一种鲁棒稳健的医学图像半监督分类方法
本发明属于深度学习,具体涉及基于深度学习的医学图像分析领域,特别是半监督学习和噪声标签学习技术,尤其是一种鲁棒稳健的医学图像半监督分类方法。
背景技术:
1、现有基于深度学习的医学图像分类方法有两个瓶颈问题亟待解决,即较少的样本量和数据集中存在标签噪声。由于医学图像的特殊性,医学数据集样本量较少,且由于医学图像相近类别之间的特征相似性较高,在专家对相关数据集进行标注时,容易出现标签噪声,单独的半监督分类算法或者是标签噪声学习方法分类性能不稳定。现有技术如基于伪标签的半监督分类方法和标签噪声学习方法可以初步解决这两个问题。
2、现有技术公开的有:基于伪标签的半监督算法,其主要思想是用未标记的数据集来扩充已标记的数据集。首先利用标记数据训练一个分类模型,然后将无标注数据输入模型后可以得到模型预测的标签,作为伪标签。将无标注数据加上伪标签后与原始的标记数据相结合,并在合并后数据上进行联合训练,主流的方法有self-training、fixmatch、flexmatch和faxmatch。
3、在图像分类任务中,当数据集中存在标记噪声时,生成的伪标签的置信度不可靠,会影响最终的训练效果。为了解决图像分类任务中的带噪声标签学习问题,一种主流方法是减少错误积累,如co-teaching、reweight和dividemix,另一种主流方法是纠正噪声标签,如pencil。但是,由于医学图像存在样本稀缺和标注质量不足的问题,需要同时执行两项任务才能取得较好的效果。在医学图像分类任务中,协同校正的方法可以同时解决两个问题。然而,当标注样本数量不足时,其效果并不确定,而且这种方法无法利用未标注数据进行有效学习。因此,需要一种能有效处理标记噪声的医学图像半监督分类方法。
技术实现思路
1、发明目的:针对上述现有技术的不足,本发明提供一种鲁棒稳健的医学图像半监督分类方法。
2、技术方案:一种鲁棒稳健的医学图像半监督分类方法,包括如下步骤:
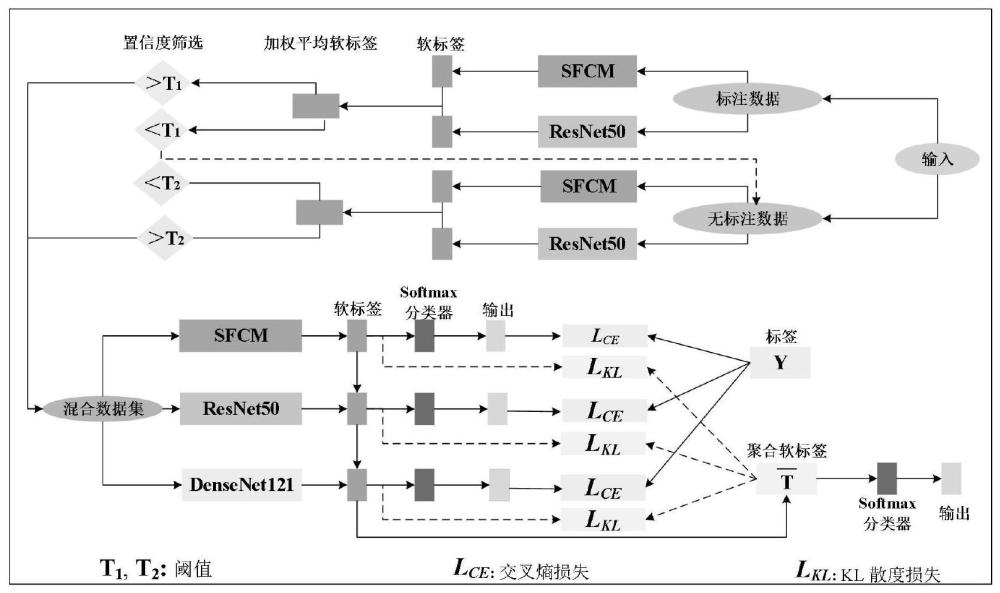
3、s1、基于伪标签的半监督学习方法进行训练,包括采用未标记数据以在扩大训练样本,提高伪标签数据的质量;
4、s2、基于sfcm和cnn模型构建置信度筛选模型,所述置信度筛选模型是通过计算由sfcm和cnn分类模型生成的软标签的加权平均值,与设定的阈值进行对比后过滤出噪声数据;
5、对于标注数据,置信度高于设定阈值的数据被添加到混合数据集,置信度低于设定阈值的数据作为非标注数据继续用于训练;
6、对于无标注数据,置信度高于设定阈值的伪标签数据被添加到混合数据集中;
7、所述的sfcm模型基于一种标签分配策略,利用基于模糊c均值fcm模型生成的隶属度得出软标签用于后续的置信度筛选;
8、s3、基于sfcm、densenet121和resnet50三个学生模型组成三分支的模糊半监督蒸馏模型fsd-net,由此实现多模型在线蒸馏分类,并将三个模型的加权平均软标签作为教师知识来指导学生训练。
9、进一步的,步骤s2包括采用独立成分分析法对医学图像数据进行预处理,用于提高聚类效果,具体包括对数据进行特征提取,然后对输入的数据的特征进行去均值处理以实现标准化,最后是对输入数据的特征进行主成分分析处理,然后对其进行白化。
