一种部分再生的昂贵大规模优化方法
本发明涉及单目标大规模昂贵优化,尤其涉及一种部分再生的昂贵大规模优化方法。
背景技术:
1、随着工业和技术的发展,在现实世界中经常会遇到具有很多变量的优化问题,如车间作业调度、铸造顺序调度、整数线性规划和航线网络。一般来说,最小化问题的数学模型如下:
2、min f(x)
3、
4、式中,表示搜索空间,x=(x1,x2,…,xn)t是决策变量,n是决策变量的数量。当n≥100时,则称为大规模优化问题lsop。
5、解决大规模问题常见的方法可以分为两类:基于分解的大规模优化方法,采用“分而治之”的策略,将原大规模优化问题分解为两个或多个子问题独立求解,然后组合形成原问题的解;基于非分解的大规模优化方法,采用创新性的优化策略来生成新的解决方案,以更好地平衡大规模优化问题的勘探与开发。
6、然而,实际应用中的一些大规模优化问题是黑盒的,无论是计算时间还是经济成本、计算成本都很高,这些问题称为大规模昂贵优化问题,如空气动力学机翼设计、高炉优化和汽车行业的耐撞性分析。大多数现有的解决大规模优化问题的算法不能直接应用于解决昂贵的优化问题。一方面,在解决昂贵的优化问题时,为了减少目标函数的评估并节省计算成本,通常的做法是使用计算成本低廉的代理模型来逼近复杂且昂贵的目标函数。常用的代理模型包括支持向量机svm、多项式回归pr、高斯过程gp、人工神经网络ann和径向基函数rbf网络。然而,随着问题维度的增加,需要更多的训练数据来构建准确的代理模型。因此,为大规模优化问题建立精确的代理模型极具挑战性。这也是非分解优化算法在解决昂贵的大规模优化问题时面临的困难之一。另一方面,基于分解的大规模优化算法的性能很大程度上取决于分组策略的选择。然而,确定决策变量之间的交互关系需要大量的目标函数评估,这是不适合解决昂贵的优化问题。在传统的随机分组方法中,虽然不需要额外的评估时间,但所有特征都被认为具有同等重要性,计算资源也是平等分配的。
7、到目前为止,针对大规模优化问题提出的代理模型辅助的进化算法并不多,且大多数代理模型辅助的进化算法只能解决不超过200维的昂贵大规模优化问题,也称为高维优化问题。现有的针对高维优化问题的代理模型辅助的进化算法可以大致分为两类:基于非模型搜索的优化算法,仅利用替代模型提供的近似值来进行个体选择;基于模型搜索的优化算法,代理模型被视为优化目标用于指导搜索昂贵的优化问题的最优解。
8、然而,在大规模昂贵优化问题中,由于维度的增加导致“维度灾难”,搜索空间急剧增加,想要直接建模求解是非常困难的。
技术实现思路
1、针对上述现有技术存在的不足,本发明提供了一种部分再生的昂贵大规模优化方法,以解决现有技术中由于维度灾难导致的建模求解困难的问题;此外,还提供了一种改进的社会学习粒子群优化算法sl-pso来产生子种群的子代,通过同时向演示者和最优解xgbest学习来更新粒子的位置,以平衡收敛速度和种群的多样性。
2、本发明通过采用代理模型辅助和两阶段特征选择策略对原始大规模优化问题进行降维处理,形成低维子问题,增强算法的收敛性;同时,应用rbf辅助改进的社会学习粒子群优化算法sl-pso将传统sl-pso算法向整体平均行为学习的模块更改为向最优解学习,增强算法在子问题上的收敛性;此外,还提供了一种新的填充采样策略更新最优解和存档arc,即利用子问题最佳解在相应维度上生成新的最优解,通过比较当前最优解和新的最优解的真实评估结果,更新最优解和存档arc。
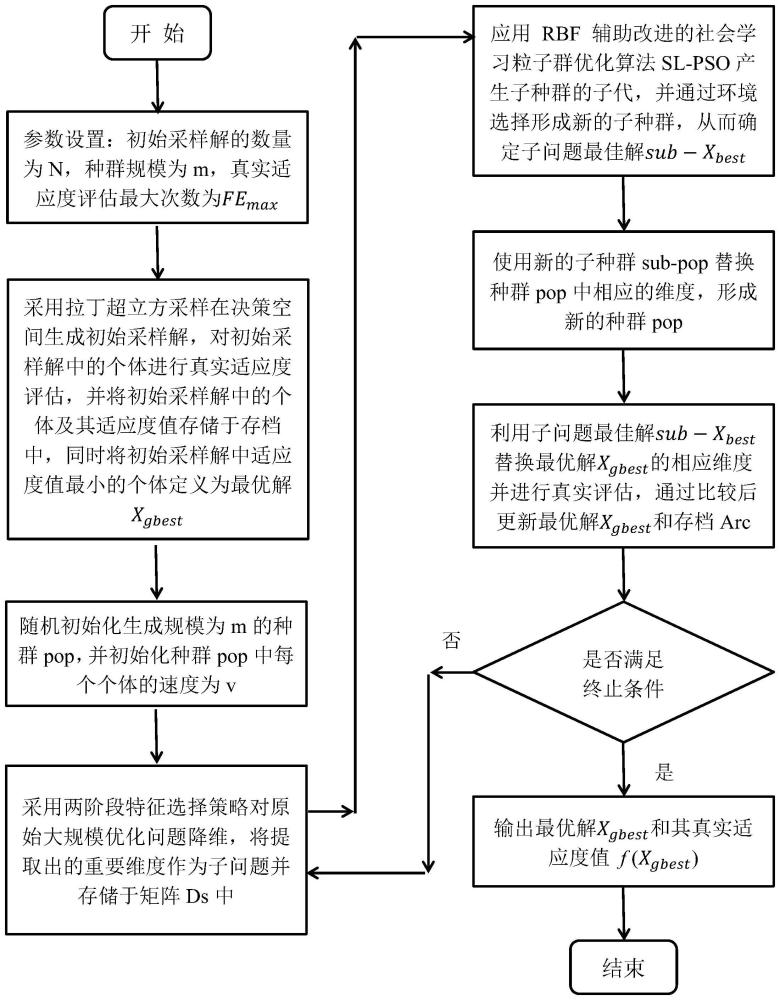
3、本发明提供了一种部分再生的昂贵大规模优化方法,具体步骤为:
