基于情感分析和大模型驱动的数字人校园场景系统
本发明属于人工智能,特别是结合了大语言模型预测、情感分析和数字人技术的综合应用。通过优化校园环境中的人机交互体验,以及自然语言处理和情感智能,提升数字人与用户之间的交流质量。
背景技术:
1、数字人系统在处理不同场景下的人机交互任务,可简要分为几个步骤:文本生成,语音生成,动画生成。数字人完成任务的优良性由其所使用的上述技术所决定,简单的问答活动只需对文本进行nlp分析并回答预设的文本内容即可,想要进一步提示数字人的表现力,则需要使用复杂的技术来理解用户的输入,产生回答文本,生成匹配的语音及肢体动画等。
2、大语言模型是自然语言处理(nlp)领域的重要成果,起源于机器学习和深度学习的进步。早期的文本生成模型如n-gram和基于规则的系统逐渐演化为更复杂的神经网络模型,尤其是在transformer架构的推动下,文本生成效果得到了长足的进步。transformer架构是llm,large language model的核心,由自注意力机制和前馈神经网络组成,优化了长距离依赖关系的处理。这种架构使得llm能够处理复杂的语言结构,提高了语言理解和生成的准确性。llm通常经过大规模数据集的预训练,学习语言的广泛模式和结构。预训练后,llm可以通过微调来适应特定的应用或任务,如情感分析、文本摘要、问答系统等。
3、传统情感分析通常基于特定的规则或简单的机器学习技术,如支持向量机或朴素贝叶斯分类器。使用关键词和词语情感倾向字典,来识别文本中的情感表达。结合词频、词性标注和句法分析来判断整体情感。
4、在处理简单文本或明确情感表达时效果较好,但难以捕捉复杂或隐含的情感。对于数字人领域,传统情感分析方法无法对上下文信息,以及特定环境的不同情感特点产生回应。这对需要表现连续性情感变化的数字人来说是致命的。特别的,在文本到语音的转换中,缺少情感标注的模型难以产生连贯的情感表达,容易出现情绪断层,上下文情感变化生硬的问题,即使使用了情感标注模型,在不考虑上下文的情况下也无法产生良好的效果。
5、伴随着广大师生需处理问题的复杂化,早期建立的校园服务体系的使用复杂度也逐步增加。例如学工系统中,如果需要完成一项不经常使用的活动,面对繁杂的网络空间往往会无从下手,这是在改善师生校园体验,提升校园服务质量中亟需解决的问题。
6、知识库:知识库(knowledge base)是一个用于存储复杂结构化和非结构化信息的技术系统。这些信息通常是以一种易于检索和分析的方式组织的。它们通常构建在数据库管理系统之上,并利用人工智能和自然语言处理技术来提高数据处理和检索的效率。
7、结构化数据存储:以结构化的形式存储数据,例如关系数据库或图形数据库。
8、自然语言处理:用于处理和理解用户查询以及知识库中的非结构化数据。
9、人工智能和机器学习:用于从大量数据中提取有用信息,以及不断优化知识库的内容和检索效率。
10、语义网和本体论:用于构建和管理知识的复杂关系,使得知识库不仅仅是信息的集合,而是能够反映实体之间复杂关系的系统。
技术实现思路
1、智慧校园场景是本发明的一个重要应用场景。目前,智慧校园系统是基于信息技术和通信技术(ict)的综合应用,旨在创建一个更有效率、互联互通的校园环境。
2、本发明致力于改善特定情境下,用户通过文本交流获取信息的方式。并具体结合校园情景,创造出符合高校需求的,切实满足学生需要的数字人。对于数字人,传统的方法已经可以基于用户的输入产生回答,并通过文本分析方法产生回答,以及通过例如数字人的载体进行呈现,但在实际使用中仍然存在大量问题,对于传统校园网络,尽管集成了大量信息,在检索,实现学生需求时也面临问题:
3、1、使用传统nlp方法往往难以理解用户复杂的语义,并很难生成有效回答,往往只能基于问题分类回答预设文案,在交流中缺失灵活性。
