一种基于水泥价格指数的多源数据清洗方法与流程
本发明涉及数据处理,具体涉及一种基于水泥价格指数的多源数据清洗方法。
背景技术:
1、水泥价格指数是反映水泥行业价格行情波动情况的经济指标。水泥价格指数与各类水泥品牌在每个地级行政区的产能占有率、每个地级行政区的预拌混凝土消费量、固定资产投资、水泥产量以及各品牌、各地级行政区的权重等数据有关。品牌权重、地级行政区权重等数据是动态变化的,因此,更新水泥价格指数时需要考虑品牌权重、地级行政区权重等数据的变化量。但水泥价格指数的计算依据的是全国数百个水泥品牌以及数百个地级行政区的权重等相关数据,且部分数据并非为能够直接获取的直接数据,而是需要依赖基础数据计算的间接数据,这些间接数据又增加了变化量计算对象的数量,所以,无论是对直接数据进行变化量计算,还是对间接数据进行变化量计算,每次更新指数的计算量庞大且耗时。最为关键的是,由于水泥价格指数的更新频率为每日,当日用于更新指数的数据相比较前一日的数据中存在大量的相同或相似数据,这些数据对于水泥价格指数的变化量影响程度较低,因此计算这些相同或相似数据的变化量意义不大。但数据相同或相似不能简单以数据值的变化量大小来判断,因为不同数据对于水泥价格指数的影响程度并不相同,部分数据前后变化量虽较大,但对于水泥价格指数计算的影响程度较小,仍可视为相同或相似数据,但部分数据前后变化量虽较小,但对于水泥价格指数计算的影响程度较高,则应当视为不相同或不相似的数据。因此首先需要一套合适的数据清洗算法,从大量的数据中精准识别出相同或相似的数据,以及减少更新水泥价格指数时的计算量。
2、另外,由于数据清洗对象过多,本领域技术人员期待能够对大量数据进行并行的数据清洗,但具体如何实现对影响水泥价格指数的数据的并行清洗时本领域需要解决的第二个技术问题。
3、此外,能够适用水泥价格指数的数据清洗的算法有许多,各种清洗算法各有优劣,算法本身也是影响水泥价格指数更新准确性的关键,且不同的算法在不同的时间点针对不同的清洗对象的优劣性也在动态变化,因此如何从多种清洗算法中筛选出当前清洗时间点最合适的算法是本发明需要解决的第三个技术问题。特别是,如何依据并行清洗对象的不同数据类型或数据特点,实现对不同清洗算法的并行筛选是重点需要解决的技术问题。
技术实现思路
1、本发明以实现对清洗算法的自适应并行筛选,并以并行筛选的算法精准识别出相同或相似的重复数据并过滤,以减少水泥价格指数更新时的计算量,提高水泥价格指数更新速度为目的,提供了一种基于水泥价格指数的多源数据清洗方法。
2、为达此目的,本发明采用以下技术方案:
3、提供一种基于水泥价格指数的多源数据清洗方法,包括步骤:
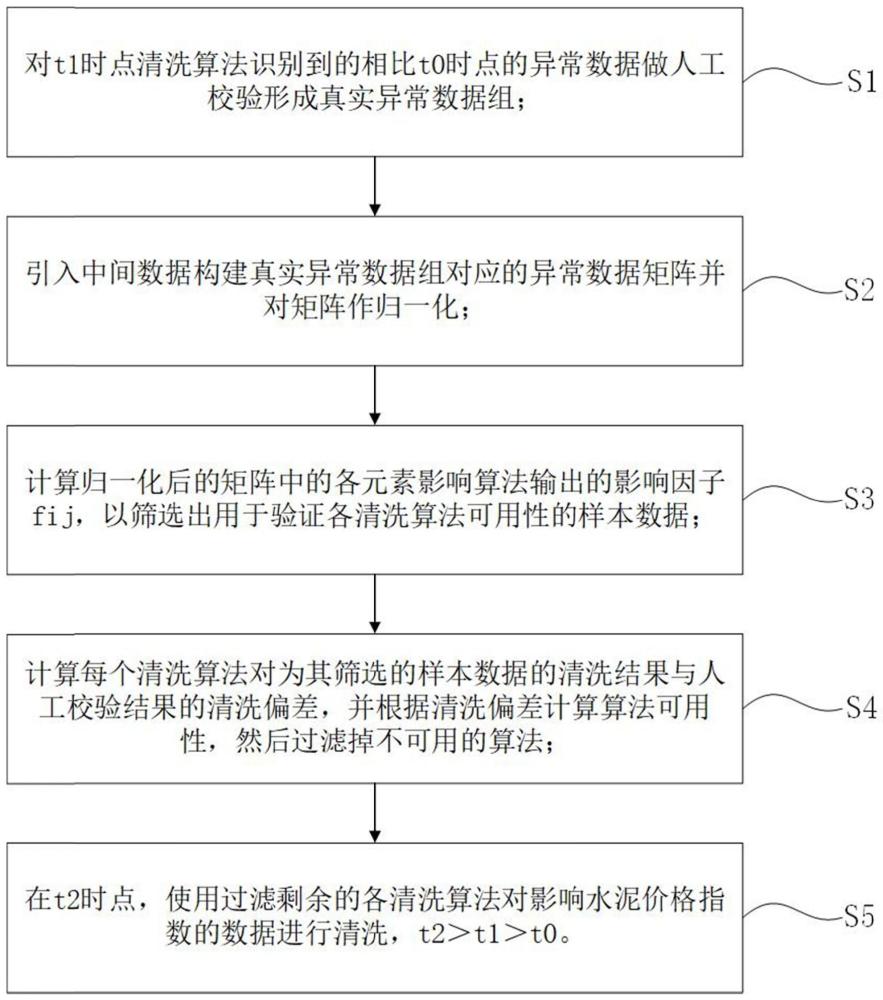
4、s1,对t1时点清洗算法识别到的相比t0时点的异常数据做人工校验形成真实异常数据组;
5、s2,引入中间数据构建所述真实异常数据组对应的异常数据矩阵并对矩阵作归一化;
6、s3,计算归一化后的矩阵中的各元素影响算法输出的影响因子fij,以筛选出用于验证各所述清洗算法可用性的样本数据;
7、s4,计算每个所述清洗算法对为其筛选的所述样本数据的清洗结果与人工校验结果的清洗偏差,并根据清洗偏差计算算法可用性,然后过滤掉不可用的算法;
8、s5,在t2时点,使用过滤剩余的各所述清洗算法对影响水泥价格指数的数据进行清洗;
