一种基于脉动阵列的LSTM加速器及加速方法
本发明涉及人工智能的循环神经网络,特别是一种基于脉动阵列的lstm加速器及加速方法。
背景技术:
1、长短期记忆神经网络(long short-term memory,lstm)是循环神经网络(rnn)的一种经典变形,常用于处理序列数据,如文本分析、语音识别以及语言翻译等序列相关的识别任务。与传统的rnn网络相比,lstm网络具有更加强大的记忆功能,能够更好的处理长序列和长期依赖关系。lstm的关键特点是它引入了门控单元和细胞状态,用于控制信息的流动。门控单元的引入使得lstm能够捕捉到更长时间间隔的序列信息并保持长期依赖关系,避免了梯度消失或爆炸问题。同时门控单元引入导致lstm网络中计算量和存储复杂度也越来越大,导致传统通用处理器在执行lstm模型时存在效率低下的问题,庞大的存储需求也制约着lstm模型在资源有限嵌入式设备的部署。
2、现场可编程逻辑门阵列(fpga)具有可编程、高并行、低功耗等特点。相对于传统的cpu和gpu,fpga具有更高的灵活性和更短的开发周期,可设计用于不同网络结构的模型,并且通过合理的并行计算、算法映射以及内存优化,可有效提升lstm的计算效率。
3、由于lstm的内存需求庞大和计算效率低的问题,针对lstm网络的各种压缩方法可有效的降低lstm的参数量和计算量,但同时也可能会造成准确率下降及负载不均衡的问题。并且lstm加速器一般仅采用简单的并行以及流水线设计,无法适用于经过压缩后的lstm网络模型,存在运算单元闲置或数据流安排不合理的情况,造成模型整体效率不高。
技术实现思路
1、本发明所要解决的技术问题是克服现有技术的不足而提供一种基于脉动阵列的lstm加速器及加速方法,通过合理优化数据结构,将lstm中关键的权重矩阵与输入向量的乘法运算转化为矩阵与矩阵的乘法运算,并采用脉动阵列进行处理,脉动阵列中权重数据和输入数据在基本处理单元pe间流动,从而达到高并行度和高吞吐量,有效的提升了加速器的性能。
2、本发明为解决上述技术问题采用以下技术方案:
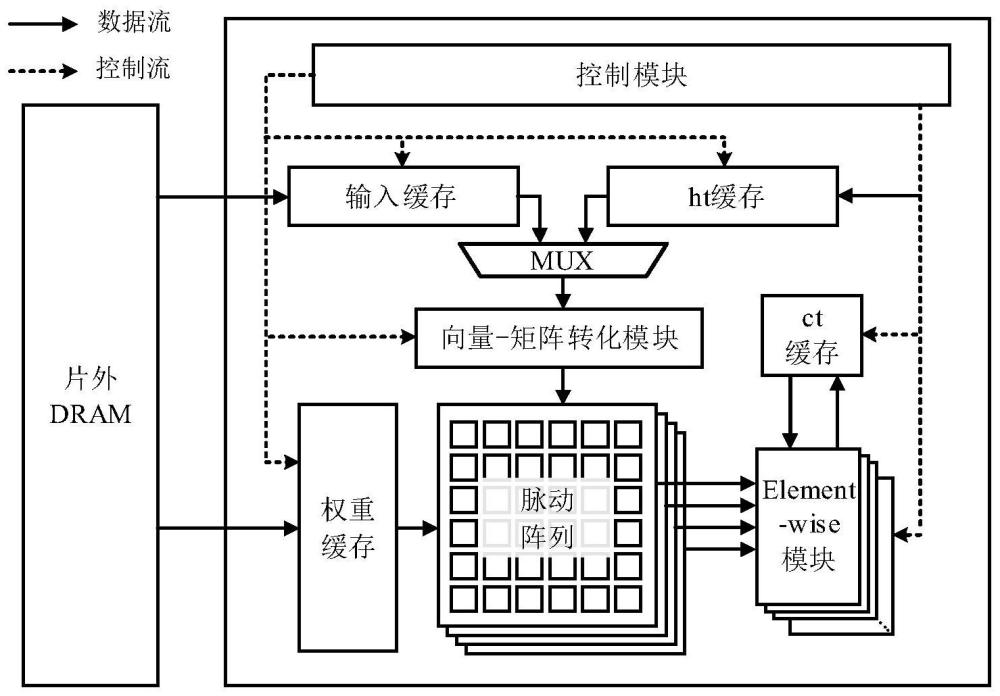
3、根据本发明提出的一种基于脉动阵列的lstm加速器,包括权重缓存模块,还包括向量-矩阵转化模块、k个脉动阵列和element-wise模块,其中,脉动阵列包括m×n个处理单元pe模块,m、n均为大于1的整数,脉动阵列的数量与lstm模型中的lstm门控单元的数量是相同的;其中,
4、向量-矩阵转化模块,用于将输入向量转化为矩阵形式,得到输入矩阵并将其输出至脉动阵列;
5、脉动阵列,用于接收来自权重缓存模块的权重矩阵、向量-矩阵转化模块的输入矩阵,权重矩阵和输入矩阵在pe模块间流动,权重矩阵经过剪枝后得到稀疏权重矩阵,在脉动阵列中完成lstm门控单元的稀疏权重矩阵与输入矩阵的乘法运算,输出向量至element-wise模块;
6、element-wise模块,用于接收来自脉动阵列输出的向量,计算当前时间步的细胞状态值和隐藏值。
7、作为本发明所述的一种基于脉动阵列的lstm加速器进一步优化方案,pe模块包括j个稀疏权重乘累加smac模块,smac模块用于处理lstm单元单个隐藏节点的乘累加运算。
8、作为本发明所述的一种基于脉动阵列的lstm加速器进一步优化方案,smac模块包括选择器、移位器和加法器,smac模块用于完成解码、移位和加法运算。
9、作为本发明所述的一种基于脉动阵列的lstm加速器进一步优化方案,smac模块的并行度j取决于块平衡稀疏剪枝的分块大小和稀疏度。
10、基于上述的一种基于脉动阵列的lstm加速器的加速方法,包括脉动阵列的计算方法,脉动阵列的计算方法如下:
11、步骤1、k个脉动阵列对应k个lstm门控单元,脉动阵列用于将稀疏权重矩阵和向量-矩阵转化模块输出的输入矩阵进行对应的乘法运算;
12、步骤2、pe模块接收权重缓存模块的稀疏权重矩阵中的参数和输入矩阵中的参数、或相邻pe模块的稀疏权重矩阵中的参数和输入矩阵中的参数,由pe模块内部的smac模块进行解码和乘累加运算;
13、步骤3、pe模块完成当前周期的运算后,保留当前运算的部分和结果,并将当前的稀疏权重矩阵的参数和输入矩阵中的参数传递给相邻的pe模块,供相邻的pe模块进行解码和乘累加运算;
