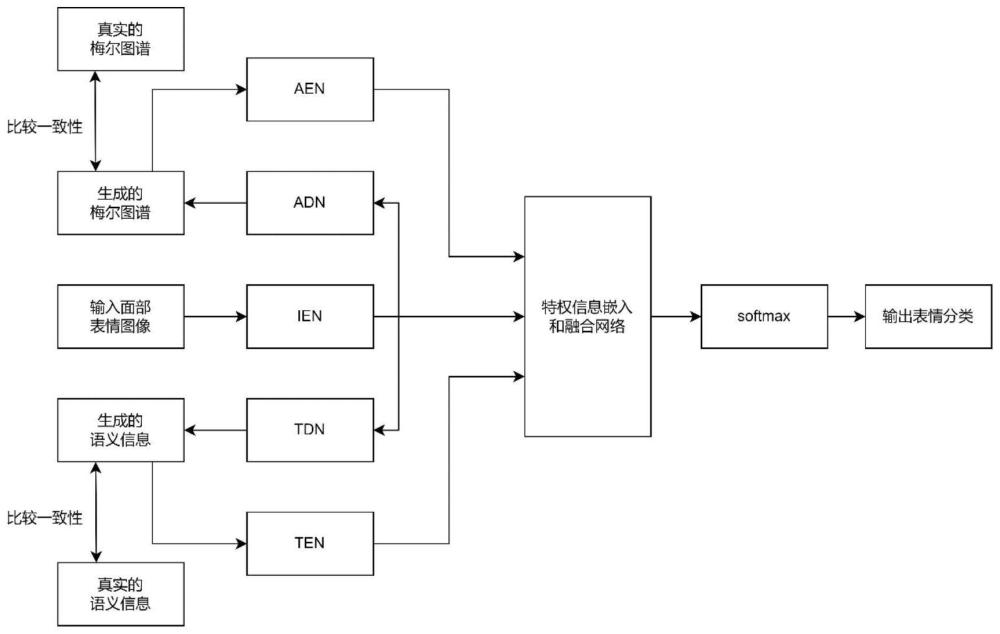
4、步骤2:特权信息是指在训练时可用,测试时不可用的信息,用以指导特征提取,将梅尔图谱和语义张量作为表情图像的特权信息,构建端到端可训练的异构神经网络模型mpi-fer,进行多模态数据间的表观迁移,利用情感特征辅助提升表情识别的性能;
5、步骤3:训练阶段,图像数据经过编码单元后,得到图像情感特征,所述图像情感特征经过语音解码和文本解码重建为对应的梅尔图谱和语义特征,显示地构建数据重建的外观投影模型,隐式地提升图像编码器对图像数据中情感特征的提取能力,嵌入特权信息;
6、步骤4:将步骤3中重建的梅尔图谱和语义特征进行编码操作,得到语音情感特征和文本情感特征,再结合由图像编码单元得到的图像情感特征,输入到多模态融合单元中,进行基于跨模态注意力和自注意力机制的融合,得到最终的表情分类预测;
7、步骤5:测试阶段,仅需输入一张人脸表情图像,首先根据步骤1仅对输入的所述人脸表情图像进行预处理,再输入到异构神经网络模型mpi-fer中生成另外两个模态的数据梅尔图谱和语义信息,然后对三种模态的数组进行编码并进行基于跨模态注意力和自注意力机制的融合,最终得到该人脸表情图像的表情类别。
8、作为本发明进一步的改进,所述异构神经网络模型mpi-fer包括图像-语音表观迁移模块ia-rtm,包括图像编码网络ien和经过梅尔图谱上采样网络and;图像-文本表观迁移模块it-rtm,包括图像编码网络ien和编码-解码网络tdn、多模态情感特权信息嵌入模块ms-pim包括图像编码网络ien、语音编码网络aen、文本编码网络ten和基于跨模态注意力和自注意力机制的融合网络;
9、作为本发明进一步的改进,在步骤1中的多模态情感数据作为训练阶段网络的输入,其中,人脸表情图像作为图像编码网络ien的输入,经过梅尔图谱上采样网络adn生成的梅尔图谱与真实的梅尔图谱进行语义一致性比较,之后作为语音编码网络aen的输入,进行语音特征提取;经过编码-解码网络tdn生成的语义信息与真实的语义信息进行语义一致性比较,之后作为文本编码网络ten的输入,进行语义特征提取;而在测试阶段,生成的梅尔图谱和语义信息则无需进行语义一致性比较,直接进行特征提取。
10、作为本发明进一步的改进,图像编码网络ien和语音编码网络aen是基于resnet18的图像特征提取网络,用于提取面部表情和梅尔图谱的特征,图像编码网络ien和语音编码网络aen均由13个卷积层、2个池化层、1个激活函数、1个归一化层堆叠而成;语义信息特征提取网络ten用于提取语义信息的特征,由2个卷积层、2个归一化层、2个激活函数堆叠而成;梅尔图谱上采样网络adn,用于对人脸表情特征进行上采样生成梅尔图谱,由4个上采样层、1个卷积层和1个激活函数堆叠而成;使用全连接层和激活函数堆叠而成的编码-解码网络tdn,用于从人脸表情特征中重建语义信息,由4个卷积层、5个全连接层和4个激活函数堆叠而成。
