文博领域知识问答方法及装置、设备和介质与流程
本发明涉及人工智能,具体地涉及一种文博领域知识问答方法、装置、设备、介质和程序产品。
背景技术:
1、大语言模型通常是在海量无标注的数据上进行预训练,学习总结文本数据内部的规律及特征,参数量巨大,也因此需要强大的算力支撑,在基础大语言预训练模型的基础上,经过有监督的微调,使用指令微调、rlhf(人工反馈强化学习)等技术进行人类意图对齐,使大语言模型能适应多个场景应用,及接受提示词,根据提示词生成回答。
2、但是,目前大语言模型在文博领域中的应用存在一些缺陷:例如,一般大语言模型更偏向的是通用领域,力求统一、所有问题都能回答,所以在文博领域上的效果较差,细节知识难以知晓,并且训练一个大语言基础模型需要消耗的成本较大,部分文博知识样本难以获取等,导致了针对文博领域训练完全统一的大模型是不可行的。
技术实现思路
1、鉴于上述问题,本发明提供了一种文博领域知识问答方法、装置、设备、介质和程序产品。
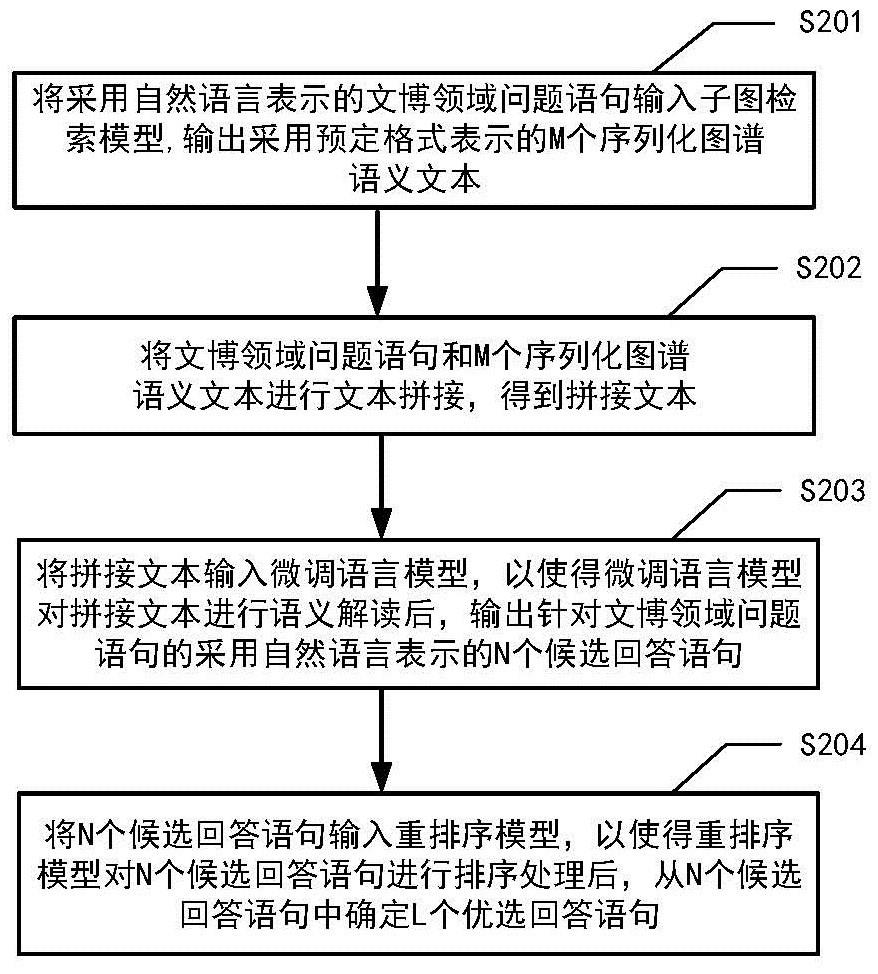
2、本发明的一个方面,提供了一种文博领域知识问答方法,包括:
3、将采用自然语言表示的文博领域问题语句输入子图检索模型,以使得子图检索模型从文博领域知识图谱中检索得到与文博领域问题语句相关的m个知识子图谱,并将m个知识子图谱进行预定格式的序列化格式转换后,输出采用预定格式表示的m个序列化图谱语义文本,其中,m个序列化图谱语义文本用于表征m个知识子图谱的图谱语义含义;
4、将文博领域问题语句和m个序列化图谱语义文本进行文本拼接,得到拼接文本;
5、将拼接文本输入微调语言模型,以使得微调语言模型对拼接文本进行语义解读后,输出针对文博领域问题语句的采用自然语言表示的n个候选回答语句;
6、将n个候选回答语句输入重排序模型,以使得重排序模型对n个候选回答语句进行排序处理后,从n个候选回答语句中确定l个优选回答语句。
7、根据本发明的实施例,序列化图谱语义文本表征的图谱语义含义包括各个知识子图谱的三元组实体关系含义,以及多个知识子图谱彼此之间的关联关系含义。
8、根据本发明的实施例,预定格式包括:
9、用于表征知识子图谱中包含的实体数据的第一格式符;
10、用于表征知识子图谱中实体之间关系的第二格式符;
11、用于表征知识子图谱中三元组开始位置的第三格式符;
12、用于表征知识子图谱中三元组结束位置的第四格式符;
13、用于表征知识子图谱开始位置的第五格式符;
14、用于表征知识子图谱结束位置的第六格式符;
15、其中,第一格式符、第二格式符、第三格式符、第四格式符用于表征知识子图谱的三元组实体关系含义,第五格式符、第六格式符用于表征多个知识子图谱彼此之间的关联关系。
16、根据本发明的实施例,重排序模型包括特征提取层、特征融合层、结果映射层。
17、根据本发明的实施例,子图检索模型是利用与第一预定知识图谱样本关联的多个第一问题样本,以及与多个第一问题样本关联的采用预定格式表示的多个第一序列化图谱语义样本训练得到的,其中,第一序列化图谱语义样本是对与多个第一问题样本关联多个第一相关子图谱样本组进行预定格式的序列化格式转换后得到的,多个第一相关子图谱样本组源自于第一预定知识图谱样本,第一预定知识图谱样本至少包括文博领域知识图谱。
18、根据本发明的实施例,子图检索模型通过以下方法训练得到:
19、获取第一预定知识图谱样本,其中,第一预定知识图谱样本包括文博领域知识图谱,或者第一预定知识图谱样本包括通用领域知识图谱和文博领域知识图谱;
20、将第一预定知识图谱样本进行文本化处理,得到多个第一三元组文本,其中,每个第一三元组文本对应于第一预定知识图谱样本中的一个第一知识图谱三元组样本;
21、将多个第一三元组文本输入三元组关联模型,输出多个第一三元组文本彼此之间的相似度值;