4、s1、参数设置:初始采样解的数量为n,种群规模为m,真实适应度评估最大次数为femax;
5、s2、采用拉丁超立方采样lhs在决策空间生成初始采样解,对初始采样解中的个体进行真实适应度评估,并将初始采样解中的个体及其适应度值存储于存档arc中,同时将初始采样解中适应度值最小的个体定义为最优解xgbest;
6、s3、随机初始化生成规模为m的种群pop,并初始化种群pop中每个个体的速度为v;
7、s4、采用两阶段特征选择策略对原始大规模优化问题降维,将提取出的重要维度作为子问题并存储于矩阵ds中,其中两阶段特征选择过程是通过代理模型m辅助完成;
8、s5、应用rbf辅助改进的社会学习粒子群优化算法sl-pso产生子种群的子代,并通过环境选择形成新的子种群,从而确定子问题最佳解sub-xbest;
9、s6、使用新的子种群sub-pop替换种群pop中相应的维度,形成新的种群pop;
10、s7、利用子问题最佳解sub-xbest替换最优解xgbest的相应维度并进行真实评估,通过比较后更新最优解xgbest和存档arc;
11、s8、判断是否满足停止标准,如果是,则评估停止,输出最优解xgbest和其真实适应度值f(xgbest);否则,继续执行步骤s4-s8。
12、优选的,所述步骤s3中种群pop中个体速度的上限和下限分别设置为个体位置的上限和下限的百分之十。
13、优选的,所述步骤s4具体步骤为:
14、第一阶段:首先,从原始大规模问题中随机选择sub维度存储于数据集dr中;其次,基于数据集dr中存储的sub维度构建代理模型;最后,从存档arc中随机选择一部分样本作为训练集训练代理模型m,得到训练后代理模型m1;
15、第二阶段:人工扰动每个维度的输入数据,并通过观察每个维度模型估值产生的变化,从而提取出重要维度生成子问题并存储于矩阵ds中,具体步骤为:
16、step1、将所有变量都设置为下界值,并记为p1;
17、step2、将向量p1的第i个变量设置为上界值,并记为p2;
18、step3、使用训练后代理模型m1估计p1和p2的适应度值和
19、step4、计算和的差值δi,并将差值δi存储于矩阵g中,差值δi计算公式如下;
20、
21、step5、重复步骤step2-step4,直至完成向量p1上所有变量的扰动后停止;
22、step6、将矩阵g中所有数据按降序排序,并计算平均值u;
23、step7、将矩阵g中所有大于u的数据对应的变量从数据集dr中取出,基于取出的变量生成子问题并存储于矩阵ds中。
24、优选的,所述步骤s5具体步骤为:
25、s51、根据矩阵ds中对应的维度在种群pop和速度v中提取出子种群sub-pop以及子种群sub-pop中个体的速度sub-v;
26、s52、从存档arc中随机选择一部分样本训练代理模型m,得到训练后代理模型m2,并使用训练后代理模型m2估计子种群sub-pop中粒子的适应度值;
27、s53、应用rbf辅助改进的社会学习粒子群优化算法sl-pso更新子种群sub-pop,产生子种群sub-pop的子代,其中种群更新公式如下:
28、xi,j(t+1)=xi,j(t)+vi,j(t+1)
29、式中,i为整个群体中的第i个个体,1≤i≤m,m代表整个种群的规模,j为个体i的第j个维度,1≤j<d,d表示搜索空间的维度,xi,j(t)为第t代中个体i的第j维的行为向量,vi,j(t+1)为粒子速度更新公式;
30、粒子速度更新公式如下:
31、vi,j(t+1)=r1(t)·vi,j(t)+r2(t)·ii,j(t)+r3(t)·ci,j(t)
32、