4、2、基于llm的文本预测方法虽然可以改善回答的效果,但若想适用于特定语境,例如校园或博物馆,则会产生问题,主要出现在:传统的微调方法并不适用于经常更新的数据。这是因为一旦模型完成了训练,它就只能反映到那个时间点的知识状态,无法自动更新或纳入新信息;对于需要回答特定文章中的内容等细节问题,仅依赖微调的模型可能无法提供精确答案。这主要是因为微调过程中模型无法记住所有细节,尤其是对于非常大的数据集或特定文本。
5、3、在同数字人的交互中,数字人常常无法表现连贯的情感变化,这是因为情感分析往往欠缺对上下文的理解,无法体会深层次的,隐晦的情感变化,并难以产生符合情感的连贯动作。在与数字人的交互过程中,除去获取信息的准确性外,情感互动的性能是决定数字人质量的第二大核心指标。在实际的数字人交互过程中,尽管可以获取到信息,但往往由于不生动的表述,僵硬的语气,而使得用户和数字人的交互体验差,以至于不愿使用数字人系统,使数字人难以实现原有的目标。
6、4、知识库更新,传统基于llm模型预测文本的方法,虽然能产生优质的文本,但难以产生特定环境下准确的回答,同时微调模型无法实现内容的精准更新,若想即使调整某一方面回答的具体内容,需要更好的更新数据方案。
7、5、校园网络的不足:当今,各大高校普遍使用网络完成校园诸多日常事宜,学生需要在各种校园网站进行操作,来满足日常学习,和校园情景下各种需求的实现,伴随着校园业务的复杂化,这种操作会日益繁琐,对于复杂的校园网络空间,也很难快速检索到所需信息。
8、为解决以上问题,本发明旨在通过知识库改进大语言模型,实现数字人知识库的灵活更新,提高回答的准确性。同时强化其对情感的分析能力,并借此产生更为合理连贯的表情及动作。并基于上述方法生成数字人,完成优质的人机交互。
9、本发明采用的技术方案为基于情感分析和大模型驱动的数字人校园场景系统,包含用户输入获取模块、校园知识库模块、llm模型文本预测模块、情感分析模块模块、语音合成模块和表情及肢体动作驱动模块。
10、用户输入获取模块负责接收用户的输入文本和上下文信息,进行预处理后进一步传递到校园知识库模块。
11、校园知识库模块将获取到材料信息后和用户的上下文一同被送入llm模型文本预测模块;所述llm模型文本预测模块中的llm模型使用上下文信息和已检索到的材料来生成回答消息的文本。
12、生成的文本回答随后传递到情感分析模块,以进行情感分析。情感分析模块分析回答消息的情感内容,以确定其中包含的情感信息。
13、带有情感信息的回答消息文本和情感分析结果传递到语音合成模块,文本被转化成具有情感标注的语音,生成的语音传达情感和回答消息。
14、最后,生成的语音以及情感信息传递到表情及肢体动作驱动模块。表情及肢体动作驱动模块负责创建数字人动画,以实现对数字人的驱动。
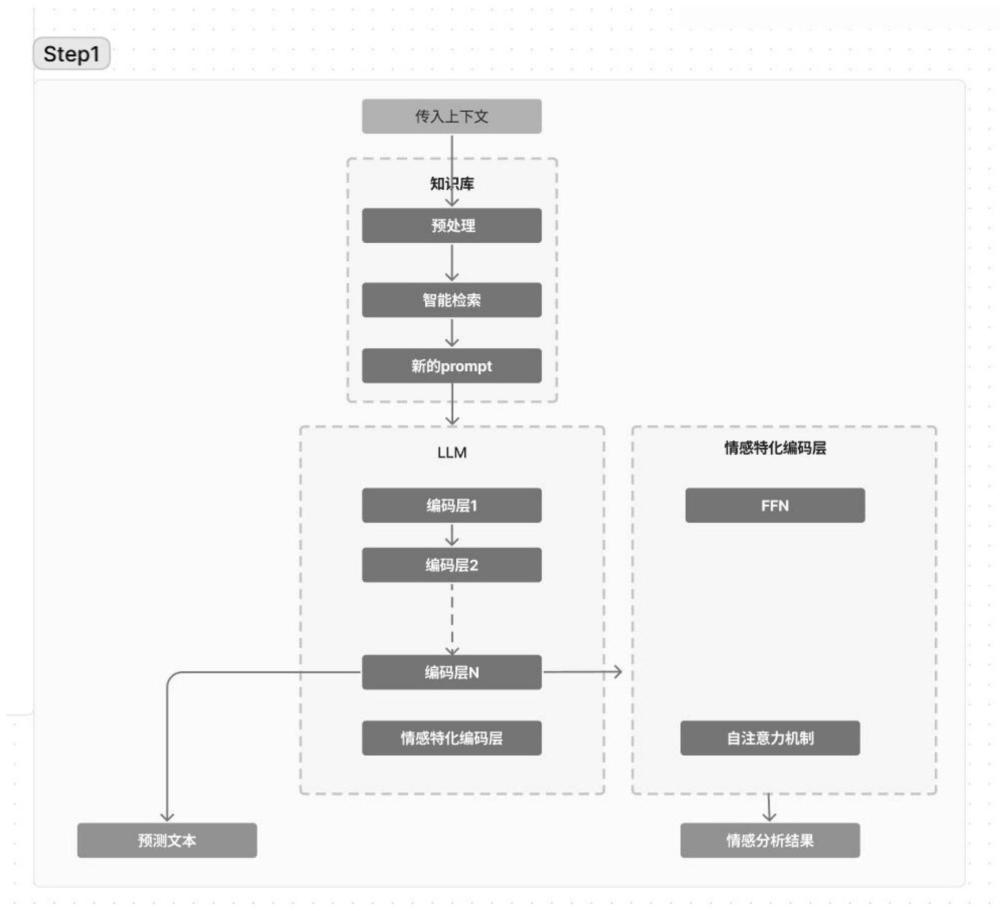
15、进一步地,所述用户输入获取模块中,输入获取:系统首先捕获用户的输入,首先通过预处理模块,进行分词和语义理解,提取所述文本内容中的关键信息。进行转化后接入预先准备好的数据库,遍历用户所提到的关键词,通过基于langchain架构的知识库生成回答所需要的全部准确信息。其次将这些资料与上下文结合,并附加prompt传入llm文本预测模型。
16、进一步地,所述校园知识库模块中,校园知识库是使得校园场景下文本交互数字人得以实现其功能的核心组件,在获取授权后通过网络爬虫等手段,对校园网络信息进行整合,使用longchain知识库框架,使得回答问题所需要的信息可以通过自然语言进行获取,在对用户的输入进行简单处理后即可使用数据库获得回答所需的知识及资料,这些资料一并传入llm进行回答文本的预测,以保证用户可以获取准确的校园知识信息。