9、t2>t1>t0。
10、作为优选,所述真实异常数据组包括所述异常数据、所述清洗算法和人工对所述清洗算法针对所述异常数据输出的清洗结果的校正结果。
11、作为优选,步骤s2具体包括步骤:
12、s21,构建引入所述中间数据的如下式表达的所述异常数据矩阵:
13、
14、矩阵i包括第一子矩阵和第二子矩阵和表示所述中间数据,r表示地级行政区s中的水泥品牌数量,表示地级行政区s内第r个品牌对应的第一真实异常数据组中的第n个第一异常数据,表示级行政区s对应的第二真实异常数据组中的第n个第二异常数据;
15、s22,对所构建的所述异常数据矩阵进行归一化,归一化方法如下式(1)表达:
16、
17、公式(1)中,iij表示所述异常数据矩阵中的第i行的第j个元素。
18、作为优选,所述中间数据为地级行政区平均价格通过如下公式(2)计算:
19、
20、公式(2)中,b表示地级行政区中的水泥品牌b;
21、b表示所述地级行政区中的水泥品牌数量;
22、pb为品牌b在所述地级行政区的水泥产品价格;
23、wb为pb在计算时的品牌权重。
24、作为优选,步骤s3具体包括步骤:
25、s31,构建矩阵元素偏差列表,构建方法为:
26、计算归一化后的归一化矩阵中的每个元素i′ij与所述中间数据的归一化值i′i1的距离偏差绝对值dij,并按值由小到大排列为偏差列表,dij=|i′ij-i′i1|,为所述中间数据的归一化值;
27、s32,计算偏差列表中的每个元素影响相应算法输出的影响因子fij;
28、s33,对fij由大到小排列形成fij值列表,然后抽取出fij值列表中排序前m的fij值对应的在t1时点产生的各所述异常数据作为验证相应的所述清洗算法的可行性的所述样本数据。
29、作为优选,步骤s32中,通过如下公式(2)计算fij:
30、
31、公式(2)中,表示所述偏差列表中的最小值;
32、p表示从所述偏差列表中抽取的距离偏差绝对值由大到小排列的前p个数值;
33、表示前p个数值中的第x个距离偏差绝对值;
34、wx表示在计算fij时的权重。
35、作为优选,若对应的元素i′i1为归一化后所述异常数据矩阵中的第一子矩阵中的元素,则wx为i′ij在归一化的所述第一子矩阵中所处的行中记载的品牌权重;若对应的元素i′i1为归一化后的所述异常数据矩阵中的第二子矩阵中的元素,则wx为i′ij在归一化的所述第二子矩阵中所处的行中记载的地级行政区权重。
36、作为优选,步骤s4具体包括步骤:
37、s41,划定并行筛选清洗算法的第一样本数据集和第二样本数据集;
38、s42,各第一清洗算法对所述第一样本数据集中的各第一样本数据进行第一轮询清洗,得到每个所述第一清洗算法对每个所述第一样本数据的第一清洗结果,
39、并行的,各第二清洗算法对所述第二样本数据集中的各第二样本数据进行第二轮询清洗,得到每个所述第二清洗算法对每个所述第二样本数据的第二清洗结果;
40、s43,计算每个所述第一清洗结果与关联对应的所述第一样本数据的第一人工校验结果的第一清洗偏差,并计算每个所述第二清洗结果与关联对应的所述第二样本数据的第二人工校验结果的第二清洗偏差;
41、s44,对关联同个所述第一清洗算法的各所述第一清洗偏差进行加权求和,得到第一融合偏差,对关联同个所述第二清洗算法的各所述第二清洗偏差进行加权求和,得到第二融合偏差;