33、式中,个体k是个体i的演示者,i<k,r1(t)、r2(t)和r3(t)为随机系数,在[0,1]范围内随机生成;vi,j(t)为个体i的第j维在第t代时的速度向量,ii,j(t)表示在第t代中个体i的第j维向适应度好的随机个体k的第j维学习后的行为向量,xk,j(t)为第t代中个体k的第j维的行为向量,xi,j(t)为第t代中个体i的第j维的行为向量;ci,j(t)表示在第t代中个体i的第j维向种群中最优解学习后的行为向量,xgbest(t)为第t代时的最优解xgbest;
34、s54、再次使用训练后代理模型m2,估计子种群sub-pop的子代中粒子的适应度值;
35、s55、根据估计的适应度值对子种群sub-pop和子种群sub-pop的子代中的全部粒子按升序排序,选择包含第m个粒子在内的前m个粒子作为新的子种群sub-pop;
36、s56、在新的子种群sub-pop中选择适应度值最好的粒子定义为子问题最佳解sub-xbest。
37、优选的,所述步骤s4中两阶段特征选择过程是通过径向基函数rbf模型辅助完成,所述训练后代理模型m1和训练后代理模型m2均为径向基函数rbf模型;
38、此外,在所述第一阶段中,用于训练代理模型m的训练集,是根据所述第一阶段中sub维度从存档arc选择的相应维度的解的子集;在所述步骤s52中,用于训练代理模型m的样本,是根据所述步骤s51中子种群sub-pop的维度从存档arc选择的相应维度的解的子集。
39、优选的,所述步骤s7具体步骤为:
40、s71、使用子问题最佳解sub-xbest替换最优解xgbest中相应的维度,获得一个新的最优解xnew-gbest;
41、s72、对新的最优解xnew-gbest进行真实适应度评估,并将新的最优解xnew-gbest及其适应度值存储于存档arc中;
42、s73、比较当前最优解xgbest与新的最优解xnew-gbest的适应度值,如果新的最优解xnew-gbest的适应度值优于当前最优解xgbest的适应度值,则更新当前最优解xgbest;否则当前最优解xgbest不做更新。
43、优选的,停止标准为执行到最大评价次数时终止;此外,每一次评价中只会形成一个子问题并进行优化。
44、优选的,在使用部分再生的昂贵大规模优化方法解决大规模昂贵优化问题之前,还利用matlab对不同的训练集进行加载和预处理,以确保该训练集可以用于大规模昂贵优化问题。
45、本发明提供了一种计算机可读存储介质,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,即可实现一种部分再生的昂贵大规模优化方法。
46、本发明还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,当所述处理器执行时,即可实现一种部分再生的昂贵大规模优化方法。
47、与现有技术相比,本发明具有如下有益效果:
48、1、本发明通过采用代理模型辅助和两阶段特征选择策略对原始大规模优化问题进行降维处理,形成低维子问题,增强算法的收敛性。
49、2、本发明应用rbf辅助改进的社会学习粒子群优化算法sl-pso将传统sl-pso算法向整体平均行为学习的模块更改为向最优解学习,利用改进后的sl-pso产生子种群的子代,并通过环境选择完成子种群更新,寻找到子问题最佳解,增强了算法在子问题上的收敛性,提高了算法的收敛速度。
50、3、本发明提供了一种新的填充采样策略更新最优解和存档arc,即利用子问题最佳解在相应维度上生成新的最优解,通过比较当前最优解和新的最优解的真实评估结果,更新最优解和存档arc。
- 还没有人留言评论。精彩留言会获得点赞!