基于数据隐私分级保护的个性化商品推荐方法
本发明涉及一种基于数据隐私分级保护的个性化商品推荐方法及系统,属于信息安全。
背景技术:
1、随着电子商务的不断发展,商品的数量和种类也急剧增加,消费者不得不投入大量时间来寻找所需的商品。这种浏览大量不感兴趣商品的过程无疑会使用户不断流失。因此,推荐系统已经成为人们生活中不可或缺的一部分。目前的商品推荐系统主要流程包括三个部分:(1)数据提交阶段,每个用户提交自己与商品的交互数据至第三方数据收集者;(2)数据聚合阶段,由积累了大量用户与商品互动数据的第三方数据收集者生成全局推荐模型;(3)推荐生成阶段,每个用户利用第三方数据收集者的全局推荐模型为其生成推荐结果。由于商品推荐系统中的第三方数据收集者存在泄露和滥用用户数据的风险,因此用户越来越强烈地需要一个能解决第三方数据收集者不可信问题,保证其隐私安全的推荐系统。
2、本地化差分隐私是解决第三方数据收集者不可信问题的热点方法之一。本地化差分隐是一种无需可信第三方的隐私保护技术,可应用于数据分析中的个体隐私数据的保护。在本地化差分隐私中,每一个需要隐私保护的个体使用满足本地化差分隐私机制的随机扰动算法对各自的数据进行扰动。数据分析者通过收集扰动后的数据来分析原始个体数据的相关统计学特征。本地化差分隐私提供了用于控制隐私强弱的参数被称为隐私预算,用来保证数据集中增加或者较少一条数据记录,随机输出结果不可区分性的概率,通过该参数可以平衡随机扰动算法的安全性和可用性,隐私预算越小,隐私保护效果越强。拉普拉斯机制是差分隐私中的核心方法之一,具体地,当一个商品数据集d的隐私预算为时,那么会给每次商品数据的查询结果添加一个噪声值noise,这样就可以保护查询结果。noise是从尺度为的拉普拉斯分布中采样得到的随机变量,可以表示为:其中δ表示总体数据集查询结果的敏感度。敏感度由数据集查询结果的最大值和最小值之差,记作:δ=dmax-dmin。
3、现有本地化差分隐私推荐系统已经充分考虑了在数据采集过程中数据被窃取或泄露的可能性。在这套系统中,用户会在数据提交阶段首先对其访问过的所有商品数据执行统一的隐私保护处理,再将处理后的商品数据提交给数据收集者。最后,数据收集者会对采集到的商品数据进行处理,以产生高质量的推荐结果。
4、然而,现有的本地化差分隐私推荐系统主要存在以下两个方面的问题:1.它没有考虑到用户对不同类型的商品可能有着不同的隐私保护级别。举例来说,当涉及到医疗类商品时,用户可能希望保护自己的隐私,避免患病信息的泄露;而对日常生活用品,他们可能希望得到更精准的推荐,而不是过度保护隐私;2.用户为商品数据执行统一隐私保护处理时,引入拉普拉斯机制给数据加噪声值来保护数据隐私。这会对数据的原始分布和质量产生扰动。这些扰动使得数据收集者构建的全局推荐模型在为用户提供推荐时的效果不尽人意。
技术实现思路
1、本发明一种基于数据隐私分级保护的个性化商品推荐方法及系统。它既能满足用户的个性化隐私保护需求,又能减轻由于加入差分隐私噪声所导致的推荐精度下降问题。
2、本发明的核心数学结论:当把整体商品数据分为y类,2≤y≤10,不同的隐私保护级别时,如果希望保证整体商品数据的隐私预算为那么第x类级别商品数据的差分隐私预算必须为:
3、
4、其中,隐私预算是用于控制隐私强弱的参数,隐私预算越小,隐私保护效果越强;商品数据隐私级别类型数n越大,说明商品可选择的隐私保护级别越多。
5、由于矩阵分解模型是广泛应用于推荐系统的核心技术,本系统选择矩阵分解模型作为推荐模型。矩阵分解模型包括:1.一个n×16的用户嵌入向量矩阵,记作uemb,其中n代表用户数量;2.一个m×16的商品嵌入向量矩阵,记作iemb,其中m代表商品数量;3.一个n×m的用户-商品评分矩阵,记作rating,代表n个用户对m个商品的评分。
