一种互动虚拟现实口才表达训练方法、装置、设备及介质与流程
本技术涉及计算机领域,尤其涉及一种互动虚拟现实口才表达训练方法、装置、设备及介质。
背景技术:
1、口才表达指在公众场合,以有声语言为主要手段,以体态语言为辅助手段,针对某个具体问题,鲜明、完整地发表自己的见解和主张的交流方式,口才表达在人们的日常生活中逐渐变得重要。
2、现今,口才表达者为了提高自己的口才表达水平,通过需要进行训练,但是目前没有便捷可靠的训练方法,例如口才表达者要训练不同场景中的表达时通常只能自行想象或者达到一个具体的实际地点身临其境地进行训练,费时费力,时间和地点受到严重限制。另外,通常都是口才表达者单独训练,而没有观众,无法模拟真实的口才表达场景,导致口才表达训练效果差。
技术实现思路
1、本技术实施例提供一种互动虚拟现实口才表达训练方法、装置、设备及介质,以解决相关技术存在的至少一个问题,技术方案如下:
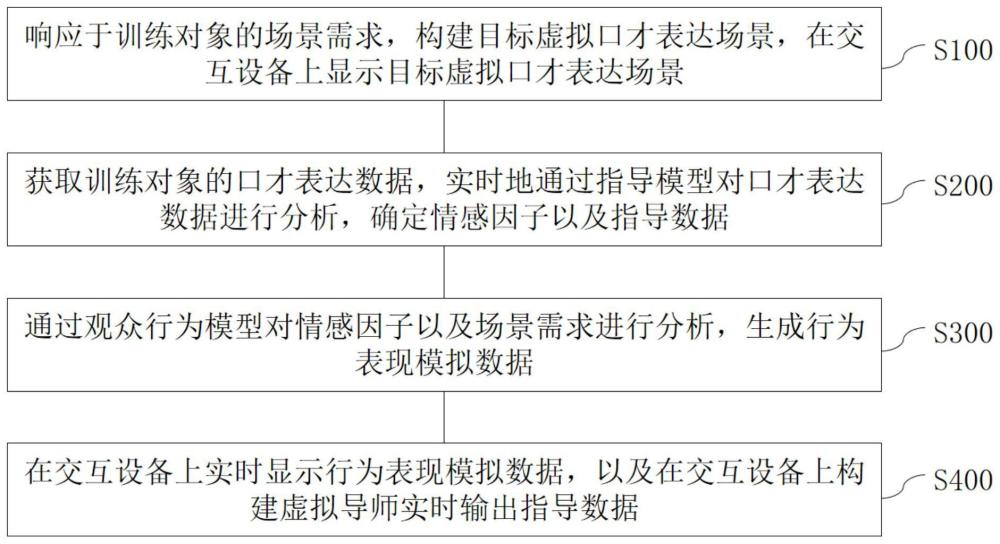
2、第一方面,本技术实施例提供了一种互动虚拟现实口才表达训练的方法,包括:
3、响应于训练对象的场景需求,构建目标虚拟口才表达场景,在交互设备上显示所述目标虚拟口才表达场景;
4、获取所述训练对象的口才表达数据,实时地通过指导模型对所述口才表达数据进行分析,确定情感因子以及指导数据;
5、通过观众行为模型对所述情感因子以及所述场景需求进行分析,生成行为表现模拟数据;
6、在所述交互设备上实时显示所述行为表现模拟数据,以及在所述交互设备上构建虚拟导师实时输出所述指导数据。
7、在一种实施方式中,所述响应于训练对象的场景需求,构建目标虚拟口才表达场景包括:
8、响应于所述训练对象的场景选择指令,从预设场景库中确定目标场景模型,对所述目标场景模型进行渲染,生成目标虚拟口才表达场景;
9、或者,
10、响应于所述训练对象的场景配置指令,确定按照场景需求配置的场景布局信息、尺寸信息以及灯光信息,对所述场景布局信息、所述尺寸信息以及所述灯光信息进行建模处理,生成个性化场景模型,对所述个性化场景模型进行渲染,生成目标虚拟口才表达场景。
11、在一种实施方式中,所述通过观众行为模型对所述情感因子以及所述场景需求进行分析,生成行为表现模拟数据包括:
12、通过所述观众行为模型对所述场景需求进行分析,确定符合所述场景需求对应的若干个第一行为表现;
13、通过所述观众行为模型对所述情感因子进行分析,确定符合所述情感因子对应的第二行为表现;
14、根据若干个所述第一行为表现以及所述第二行为表现,生成行为表现模拟数据。
15、在一种实施方式中,所述根据若干个所述第一行为表现以及所述第二行为表现,生成行为表现模拟数据包括:
16、当存在相同的所述第一行为表现以及所述第二行为表现时,将相同的所述第一行为表现或所述第二行为表现确定为目标行为表现;
17、当不存在相同的所述第一行为表现以及所述第二行为表现时,从若干个所述第一行为表现以及所述第二行为表现中随机确定目标行为表现,或者计算每一所述第一行为表现与所述第二行为表现的相似度,将相似度最高的第一行为表现作为目标行为表现;
18、将确定的所述目标行为表现进行实时地模拟,生成行为表现模拟数据。
19、在一种实施方式中,所述实时地通过指导模型对所述口才表达数据进行分析,确定情感因子以及指导数据包括:
20、实时地通过指导模型对所述口才表达数据进行第一分析,确定情感因子;