42、s45,识别出最小的所述第一融合偏差和最小的所述第二融合偏差分别对应的所述第一清洗算法、所述第二清洗算法作为筛选出的在t2时刻可用的清洗算法。
43、作为优选,步骤s41中,数据集划定方法为:对从每个地级行政区对应的所述异常数据矩阵中的第一子矩阵中筛选出的第一样本数据划入到所述第一样本数据集,将从每个所述地级行政区对应的所述异常数据矩阵中的第二子矩阵中筛选出的第二样本数据划入到所述第二样本数据集。
44、作为优选,所述第一异常数据包括水泥品牌、所述水泥品牌在地级行政区的粉磨站产能占有率、熟料占有率以及品牌产品价格中的重复数据和值缺失的数据;
45、所述第二异常数据包括地级行政区名称、地级行政区的预拌混凝土消费量、固定资产投资和水泥产量中的重复数据和值缺失的数据。
46、本发明具有以下有益效果:
47、1、利用地级行政区平均价格影响水泥价格指数变化量的重要性,将其作为中间数据引入到异常数据矩阵中,首先实现了对影响水泥价格指数的数据的分割,通过数据分割实现了对数据的并行清洗和对清洗算法的并行筛选,提高了数据清洗和算法筛选的速度。
48、2、通过计算异常数据矩阵中各元素影响算法输出的影响因子fij,在计算fij时以矩阵中各元素与中间数据的距离偏差绝对值为依据,考虑了各元素与中间数据的依赖关系,依赖关系包括矩阵中的第一子矩阵中的各元素与中间数据之间的第一依赖关系和第二子矩阵中的各元素与中间数据的第二依赖关系,这些第一依赖关系能够表征第一子矩阵中的各元素之间对求解中间数据的重要程度,而这些第二依赖关系又能表征第二子矩阵中的各元素相比较中间数据对求解水泥价格指数的重要程度,通过fij的计算以数值方式表达了这些依赖关系,在后续验证算法清洗数据的可用性时,以fij值为筛选验证算法可用性的样本数据变得简单、直观。
49、3、fij的计算考虑了不同元素对求解中间数据的重要程度,并考虑了不同元素结合中间数据对求解水泥价格指数的重要程度。fij很好表征了第一子矩阵中的各元素与中间数据的第一依赖关系,并表征了第二子矩阵中的各元素相比较中间数据对求解水泥价格指数的重要程度的第二依赖关系。这两个依赖关系在公式(2)中的体现为:dij本身是第一子矩阵和第二子矩阵中的各元素与中间数据的偏差,本发明在计算水泥价格指数时,考虑了dij对水泥价格指数变化量的影响,dij本身已经体现了子矩阵中各元素与中间数据的依赖关系;将引入到fij的计算中,进一步考虑了对应的元素与dij对应的元素相互之间对影响水泥价格指数的关联关系;将偏差列表中排列前p个数值的引入到fij,考虑了所引入的具有不同权重的对应的元素与dij对应的元素之间对影响水泥价格指数的关联关系;通过dij本身考虑依赖关系,通过引入和偏差列表中排列前p个考虑两个关联关系,使得fij能够很好地表征两个依赖关系,进而通过fij的计算能够确保所筛选的用于验证各清洗算法可用性的样本数据的代表性、有效性。
50、4、通过前期引入中间数据构建异常数据矩阵(该矩阵包括第一子矩阵和第二子矩阵),在筛选清洗算法时,基于所构建的两个子矩阵实现了对清洗算法的并行筛选,确保了算法清洗的速度。另外,通过计算清洗偏差和融合偏差,并基于人工对t1时刻算法清洗的异常数据的人工校验数据,实现了对t2时刻需采用的清洗算法的精准筛选。
- 还没有人留言评论。精彩留言会获得点赞!