22、根据多个第一三元组文本彼此之间的相似度值,将与多个第一三元组文本关联的多个第一知识图谱三元组样本进行相似度分组,得到多个第一相关子图谱样本组;
23、对多个第一相关子图谱样本组进行预定格式的序列化格式转换,得到多个第一序列化图谱语义样本;
24、利用微调语言模型对多个第一序列化图谱语义样本进行提问,得到多个第一问题样本;
25、利用多个第一问题样本和多个第一序列化图谱语义样本训练得到子图检索模型。
26、根据本发明的实施例,三元组关联模型通过以下方法训练得到:
27、获取多个三元组样本;
28、从多个三元组样本中确定多个第一三元组样本并标记第一三元组样本,其中,多个第一三元组样本彼此之间的相似度满足预设相似条件;
29、从多个三元组样本中确定多个第二三元组样本,其中,第二三元组样本为:与第一三元组样本存在节点关联关系且未被标记的三元组样本;
30、以多个第一三元组样本作为正样本,以多个第二三元组样本作为负样本,对基础文本相似度模型进行对比学习训练,得到初始三元组关联模型;
31、利用初始三元组关联模型,对多个第三三元组样本进行相似度预测,并根据预测结果确定多个第一预测样本,其中,多个第一预测样本彼此之间的相似度满足预设相似条件,第三三元组样本为未被标记的三元组样本;
32、利用初始三元组关联模型,对多个第一三元组样本进行相似度预测,并根据预测结果确定多个第二预测样本,其中,多个第二预测样本彼此之间的相似度不满足预设相似条件;
33、利用多个第一三元组样本、多个第一预测样本、多个第二预测样本作为训练样本,对初始三元组关联模型进行多次迭代对比学习训练,得到训练得到的三元组关联模型。
34、根据本发明的实施例,对初始三元组关联模型进行对比学习训练包括:
35、计算综合对比损失,其中,综合对比损失包括基于多个第一三元组样本计算得到的第一对比损失,以及基于多个第一预测样本和多个第二预测样本计算得到的第二对比损失,第一对比损失的权重高于第二对比损失的权重;
36、根据综合对比损失调整初始三元组关联模型的模型参数。
37、根据本发明的实施例,微调语言模型通过以下方法训练得到:
38、获取采用通用领域知识图谱的第二预定知识图谱样本、与通用领域知识图谱对应的图谱来源文本、预定指令库样本,其中,预定指令库样本包括基于通用领域知识和文博领域知识的多个标准问答对;
39、基于第二预定知识图谱样本得到多个第二知识图谱三元组样本;
40、对多个第二知识图谱三元组样本中的子图谱进行预定格式的序列化格式转换,得到多个第二序列化图谱语义样本;
41、修改预训练语言模型的模型词表,在模型词表中添加自定义图谱语义词的映射关系,其中,自定义图谱语义词包括第一格式符、第二格式符、第三格式符、第四格式符、第五格式符、第六格式符;
42、利用多个第二序列化图谱语义样本、图谱来源文本、预定指令库样本作为训练样本,采用多任务训练方式,训练被修改模型词表的预训练语言模型,得到训练得到的微调语言模型。
43、根据本发明的实施例,训练被修改模型词表的预训练语言模型包括:
44、将图谱来源文本输入预训练语言模型,利用预训练语言模型进行信息抽取,输出与第二序列化图谱语义样本的表达形式相同的参考序列化图谱语义样本,并以第二序列化图谱语义样本作为标签,训练预训练语言模型的信息抽取能力;
45、将第二序列化图谱语义样本输入预训练语言模型,利用预训练语言模型进行信息还原,输出与图谱来源文本的表达形式相同的参考语句样本,并以图谱来源文本作为标签,训练预训练语言模型的信息还原能力;
46、将第二序列化图谱语义样本和预定指令库样本输入训练之前的预训练语言模型,输出第一结果语句;
47、将第二序列化图谱语义样本和预定指令库样本输入训练中的预训练语言模型,输出第二结果语句;
