一种基于半监督目标检测的实验仪器检测方法
本发明属于计算机视觉图像目标检测,尤其涉及一种基于半监督目标检测的实验仪器检测方法。
背景技术:
1、在教育信息化和基础教育课程、教学、评价一体化改革不断深化的背景下,人工智能应用到中学理化生实验的操作评价系统诞生,既是教育信息化的一次突破,更是一次ai智能深度学习技术与教育教学评价深度融合的有益探索和尝试。
2、近年来在半监督目标检测中,目前主流的方法分为两种:1)基于一致正则化的方法。这种方法通过在模型的损失函数中引入一致性正则项来利用无标签数据提高模型的泛化能力。2)基于伪标签学习的方法。该方法是利用无标签数据来生成伪标签增加训练样本,从而提高目标检测模型的性能。这些方法更多的是在目标分类任务下对目标进行检测,针对半监督条件下的目标检测研究相对较少。
3、基于伪标签学习的方法一般有两种,早期的方法是一种两阶段训练方式,基于传统的两阶段目标检测框架(如faster r-cnn或mask r-cnn)进行改进的。首先使用有标签数据训练一个初始的目标检测教师模型,然后使用教师模型对无标签数据进行预测并生成伪标签,接下来,将有标签数据和带有伪标签的无标签数据一起用于重新训练学生模型。这种方法不仅迭代的过程复杂,而且由于伪标签的生成方式,其最终准确性受到初始教师模型的限制。
4、现阶段采用端到端的半监督目标检测结构,直接在整个网络中引入半监督学习的思想。它使用有标签数据和无标签数据一起进行训练,通过设计合适的损失函数和训练策略来实现半监督学习。这种方法的优点是可以在一个端到端的框架中同时利用有标签数据和无标签数据,减少了训练过程中的人工干预和迭代训练的复杂性,采用合适的训练也能取得较好的结果。但也存在着一些不足:一方面是教师学生模型沿用较复杂的两阶段目标检测框架,另一方面是伪标签的准确性和噪声问题,需要进行合理的筛选和处理,这些问题都会影响最终模型的训练效果。
技术实现思路
1、本发明所要解决的技术问题是:提供一种基于半监督目标检测的实验仪器检测方法,采用端到端的一阶段半监督目标检测结构降低训练的复杂度,通过采用自适应分类损失函数,避免了正确伪标签被误判的情况,教师学生模型采用轻量级的一阶段目标检测网络减小运算量、引入混合自注意力卷积提高了小目标实验仪器检测精度,提高了最终训练的学生模型的检测精度。
2、为了解决以上技术问题,本发明采用如下技术方案:
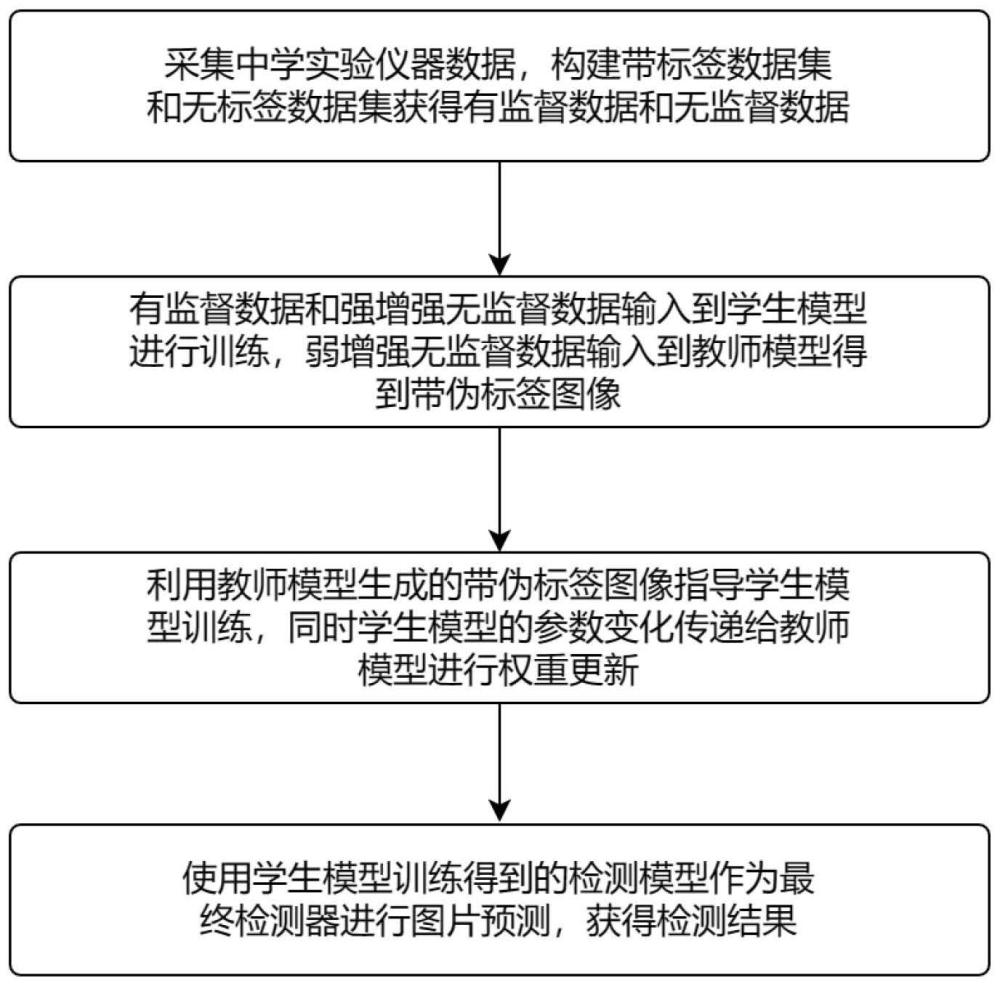
3、一种基于半监督目标检测的实验仪器检测方法,包括以下步骤:
4、s1、构建教师模型和学生模型。
5、s2、采集实验仪器数据,构建带标签数据集和无标签数据集获得有监督数据和无监督数据,将该数据分别输入到学生模型和教师模型进行训练,教师模型生成带伪标签图像指导学生模型训练,学生模型的参数变化传递给教师模型。
6、s3、使用自适应损失函数训练学生模型得到最终检测器进行图片预测,获得检测结果。
7、进一步的,步骤s1中,教师模型和学生模型共享一个网络模型结构,该结构包括backbone模块、neck模块和head模块,其中backbone模块和neck模块引入一个改进的混合自注意力卷积网络,充分提取浅、中层特征来提高小目标检测精度。
8、进一步的,步骤s1中,模型被配置以执行以下动作:
9、s101、backbone模块进行特征提取:输入图像经过卷积核大小为3,步长分别为1、2、1、2的4层卷积层,再输入mcan(multi-convolution aggregated network,多卷积堆叠结构)模块,三次经过mp(maxpool convolutions,最大池化卷积)模块和mcan模块,分别输出三个不同尺度、不同深度的特征图c1、c2、c3,大小分别为80*80*512、40*40*1024、20*20*1024。