6、在用户嵌入向量矩阵uemb中,第i行的用户嵌入向量uembi代表用户i的潜在因子,uemb中每一行向量对应一个用户;在商品嵌入向量矩阵iemb中第j行的商品嵌入向量iembj代表商品j的潜在因子,iemb中每一行向量对应一个商品。用户评分矩阵rating第i行第j列的元素rij代表用户i对商品j的评分。同时uembi与iembj的内积值就是用户i对商品j的评分rij,公式表示为:
7、rij=uembi·iembj
8、进一步,uemb与iemb内积即为用户-商品评分矩阵rating,公式表示为:
9、rating=uemb·iemb
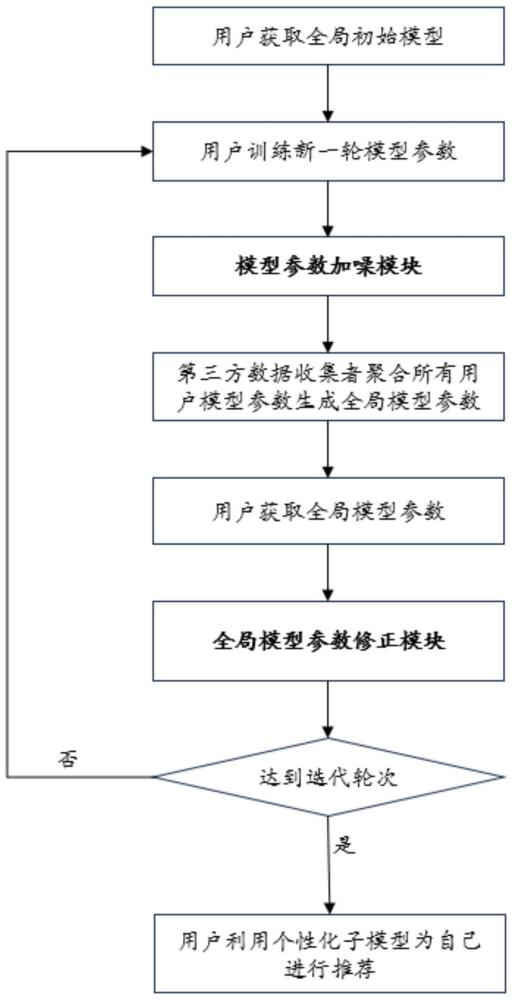
10、本系统的主要参与方包括第三方数据收集者和多个用户。在数据聚合阶段,第三方数据收集者负责收集多个用户上传的模型参数,并聚合这些参数以生成全局模型参数;在数据提交阶段,各个用户使用本地数据训练更新上一轮全局模型参数获得各自的新模型参数,再对新模型参数加入差分隐私噪声,再将带有噪声的模型参数提交至第三方数据收集者。在推荐生成阶段,各个用户在使用本地数据调整全局模型后,再使用其为自己生成推荐结果。该系统的实现步骤如下:
11、步骤(1):在本系统方法运行初始阶段,第三方数据收集者选择矩阵分解模型作为全局推荐模型,并使用均匀分布u(0.05)初始化模型参数
12、步骤(2):第三方数据收集者统计数据集d中用户总数量n和商品总数量m;设置商品整体隐私预算∈g、全局训练轮数t、梯度优化算法学习率γ和商品数据隐私级别类型数y。
13、步骤(3):系统根据上文提到数学结论以及步骤(2)设置的∈g和y计算出隐私保护级别为x的商品隐私预算∈x,其中x∈{1,2,…,y},具体公式为:
14、
15、步骤(4):在每一轮的开始,假设当前为第t轮,服务器将上一轮全局模型的参数发送给每个参与训练的用户。
16、步骤(5):对于每一个用户i,1≤i≤n,n是用户总数,他们使用本地数据d和梯度下降算法来根据上一轮的全局模型参数进行训练和更新。这个过程产生用户i在第t轮的新模型参数具体更新流程如下:
17、1.定义损失函数:矩阵分解模型的预测评分为数据和模型参数输入到模型中得到的结果,记作:
18、
19、损失函数lossi是针对用户i,计算其评分过的所有商品的真实评分rij和模型预测评分的差的平方值的总和。具体表达式为:
20、
21、其中m是商品总数。损失值lossi越大,说明模型的预测值和真实值差距越大,预测效果越差。
22、2.计算模型梯度:根据定义的损失函数lossi,计算模型参数相对于损失函数的梯度。梯度是一个向量,它指向损失函数在参数空间中增长最快的方向。数学表达式为:
23、
24、3.更新模型参数:使用梯度下降法更新模型的参数。参数更新表达式如下:
25、
26、其中i表示用户的标识、t表示当前训练轮次,γ是梯度优化算法学习率。
27、步骤(6):每个用户根据的自己隐私保护需求将所有商品j分成y类,2≤y≤10,与隐私保护级别数y相对应,使得每个商品j都具有自己的隐私保护级别x,其中x∈{1,…,y},j∈{1,…,m}。
28、步骤(7):在矩阵分解模型中,商品j和模型参数中子模型参数存在一一对应的关系。因此,对于每一个用户i,1≤i≤n,n是用户总数,他们为每个商品j,1≤j≤m,m是商品总数,相应的模型参数添加基于隐私保护级别x的噪声,记作noisex。这样,用户i得到一个满足个性化隐私保护需求的噪声模型参数为每个商品j添加噪声具体公式为:
29、
30、其中i表示用户的标识、t表示当前训练轮次。最后,用户将噪声模型参数提交至第三方数据收集者。
31、对步骤(7)的补充说明:用户从拉普拉斯分布中随机采样出每个商品对应模型参数需加入噪声noisex,∈x是步骤(3)中计算出的隐私预算,t为步骤(2)设置的全局训练轮数。随机采样是指从尺度为拉普拉斯分布中随机取得任意一点数值,每次采样数值noisex都不一样,但是多次采样后的所有数据会服从拉普拉斯分布。