11、作为本发明进一步的改进,所述步骤2中的多模态情感特权信息嵌入模块,包括图像编码网络ien、语音编码网络aen、语义信息特征提取网络ten和基于跨模态注意力和自注意力机制的融合网络组成,其中基于跨模态注意力和自注意力机制的融合网络主要由6个跨模态注意力编码器和12个自注意力编码器组成;经过跨模态注意力编码网络计算得到两种模态特征之间的跨模态注意力分数,然后利用另一模态的特征强化目标模态的特征,实现多模态融合;最终,三种模态的输出经过相加或者拼接经由一个全连接层和softmax层输出预测结果。
12、作为本发明进一步的改进,对于模型的训练是一种多任务学习,一个学习目标是使由人脸表情图像经过编码和解码生成的梅尔图谱、语义信息和真实的梅尔图谱、语义信息相一致,分别对生成和真实的梅尔图谱、语义信息计算mse损失;另一个学习目标则是使多模态特征融合后的预测结果与人脸图像的表情类别相一致,对模型预测结果和真实表情标签计算交叉熵损失,多个损失函数相加构成最终的损失函数结果。
13、作为本发明进一步的改进,所述步骤4中,多模态情感数据经过各自的特征提取,输入到基于跨模态注意力和自注意力机制的融合网络中,最终得到该组数据预测为每种表情的概率值,如果最大概率对应的表情类别与真实类别相同,则说明预测正确,最终得到该表情图像的分类准确率,即正确预测数量与总预测数量之比。
14、本发明的另一目的在于提供一种面部表情识别系统,用于上述的方法。
15、本发明的有益效果是包括:引入特权信息嵌入机制,特权信息的嵌入对单模态数据起到了重要的补充作用,在实际测试和推理过程中,只需要输入一张人脸表情图像,即可生成对应的近似的梅尔图谱和语义信息,有效地解决了多模态识别任务中,因缺乏某种模态的数据而无法继续开展任务的难题、图像编码网络ien参数的更新受多种损失函数反向传播的影响,因此在更新权重时会更加向最优结果逼近,通过显示地建立由图像数据到语音、语义数据的外观投影模型,隐式地提升图像编码器对图像数据中情感特征的提取能力,从而将语音、语义数据中包含的情感信息嵌入到对于人脸图像中的表情特征学习中,提取更加有效的特征。特征融合部分通过跨模态注意力机制,有效地学习了不同模态特征之间的互补关系和关联性,实现多种模态的数据融合;通过自注意力机制,有效的学习了特征各部分之间的关系从而识别出输入中最具判别力的部分,减少了非限制环境下大量干扰对表情识别准确率的影响。全连接层和softmax层可以有效地融合从多模态情感数据特征输入到基于跨模态注意力和自注意力机制的融合网络中学习到的互补特征。总而言之,本发明提出的特权信息嵌入和注意力融合机制显著提高了非实验室环境下单模态表情识别的准确率,在ch-sims和cmu-mosi两个多模态情感识别数据集上取得了较高的准确率,并在raf-db和affectnet两个真实环境下单模态表情识别数据集上取得了显著优于baseline的结果,有效的改善了单模态表情识别的现状。
- 还没有人留言评论。精彩留言会获得点赞!