10、s102、neck模块进行特征加强:采用pan(path aggregation network,路径聚合网络)+fpn(feature pyramid network,特征金字塔网络)的特征金字塔结构,对于backbone输出的特征图c1、c2、c3,利用sppcspc(spatial pyramid pooling and connectedspatial pyramid convolution,空间金字塔池化和卷积)模块对特征图c3进行特征提取,获得大小为20*20*512的特征图p3,将下一级的特征图进行1次1×1卷积和上采样操作,并与上一级特征图进行特征融合,经过mcan-h(multi-convolution aggregated network-h,改进多卷积堆叠结构)模块进行特征提取获得大小分别为40*40*256、80*80*128的特征图p2、p1,其中p1即为特征图n1,将上一级的特征图利用mp模块卷积进行下采样,下采样后与下一级特征图堆叠,使用mcan-h模块进行特征提取得到大小分别为40*40*256、20*20*512的特征图n2、n3。
11、s103、head模块预测先验框对应的物体情况,将neck模块输出的特征图n1、n2和n3输入到repconv(re-parameterization convolutional neural network,重参数化卷积)模块中,使用1×1的卷积得到类别、定位边界框和置信度结果。
12、进一步的,步骤s101中,提到的模块分别包含以下内容:
13、mcan模块是一个高效的网络结构,通过控制最短和最长的梯度路径,使网络能够学习到更多的特征,并且具有更强的鲁棒性,其中梯度是指损失函数对于网络参数的偏导数,用于更新网络参数以最小化损失函数,梯度路径是指在神经网络中,反向传播算法中梯度的传递路径。
14、mcan模块包含两条分支,第一条分支使用1×1的卷积做通道数的变化,第二条分支使用1×1的卷积做通道数的变化,利用三个3×3的卷积和一个混合自注意力卷积块做特征提取;最终输出的特征提取结果是把四个特征叠加在一起。
15、mp模块包含两个分支,第一条分支包括一个最大池化和一个1×1的卷积,第二条分支包括一个1×1的卷积和一个卷积核大小为3、步长为2的卷积块。
16、改进的混合自注意力卷积网络分为两个阶段,第一阶段对输入特征图进行3个1×1卷积投影;第二阶段将第一阶段得到的卷积投影结果分别经过卷积注意力模块进行移位排列相加和自注意力模块进行权重计算,将移位排列相加和自权重计算进行加权求和。
17、进一步的,步骤s102中,提到的模块分别包含以下内容:
18、mcan-h模块与mcan模块的区别为输出卷积层的连接数,融合了不同尺度的特征,mcan-h模块包含两条分支,第一条分支使用1×1的卷积做通道数的变化,第二条分支使用1×1的卷积做通道数的变化,利用三个3×3的卷积和一个混合自注意力卷积块做特征提取;最终输出的特征提取结果是把六个特征叠加在一起。
19、sppcspc模块包含两个分支,第一分支的spp(spatial pyramid pooling,空间金字塔池化)模块通过最大池化获得不同感受野,在该分支中,包括四个并行的最大池化分支,卷积核大小分别是1、5、9、13,处理不同尺度的对象获得四个不同尺度感受野,用来区别于大目标和小目标;第二分支的cspc(connected spatial pyramid convolution,空间金字塔卷积)模块将特征分为两部分,其中的一个部分进行卷积处理,另外一个部分进行spp结构的处理,最后把这两个部分合并在一起。