32、步骤(8):在第t轮训练中,第三方数据收集者收集了所有用户上传的模型参数其中i表示用户的标识、t表示当前训练轮次。然后,第三方数据收集者通过聚合所有用户上传的模型参数求平均值来计算出全局模型参数这个全局模型参数将用于下一轮的模型训练。具体公式:
33、其中n是总用户数量
34、步骤(9):在训练轮次达到预设的t后就终止模型训练过程。否则,各用户将继续使用第三方数据收集者发布的全局模型参数回到步骤(4)进行下一轮的模型训练。
35、步骤(10):训练流程终止后,各用户将得到一个经过优化且满足个性化隐私保护需求的全局商品推荐模型参数mg。
36、步骤(11):本发明中提出一种方法来改善噪声对模型参数mg的影响:首先,每个用户先利用本地数据和初始模型在本地使用传统梯度下降算法重新训练出一个新的本地模型mil。具体来说,用户使用本地数据按照步骤(5)对初始模型参数重复训练t轮得到mil。
37、步骤(12):每位用户j根据本地数据统计出其访问过的商品id集合pi;由于每个用户只会访问整体商品中的一部分,所有集合pi一定是全局商品id集合q={1,2,…,m}中的子集,记作然后,用户i根据集合pi中的商品id将模型参数mg分成两部分:由于商品id与mg中的每一行一一对应,所以本发明根据商品id集合pi和全局商品id集合q把全局模型参数mg拆成两部分mign和miga,其中miga是集合pi中商品所对应模型参数,mign是集合q-pi中商品所对应的嵌入向量行组成模型参数。
38、步骤(13):每个用户i计算本地模型参数mil和全局模型参数miga中每一行的余弦相似度。具体来说,对于集合pi中每个商品id=j,j∈pi,其对应的milj和migaj的余弦相似度为:
39、
40、步骤(14):每个用户i本地模型参数mil和模型参数miga的余弦相似度等于所有集合pi中商品j对应的milj和mgaj余弦相似度的均值,具体公式为:
41、
42、步骤(15):每个用户i基于此余弦相似度simi对全局商品推荐模型参数mg中mign参数进行调整,具体来说:
43、(1)定义一个函数fi:
44、fi=(|simi-cos(mign-ki*noisex,mign)|)2
45、其中noise为步骤(4)中加入的相应隐私等级为x噪声,ki是一个未知系数。
46、(2)定义损失函数lossi:
47、
48、(3)求解系数ki:对损失函数lossi使用梯度下降法来求解系数ki的值,每轮对ki的具体优化公式如下:
49、
50、其中γ是预设的梯度优化算法学习率。当ki连续两轮值相差小于0.01时即可停止,得到系数ki的值
51、步骤(16):每个用户i获得新的模型m′ign就是根据系数ki对全局商品推荐模型参数mign中每一行参数mignj进行调整。具体来说,对于集合q-pi中每个商品id=j,j∈pi,商品j对应嵌入向量行mignj调整公式为:
52、m′ignj=mignj-ki*noisee
53、那么新的个性化子模型m′ig就是m′ign与mil横向拼接起来。这个个性化子模型m′ig能够为用户提供更加准确的商品推荐结果。
54、有益效果
55、本发明旨在解决两大核心问题:一是现有的本地化差分隐私推荐系统在进行商品的个性化差分隐私保护时,可能损害整体商品的隐私保护条件;二是采用本地化差分隐私导致的推荐效果下降。为此,我们提出了一个数学公式,明确描述了在确保用户整体商品隐私预算不受影响的情况下,如何为具有不同隐私级别的商品分配特定的隐私预算。该系统在遵循整体商品隐私保护条件的同时,满足用户的个性化隐私需求。此外,用户还可以基于自己的数据对全局推荐模型进行调整,从而获得一个针对其需求的个性化子模型,以实现更精确的商品推荐。总的来说,本发明从个性化隐私保护和个性化模型两个维度出发,针对本地化差分隐私推荐系统中存在的问题,提供了一种全新的隐私保护方案。
- 还没有人留言评论。精彩留言会获得点赞!