10、更进一步的,步骤s2所述的标签分配策略还包括如下的操作:
11、固定簇心的数量与数据总类别一致,通过设置一个隶属度阈值,得到每个簇心在设定的隶属度阈值范围内的数据总量,通过计算该簇心内占比最多的数据类别,并设定该类别的标签为簇心的标签;
12、标签分配策略中不断增大设定的隶属度阈值,直到最终得到各个簇的标签,由此避免数据类别不平衡可能带来的标签重复问题。
13、步骤s2具体的计算过程包括:
14、s21、利用fcm分类模型对医学图像数据的数据特征进行聚类,避免标签噪声的负面影响,计算如下:
15、输入x={x1,x2,...,xn}分配到c聚类中心{v1,v2,...,vc},fcm目标函数为:
16、
17、其中约束函数为uij表示样本xi属于j类样本的隶属度并且uij≥0,||·||表示欧几里得距离,m为加权指数且1≤m≤∞;
18、通过拉格朗日乘子法,进一步推导出迭代方程:
19、
20、
21、其中,c为簇数,fcm会不断地更新权重,即隶属度,直到小于设定的阈值后就会停止;
22、步骤s21基于无监督聚类模型fcm改进得到软模糊c均值模型sfcm,对sfcm和分类模型生成的加权平均软标签进行置信度过滤,初步过滤出噪声数据;
23、s22、根据cnn分类模型,其中logits是神经网络倒数第二层的输出,假设学生网络输入xi的logits为其中h是类别总数;通过如下公式计算归一化分类概率:
24、
25、软标签能赋予模型更强的泛化能力,对噪声的鲁棒性也更强;
26、教师模型和学生模型的软标签计算方法如下:
27、
28、其中参数t是温度参数,用于提高软标签的松弛程度;
29、s23、将sfcm与cnn模型相结合,通过对两个模型的软标签进行加权平均,与设定的阈值对比后进行数据筛选,软标签的计算包括:
30、给定输入x,对应的软标签为(y1,y2,...,yc),c为类别数,且sfcm的软标签为(y'1,y'2,...,y'c),
31、最终的软标签通过以下方式计算:
32、y(x)=α.yc+(1-α).y'c,
33、其中,α是权重参数。
34、进一步的,步骤s3具体计算包括:
35、s31、收集所有学生模型的软标签,并通过计算加权平均值对其进行汇总,汇总后的软标签用于指导学生训练,其计算公式如下:
36、
37、其中,是第m个学生的软标签,m是学生模型的数量,wm是权重,vm是每个学生模型生成的准确率;
38、s32、在三个分支中进行独立训练,采用标准的交叉熵损失来优化分类分支的训练;
39、其中在更新簇的过程中,sfcm也被用作一个监督模型,其定义如下:
40、
41、其中,q是训练样本总数,是第q个样本的基本真实值,是每个分类分支对第q个样本的预测概率;
42、s33、计算和的kl-loss来使得学生模型向教师模型学习并优化,该方法中中教师知识是三个学生模型结果的加权平均值,
43、第m个学生的kl-loss计算公式和总分类损失如下:
44、
45、其中,是第h个类别的样本在第m个学生模型中预测出的软标注概率。
46、有益效果:与现有技术相比,本发明所提供的一种鲁棒稳健的医学图像半监督分类方法,可以在一定程度上缓解样本数量不足对分类结果的影响,同时可以避免噪声标签对分类结果的干扰,有效提高医学图像分类的鲁棒性和稳健性。
- 还没有人留言评论。精彩留言会获得点赞!