21、获取训练对象所输入的训练目标,根据所述训练目标以及所述口才表达数据进行第二分析,得到第二分析结果;
22、根据所述第二分析结果从技巧库中确定目标口才表达技巧,将所述目标口才表达技巧作为指导数据。
23、在一种实施方式中,所述在所述交互设备上构建虚拟导师实时输出所述指导数据包括:
24、响应于所述训练对象的虚拟导师选择指令,从虚拟导师库中确定虚拟导师,在所述交互设备上构建所述虚拟导师实时输出所述指导数据,其中每一虚拟导师具有不同的教学风格、专业领域、指导策略以及声音;
25、或者,
26、响应于所述训练对象的虚拟导师创建指令,确定按照训练对象需求配置的外表信息、性格信息以及声音信息,根据所述外表信息、性格信息以及声音信息在所述交互设备上构建虚拟导师实时输出所述指导数据。
27、在一种实施方式中,所述方法还包括:
28、获取所述训练对象在所述交互设备上输入的交流信息,所述交流信息包括文字、语音或者手势;
29、响应于所述交流信息与所述虚拟导师建立实时对话,在所述实时对话的过程中,分析所述交流信息的含义,并根据所述含义查找对应的回答,通过所述虚拟导师输出所述回答。
30、第二方面,本技术实施例提供了一种互动虚拟现实口才表达训练装置,包括:
31、构建模块,用于响应于训练对象的场景需求,构建目标虚拟口才表达场景,在交互设备上显示所述目标虚拟口才表达场景;
32、确定模块,用于获取所述训练对象的口才表达数据,实时地通过指导模型对所述口才表达数据进行分析,确定情感因子以及指导数据;
33、生成模块,用于通过观众行为模型对所述情感因子以及所述场景需求进行分析,生成行为表现模拟数据;
34、显示模块,用于在所述交互设备上实时显示所述行为表现模拟数据,以及在所述交互设备上构建虚拟导师实时输出所述指导数据。
35、在一种实施方式中,所述显示模块还用于:
36、获取所述训练对象在所述交互设备上输入的交流信息,所述交流信息包括文字、语音或者手势;
37、响应于所述交流信息与所述虚拟导师建立实时对话,在所述实时对话的过程中,分析所述交流信息的含义,并根据所述含义查找对应的回答,通过所述虚拟导师输出所述回答。
38、第三方面,本技术实施例提供了一种电子设备,包括:处理器和存储器,该存储器中存储指令,该指令由该处理器加载并执行,以实现上述各方面任一种实施方式中的方法。
39、第四方面,本技术实施例提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被执行时实现上述各方面任一种实施方式中的方法。
40、上述技术方案中的有益效果至少包括:
41、通过响应于训练对象的场景需求,构建目标虚拟口才表达场景,在交互设备上实时显示目标虚拟口才表达场景,增加训练的真实感与逼真度,相对现有方案不会受到地点的限制;获取训练对象的口才表达数据,实时地通过指导模型对口才表达数据进行分析,确定情感因子以及指导数据,通过观众行为模型对情感因子以及场景需求进行分析,生成行为表现模拟数据;在交互设备上实时显示行为表现模拟数据,真实模拟观众,为训练对象提供更真实的口才表达环境和挑战,使训练对象能够在虚拟世界中体验与真实观众互动的情况;在交互设备上构建虚拟导师实时输出指导数据,提升训练的个性化程度和参与度。
42、上述概述仅仅是为了说明书的目的,并不意图以任何方式进行限制。除上述描述的示意性的方面、实施方式和特征之外,通过参考附图和以下的详细描述,本技术进一步的方面、实施方式和特征将会是容易明白的。
- 还没有人留言评论。精彩留言会获得点赞!