14、步骤4、相邻pe模块接收到稀疏权重矩阵的参数和输入矩阵中的参数后重复上述步骤2和步骤3、直至脉动阵列完成lstm门控单元的稀疏权重矩阵与输入矩阵的乘法运算;并且将pe模块中的部分和结果传递给element-wise模块计算当前细胞状态值和隐藏值,pe模块中的部分和结果是指脉动阵列的输出向量。
15、作为本发明所述的一种基于脉动阵列的lstm加速器的加速方法进一步优化方案,首先采用分块循环矩阵压缩算法对lstm网络中的原始权重矩阵进行压缩,将权重矩阵进行分块,并采用循环矩阵替代原始权重矩阵,通过重训练弥补精度损失,循环矩阵采用首行向量表示,将每个分块循环矩阵的首行向量进行重排并存储;
16、其次采用块平衡剪枝算法对存储的首行向量进行剪枝,每个行向量都保留相同的稀疏度,并对压缩剪枝后的稀疏权重矩阵中的非零权重进行编码,将索引值和参数值组合并进行存储,高位存储索引值,低位存储参数值,取高位索引值解码输入向量中对应的输入数据值。
17、最后是采用指数量化将压缩剪枝后的稀疏权重矩阵中的非零权重量化为2的幂的形式,在后续硬件加速过程中可采用移位运算代替乘法运算。
18、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
19、本发明主要针对压缩剪枝后的稀疏lstm神经网络的前向推理过程进行硬件加速,为了提高数据的利用效率和加速器性能,通过向量-矩阵转化模块将lstm中原始的矩阵与向量的乘法运算转化为矩阵与矩阵的乘法运算,并根据循环矩阵分块大小以及块平衡剪枝稀疏度,合理安排了脉动阵列中基本处理单元pe的结构和并行度,合理运用流水线设计,通过权重数据和输入数据在脉动阵列的pe间流动,权重和输入数据高效复用,不同pe同时运行,从而达到一种高并行度和高吞吐量的运行状态,有效提升了加速器的运算性能。
技术特征:
1.一种基于脉动阵列的lstm加速器,包括权重缓存模块,其特征在于,还包括向量-矩阵转化模块、k个脉动阵列和element-wise模块,其中,脉动阵列包括m×n个处理单元pe模块,m、n均为大于1的整数,脉动阵列的数量与lstm模型中的lstm门控单元的数量是相同的;其中,
2.根据权利要求1所述的一种基于脉动阵列的lstm加速器,其特征在于,pe模块包括j个稀疏权重乘累加smac模块,smac模块用于处理lstm单元单个隐藏节点的乘累加运算。
3.根据权利要求2所述的一种基于脉动阵列的lstm加速器,其特征在于,smac模块包括选择器、移位器和加法器,smac模块用于完成解码、移位和加法运算。
4.根据权利要求3所述的一种基于脉动阵列的lstm加速器,其特征在于,smac模块的并行度j取决于块平衡稀疏剪枝的分块大小和稀疏度。
5.基于权利要求1所述的一种基于脉动阵列的lstm加速器的加速方法,其特征在于,包括脉动阵列的计算方法,脉动阵列的计算方法如下:
6.根据权利要求5所述的一种基于脉动阵列的lstm加速器的加速方法,其特征在于,首先采用分块循环矩阵压缩算法对lstm网络中的原始权重矩阵进行压缩,将权重矩阵进行分块,并采用循环矩阵替代原始权重矩阵,通过重训练弥补精度损失,循环矩阵采用首行向量表示,将每个分块循环矩阵的首行向量进行重排并存储;
技术总结
本发明公开了一种基于脉动阵列的LSTM加速器,加速器包括向量‑矩阵转化模块、脉动阵列、Element‑wise模块、控制模块以及存储模块;向量‑矩阵转化模块负责将输入向量转化为矩阵形式,并映射至脉动阵列的输入数据流上;脉动阵列负责LSTM门控单元的稀疏权重矩阵与输入矩阵的乘法运算,由多个PE模块组成,通过输入数据流和权重数据流在PE模块间流动,高度复用数据,有效避免数据频繁读取。本发明还公开了一种基于脉动阵列的LSTM加速器的加速方法,本发明通过优化数据结构,将原有的矩阵与向量乘法运算转化为矩阵与矩阵乘法运算,并通过脉动阵列对稀疏权重矩阵与输入矩阵的乘法运算进行处理,实现了PE模块的高并行度和高吞吐率,从而提升了加速器的运算性能。
技术研发人员:葛芬,王浩,周芳,叶剑涛,龚文强,张国辉
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!