基于大模型和知识指导的法律问答方法和装置
本技术涉及法律,尤其涉及基于大模型和知识指导的法律问答方法和装置。
背景技术:
1、搭建特定领域知识问答系统通常有两种技术路线:一种是基于领域数据集构建法律垂直领域模型,另一种是基于大语言模型进行二次加工。
2、基于领域数据集构建法律垂直领域模型,通常是构建本地化的法律知识库,采用构建本地化的法律问答数据集的方式,预设法律咨询相关联的问题,构建问题数据集的向量(embeddings)索引,将用户的问题文本通过bert等深度学习模型生成句意向量,使用向量索引检索与问题句意向量最相似的目标问题,并在问答数据集中匹配到对应的答案,将答案返回给用户。
3、基于大语言模型使用领域知识对基础模型进行微调(fine-tuning),改变神经网络中参数权重,或通过提示工程(prompt engineering)将特定领域知识作为输入消息提供给模型,模型对生成的文本融入领域知识后将答案返回给用户。
4、基于领域数据集进行模型训练,存在以下问题:1.通常需要大规模标注数据和复杂的特征工程,模型性能受限于训练数据和特征工程的质量,对于小规模数据集的性能可能不佳;2.现有法律数据集在法律领域的知识覆盖度不足,无法很好覆盖广泛的领域知识,模型在语义理解和和处理复杂问题方面效果有限;3.大多依赖模板或知识库,问答的范围受限,通常只能应对特定和相对简单的法律问题,难以应对更为复杂的法律场景。
5、基于大语言模型的技术方案,存在以下问题:1.可以处理广泛的通用问题,但对于特定领域的专业性表现不佳,尤其是特定区域的法律领域;2.生成式模型普遍存在幻觉问题,生成的答案文本通常缺乏详细的解释和依据,可能存在编造法条或司法解释的情况,难以满足法律场景中对于生成内容的专业性和准确性的要求;3.对于模型微调,使用下游特定领域知识对基础模型进行微调,需要构建法律领域微调的训练语句,模型效果可能对特定法律场景的回答表现好,但对于其他复杂场景不一定符合预期;4.模型微调消耗的资源成本较高,而且法学领域知识更新频繁,需要较高的实时性,无法满足多样化法律场景需求;5.对于提示工程,通常会采用few-shot、zero-shot或cot等方式,但是该方法单次可以处理的文本量有限制,而法律知识内容较多,影响生成效率。
技术实现思路
1、本技术旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本技术的第一个目的在于提出一种基于大模型和知识指导的法律问答方法,解决了现有方法无法满足多样化法律场景需求的技术问题,能够满足多样化和复杂的法律问答需求,具有较高的专业性、准确性和可信度。
3、本技术的第二个目的在于提出一种基于大模型和知识指导的法律问答装置。
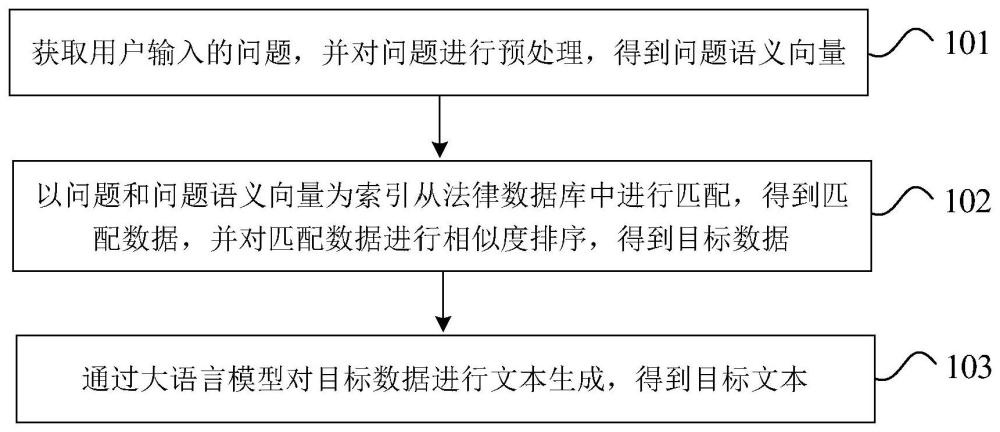
4、为达上述目的,本技术第一方面实施例提出了一种基于大模型和知识指导的法律问答方法,包括:获取用户输入的问题,并对问题进行预处理,得到问题语义向量;以问题和问题语义向量为索引从法律数据库中进行匹配,得到匹配数据,并对匹配数据进行相似度排序,得到目标数据;通过大语言模型对目标数据进行文本生成,得到目标文本。
5、本技术实施例的基于大模型和知识指导的法律问答方法,通过对用户输入的法律问题进行理解和分析,在生成回答时能够给出相关的法律依据和解释,有效减少领域知识不足和大模型幻觉问题,使得生成的回答具有较高的专业性、准确性和可信度,能够满足多样化和复杂的法律问答需求。
