一种基于扩散语言模型的文本生成方法
本发明涉及一种扩散文本生成方法,具体涉及一种基于扩散语言模型的文本生成方法,属于自然语言处理应用。
背景技术:
1、随着深度学习的发展,文本生成技术取得了长足的进步。目前,扩散模型成为最先进的生成范式,在对图像、音频和视频等连续数据模式进行建模方面取得巨大成功。由于文本的离散性,将扩散模型扩展到生成文本数据仍然是一项具有挑战性的任务。先前的工作已经探索了文本生成的两种代表性扩散过程,即离散扩散和连续扩散。离散扩散是直接在文本等离散信号上进行扩散,连续扩散则是将文本转换为词嵌入,进而在词嵌入的连续潜在表征中执行扩散过程,最后采用rounding操作将词嵌入解码为文本。
2、目前,预训练语言模型在各类任务都取得了显著的性能,将预训练语言模型集成到扩散模型中将有利于提高生成文本的质量。已有研究人员探索了预训练语言模型与离散扩散模型的集成,这种集成可以利用两种模型的优势,从而产生更全面的方法。然而,他们的方法只对离散扩散模型有效,当与连续扩散模型结合时,实际上会导致性能下降。此外,现有的文本扩散模型的噪声调度算法没有考虑句子中单词之间的语言差异,违反了文本生成的“easy-first policy”,导致关键字和生僻词的生成不准确。因此,探索更有效的方法来集成连续扩散模型与预训练语言模型,同时在噪声调度算法中引入语言学差异,对于提高文本生成质量具有重要意义。
技术实现思路
1、本发明的目的是为了克服现有扩散文本生成方法存在的缺陷,创造性地提出一种基于扩散语言模型的文本生成方法。本方法,利用bart解码器代替rounding操作,可以更加有效地对高维词嵌入进行解码;并提出一种考虑单词语言特征的噪声调度算法(linguistic easy-first schedule),从词相关性和信息量两个方面度量句子中单词的重要性,从而提升扩散文本生成的效果。
2、本发明的创新点在于:首先,为了利用预训练语言模型丰富的先验知识,可以使用预训练语言模型作为编码器编码词嵌入,在这种情况下,词嵌入的维度会变得很高(例如,bert编码的词嵌入维度为768),而rounding操作不能有效地将高维词嵌入解码为文本,从而导致文本生成质量下降。针对该情况,使用bart解码器代替rounding操作,能够更加有效地解码高维词嵌入。此外,在现有文本噪声调度的基础上引入语言学差异,从词相关性和信息量两个方面度量句子中单词的重要性,这样,生成过程将首先先生成常用词作为上下文,然后生成稀有词,符合“easy-first policy”,有利于提高生成文本的质量。
3、本发明的目的是通过以下技术方案实现的。
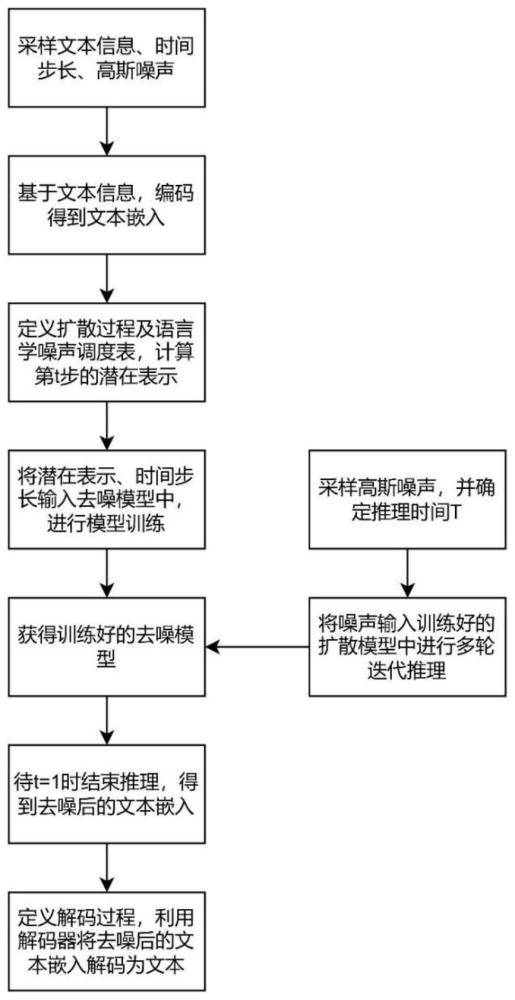
4、本发明提出的一种基于扩散语言模型的文本生成方法,所述方法包括:
5、s1、采样文本信息w,时间步长t,高斯噪声∈;
6、s2、基于采样的文本信息,编码得到文本嵌入x0;
7、在步骤s2中,基于采样的文本信息,编码得到文本嵌入x0:
8、x0=e(w1,l) (1)
9、其中,w由l个tokens组成,e()由可学习的嵌入函数组成。
10、在所述嵌入函数e()中,为了充分利用预训练语言模型的先验知识以提高文本生成质量,嵌入函数e()可直接替换为预训练语言模型,如bert。
11、s3、定义标准扩散过程及语言学噪声调度表(linguistic easy-firstschedule),计算第t步的中间潜在表示xt;
12、在步骤s3中,标准扩散过程由前向加噪和反向去噪过程组成。其中,前向加噪过程使用高斯噪声逐渐破坏数据样本即编码得到的文本嵌入x0,具体而言,给定数据样本x0,通过逐步添加少量高斯噪声来扰动x0,直到x0完全变成噪声。正向过程中产生由中间潜在表示x1,…,xt组成的马尔可夫链:
13、
14、其中,βt∈(0,1)控制时间步t处添加的噪声量。βt随着时间步长的增加而增大,最终将x0分解为高斯噪声xt~(0,i),i代表噪声xt的方差。基于重参数化技巧,可以从x0以封闭形式采样任何中间潜在表示xt:
15、
16、其中,αt=1-βt,
17、反向去噪过程的目标是学习前向过程的逆过程p(xt-1|xt),从而通过一步步去噪将高斯噪声xt恢复到所需数据样本x0。然而真实的反向过程p(xt-1|xt)是不可计算的,所以定义了一个神经网络pθ(xt-1|xt)来拟合这一分布。当βt足够小时,可以将其视为高斯分布,且高斯分布只有两个参数:均值μθ(xt,t)和方差∑θ(xt,t),那么pθ(xt-1|xt)的定义如下:
18、
19、其中,μθ(·)和∑θ(·)可以通过去噪网络xθ实现,例如transformer:
20、
21、其中,αt=1-βt,
22、所述去噪网络xθ的训练目标是最大化数据logpθ(x0)的边界似然,简化的训练目标为:
23、
24、其中,q(x0:t)表示t=0到t=t中所有时刻的状态变量的联合概率分布,表示联合分布q(x0:t)的期望,μt(·)为q(xt-1|xt,x0)的均值,μθ(·)为pθ(xt-1|xt)的预测均值。
25、在步骤s3中,语言学噪声调度表(linguistic easy-first schedule)引入单词的重要性度量,符合文本生成的“easy-first policy”。该策略规定模型倾向于首先生成常用单词作为上下文,然后生成稀有单词。不遵循这一策略可能会导致棘手的问题,例如关键字或稀有词生成不准确。
26、首先,需要定义单词在句子中的重要性s,由词相关性和信息量两部分进行度量。
27、词相关性由textrank算法定义。textrank将句子中的单词作为节点构建无向权重图,利用节点之间的边权重计算出每个节点的pagerank值,从而得出句子中每个单词的重要性。一个节点的得分越高,表示该节点对应的单词在句子中越重要。
28、在一个句子中,如果单词wi对应节点vi,并且节点vi与另一个单词wj对应的另一个节点vj之间存在一条边,则该边的权值定义如下:
29、
30、其中,表示节点vj的出度集合。节点vi的pagerank值为:
31、
32、其中,表示节点vi的入度集合,c表示阻尼系数,通常设为0.85,可以调节pagerank算法中随机跳转的概率,对算法的收敛性和稳定性起着重要的作用。
33、此外,信息量由熵h来定义。在给定的上下文中,熵较高的单词包含更多的不可预测性和信息内容,因此与熵较低的单词相比更重要。熵的计算公式为:
34、h(w)=-p(w)log(p(w)) (9)
35、
36、其中,p(w)表示单词w出现的概率,f表示语料库中的单词频率。
37、单词w在句子d中的重要性s由词相关性和信息量联合定义:
38、
39、基于引入的单词重要性s,将单词按其重要性进行降序排列,并将它们分成m个桶{w1:m},其中索引较低的桶包含重要性更高的词。在前向加噪过程中,难(高重要性)的单词将先于容易(低重要性)的单词被添加噪声。这样,在反向过程中,低重要性的单词将更早生成作为上下文,然后生成高重要性的单词,符合easy-first-generation的语言特性,有利于获得更好的生成质量。并且,在前向加噪过程中,高重要性的单词被加入较少的噪声,有利于保持训练的稳定性。
40、具体来说,在每一步t,桶中的单词wi的嵌入表示xi将被添加少量高斯噪声:
41、
42、其中,βt是在扩散步骤t中添加的噪声量:
43、
44、其中,s是一个常数,对应于初始噪声水平。
45、基于以上定义,潜在表示xt的计算方式为:
46、
47、s4、将潜在表示xt、时间步长t输入去噪模型中,进行模型训练。
48、在每一个训练轮次,将潜在表示xt、时间步长t输入去噪模型中,计算步骤s3中推导的公式(6)作为损失函数,使用adamw优化器更新模型参数直至其收敛,最终得到去噪模型。
49、s5、采样高斯噪声xt,并确定推理时间t,将噪声输入训练好的扩散模型中进行多轮迭代推理,待t=1时结束推理,得到去噪后的文本嵌入;
50、s6、定义解码过程,利用解码器将去噪后的文本嵌入解码为文本。
51、在步骤s6中,对于解码,使用预训练的bart解码器d()来重建原始输入:
52、
53、为了提高效率,训练中冻结bart的参数,只保留去噪网络xθ的可训练参数。
54、有益效果
55、本发明对比现有技术,使用bart解码器代替rounding操作,更加有效地解码高维词嵌入,实现连续扩散模型与预训练语言模型的有效集成;并提出了“linguistic easy-first schedule”噪声调度算法,在现有文本噪声调度的基础上引入语言学差异,从词相关性和信息量两个方面度量句子中单词的重要性,生成过程满足先生成常见词作为上下文,进而生成稀有词,提高文本生成质量。通过在e2e数据集和5个可控生成任务(semanticcontent,parts-of-speech,syntax tree,syntax spans和length)上的实验,证明了预训练模型和语言学特征的引入可以有效提高文本生成的质量,且优于其他非自回归及扩散文本生成方法。
- 还没有人留言评论。精彩留言会获得点赞!