20、进一步的,步骤s103中,repconv重参数化卷积块包括训练模块和推理模块;
21、其中,训练模块包括三个分支,第一分支是3×3的卷积,用于特征提取;第二分支是1×1的卷积,用于平滑特征;第三分支是直连分支,不做卷积操作;最终的输出由三个分支相加。
22、推理模块包括一个步长为1的3×3的卷积,由训练模块重参数化转换而来。
23、进一步的,步骤s2中,包括以下子步骤:
24、s201、有监督数据和无监督数据以1:4的比例输入到学生模型和教师模型中进行训练,其中无监督数据经过随机翻转和随机位移得到弱增强无监督数据,无监督数据经过随机遮挡和随机裁剪得到强增强无监督数据。
25、s202、将弱增强无监督数据输入到教师模型中,生成两组带伪标签数据:一组用于分类分支,另一组用于回归分支,不同分支处理以保证生成伪标签的质量。将教师模型生成带伪标签图像用来指导学生模型训练,学生模型联合学习有监督数据、强增强无监督数据和教师模型生成的带伪标签数据,同时学生模型的参数变化传递给教师模型。
26、进一步的,步骤s3中,检测结果的获得包括以下子步骤:
27、s301、学生模型训练的损失函数l定义为:
28、l=ls+λlu
29、其中,λ表示训练的权重参数,ls表示监督检测损失函数,lu表示无监督检测损失函数。
30、监督检测损失函数ls定义为:
31、ls=lloc+lconf+lclass
32、其中,lloc表示定位损失,lconf表示置信度损失,lclass表示分类损失。
33、无监督检测损失函数lu定义为:
34、
35、其中,表示分类损失函数,表示回归损失函数。
36、分类损失函数定义为:
37、
38、其中,nf表示前景伪标签框的总数;nb表示背景伪标签框的总数;i表示前景伪标签框的序号;j表示背景伪标签框的序号;lcls表示分类伪标签框损失函数,即前景分类伪标签框和背景分类伪标签框损失之和;表示第i个前景伪标签框;表示第j个背景伪标签框;表示前景伪标签框和背景伪标签框的集合;表示背景伪标签框的自适应权重,r表示nb个背景伪标签框置信度的和,rj表示第j个背景伪标签框置信度。
39、回归损失函数定义为:
40、
41、其中,lreg表示回归伪标签框损失函数,即前景回归伪标签框损失;表示前景伪标签框的集合。
42、s302、使用自适应损失函数训练学生模型得到最终检测器进行图片预测,获得检测结果,包括类别、定位边界框和置信度。
43、进一步的,本发明还提出了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现前文所述的一种基于半监督目标检测的实验仪器检测方法的步骤。
44、进一步的,本发明还提出了一种计算机可读的存储介质,所述计算机可读的存储介质存储有计算机程序,所述计算机程序被处理器运行时执行前文所述的一种基于半监督目标检测的实验仪器检测方法。
45、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
46、本发明采用端到端的半监督训练方式,简化训练流程,提高模型泛化效果,缓解现实场景中大量标注数据获取不易的问题;通过自适应分类损失函数,避免了正确伪标签被误判的情况,来提高生成的伪标签质量,从而提高生成的模型效果;教师学生模型采用轻量级的一阶段目标检测网络减小运算量、引入混合自注意力卷积提高小目标实验仪器检测精度,更加有效的提高了学生模型的分类能力。
- 还没有人留言评论。精彩留言会获得点赞!