6、可选地,在本技术的一个实施例中,法律数据库为与法律相关的文本数据库,法律数据库包括法律问答数据、法律法规、司法解释、裁判文书数据、文书合同模板、法学书籍。
7、可选地,在本技术的一个实施例中,以问题和问题语义向量为索引从法律数据库中进行匹配,得到匹配数据,包括:
8、采用召回算法根据问题语义向量进行相似度的topk的向量索引召回,并采用召回算法根据问题进行相似度的topk的全文索引召回,得到召回法律文本;
9、将召回法律文本作为匹配数据。
10、可选地,在本技术的一个实施例中,采用召回算法根据问题语义向量进行相似度的topk的向量索引召回,包括:
11、计算问题语义向量和法律数据库中法律文本向量的余弦相似度,得到top k1相似的法律文本;
12、采用召回算法根据问题进行相似度的topk的全文索引召回,包括:
13、计算问题文本和法律数据库中法律文本的文本相似度,得到top k2相似的法律文本;
14、召回法律文本的生成过程包括:
15、将top k1相似的法律文本和top k2相似的法律文本合并后去重得到召回法律文本。
16、可选地,在本技术的一个实施例中,通过大语言模型对目标数据进行文本生成,得到目标文本,包括:
17、通过prompt工程,将问题和匹配数据作为prompt输入到大语言模型中,生成目标文本。
18、为达上述目的,本发明第二方面实施例提出了一种基于大模型和知识指导的法律问答方法,包括问题输入模块、数据获取模块、文本生成模块,其中,
19、问题输入模块,用于获取用户输入的问题,并对问题进行预处理,得到问题语义向量;
20、数据获取模块,用于以问题和问题语义向量为索引从法律数据库中进行匹配,得到匹配数据,并对匹配数据进行相似度排序,得到目标数据;
21、文本生成模块,用于通过大语言模型对目标数据进行文本生成,得到目标文本。
22、可选地,在本技术的一个实施例中,法律数据库为与法律相关的文本数据库,法律数据库包括法律问答数据、法律法规、司法解释、裁判文书数据、文书合同模板、法学书籍。
23、可选地,在本技术的一个实施例中,以问题和问题语义向量为索引从法律数据库中进行匹配,得到匹配数据,包括:
24、采用召回算法根据问题语义向量进行相似度的topk的向量索引召回,并采用召回算法根据问题进行相似度的topk的全文索引召回,得到召回法律文本;
25、将相似度最高的法律文本和召回法律文本作为匹配数据。
26、可选地,在本技术的一个实施例中,采用召回算法根据问题语义向量进行相似度的topk的向量索引召回,包括:
27、计算问题语义向量和法律数据库中法律文本向量的余弦相似度,得到top k1相似的法律文本;
28、采用召回算法根据问题进行相似度的topk的全文索引召回,包括:
29、计算问题文本和法律数据库中法律文本的文本相似度,得到top k2相似的法律文本;
30、召回法律文本的生成过程包括:
31、将top k1相似的法律文本和top k2相似的法律文本合并后去重得到召回法律文本。
32、可选地,在本技术的一个实施例中,通过大语言模型对目标数据进行文本生成,得到目标文本,包括:
33、通过prompt工程,将问题和匹配数据作为prompt输入到大语言模型中,生成目标文本。
34、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!