48、以第一结果语句作为第二结果语句的约束,调整训练中的预训练语言模型的模型参数,得到训练得到的微调语言模型。
49、根据本发明的实施例,重排序模型通过以下方法训练得到:
50、获取第三预定知识图谱样本,其中,第三预定知识图谱样本包括通用领域知识图谱和/或文博领域知识图谱;
51、将第三预定知识图谱样本进行文本化处理,得到多个第二三元组文本,其中,每个第二三元组文本对应于第三预定知识图谱样本中的一个第三知识图谱三元组样本;
52、将多个第二三元组文本输入三元组关联模型,输出多个第二三元组文本彼此之间的相似度值;
53、根据多个第二三元组文本彼此之间的相似度值,将与多个第二三元组文本关联的多个第三知识图谱三元组样本进行相似度分组,得到多个第二相关子图谱样本组;
54、对多个第二相关子图谱样本组进行预定格式的序列化格式转换,得到多个第三序列化图谱语义样本;
55、利用微调语言模型对多个第三序列化图谱语义样本进行提问,得到多个第二问题样本;
56、利用微调语言模型对多个第二问题样本进行作答,得到多个回答样本;
57、对多个回答样本标注用于表征回答好坏的序列标签;
58、以多个第二问题样本、多个第三序列化图谱语义样本、多个回答样本、多个回答样本的序列标签作为训练样本,训练得到重排序模型。
59、本发明的另一个方面提供了一种文博领域知识问答装置,包括:
60、子图检索模块,用于将采用自然语言表示的文博领域问题语句输入子图检索模型,以使得子图检索模型从文博领域知识图谱中检索得到与文博领域问题语句相关的m个知识子图谱,并将m个知识子图谱进行预定格式的序列化格式转换后,输出采用预定格式表示的m个序列化图谱语义文本,其中,m个序列化图谱语义文本用于表征m个知识子图谱的图谱语义含义;
61、拼接模块,用于将文博领域问题语句和m个序列化图谱语义文本进行文本拼接,得到拼接文本;
62、回答模块,用于将拼接文本输入微调语言模型,以使得微调语言模型对拼接文本进行语义解读后,输出针对文博领域问题语句的采用自然语言表示的n个候选回答语句;
63、排序模块,用于将n个候选回答语句输入重排序模型,以使得重排序模型对n个候选回答语句进行排序处理后,从n个候选回答语句中确定l个优选回答语句。
64、本发明的另一个方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行上述文博领域知识问答方法。
65、本发明的另一个方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述文博领域知识问答方法。
66、本发明的另一个方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述文博领域知识问答方法。
67、为解决相关技术中语言模型在文博领域应用上的限制,本发明实施例的上述方法通过先利用子图检索模型从文博领域知识图谱中检索得到与文博领域问题语句相关知识子图谱,进行文本格式转换后,利用微调语言模型进行语义解读可得到针对问题的回答。因文博领域知识图谱可以描述文博知识和建模世界万物之间的关联关系,包含丰富的文博知识信息种类,通过先利用子图检索模型从文博领域知识图谱中检索得到与文博领域问题语句相关知识子图谱,可弥补语言模型在文博领域使用时掌握知识不全面,细节不充分等技术缺陷;之后,利用微调语言模型进行语义解读可得到针对问题的优势回答,进一步通过重排序模型对多个回答进行了进一步的筛选,得到的最终回答符合用户期望,回答准确性高,人性化程度高。可见,通过子图检索模型、语言模型、以及重排序模型的协同融合,可使大语言模型能够更好地应用于文博领域,有效缓解大语言模型在文博领域的幻觉现象,提升基于知识图谱问答的泛化能力,增加大模型生成回答的可解释性。
- 还没有人留言评论。精彩留言会获得点赞!