17、进一步地,llm模型文本预测模块中,将处理过的用户输入以及回答所需的知识信息传入llm模型进行对文本的预测。首先再次对文本进行格式化,去噪和标准化以确保数据的一致性。随后还需将文本分为能够理解的单元,即格式化处理。进行完这一步,已经将用户的问题和可能会用到的全部知识数据进行融合。
18、随后,将完整上下文数据输入模型的嵌入层,将文本标记转化为向量形式,这些向量捕捉了单词的短语或语义特征。
19、在编码层中,自注意力机制帮助模型理解不同文本和标记之间的关系,再后文嵌入情感分析模块时也利用了自注意力机制的深层次辅助理解能力,自注意力机制尤其擅长进行文本中长距离元素的依赖分析,以及对不同上下文中的单词含义进行识别。接着,进入前馈神经网络(ffn),transformer模型的每个编码层都会包含一个ffn用于对自注意力层的输出进行进一步处理。
20、通过多个编码层处理,模型可以捕捉到输入文本的深层次上下文关系,正是这一步使得用户的输入理解和知识库信息融合得以同步进行,产生精准又生动的回答。
21、进一步地,情感分析模块中,在上文获得完整的回答后先进行文本的输出,在此之后将上下文进一步向下传递到特殊的编码层中。为强化模型的情感分析模式,建立了专用强化情感分析的编码层,针对传统的transformer模型中的自注意力机制及ffn进行了调整。ffn在transformer模型中起到提升模型表达能力的作用。它通过非线性变换来增强模型的学习能力。在实践中,我们对ffn进行了定制化训练,使其可以更好的处理文本中隐含的情感信息。
22、在训练的阶段,使用带有明确情感标签的数据集来训练模型,使其使用不同类型的情感表达,并对transformer结构中的自注意力部分也进行调整,增强其捕捉上下文关系的能力。在完成情感分析之后,系统产生了能体现整个上下文语境,并符合逻辑的情感分析结果。
23、进一步地,语音合成模块中,在完成文本预测和情感分析之后,下一步是将这些文本和情感信息转换为语音。这一步涉及到语音合成技术的应用,特别是结合了ert情感分析的vits系统。
24、文本到语音转换(tts):使用vits,一种高级的文本到语音(tts)转换模型,将生成的文本转换为语音。vits是基于深度学习的模型,能够产生高质量、听起来自然的语音。
25、基于前面提到的情感分析模块的结果,bert模型分析文本中的情感倾向,并调整语音的语调、节奏和强度以反映这些情感。例如,如果文本表达的是快乐的情感,语音将会更明快和高调;如果是悲伤的,语音会更低沉和缓慢。
26、进一步地,表情及肢体动作驱动模块中,预设一个包含多种动作的库,每种动作都与特定的情感或情感组合相关联。动作库中的动作通过动作捕捉技术预先录制,以确保自然性和真实性。匹配与生成:根据从llm和情感分析模块得到的信息,系统从动作库中选择合适的动作序列。使用决策树及神经网络,以确保动作的自然性和适应性。使用线性插值(linear interpolation)或贝塞尔曲线(bezier curves)来平滑地过渡和融合不同的动作。这些技术可以确保动作之间的自然和流畅过渡。利用简单的时间匹配技术,如时间戳对齐,来确保动作与语音的同步。时间戳对齐将动作的关键帧与语音的特定时间点匹配起来。
27、系统工作流程如下:
28、s1:获取到用户的输入及上下文信息。
29、s2:对获取到的文本进行文本预处理;
30、s3.1:将处理过的文本信息在校园信息知识库中检索,获取所需材料;
31、s3.2:将材料和上下文传入llm文本预测模型进行回答消息的文本生成;
32、s3.3进一步使用网络的情感分析层中数据返回包含上下文逻辑的情感信息;
33、s4将获得的回答消息文本与情感分析结果传入文本合成语音模型,对文本进行情感标注后生成语音;
34、s5基于语音和情感信息生成数字人动画以实现对数字人的驱动;
35、与现有技术相比较,本发明通过对用户信息的深度处理,结合大语言模型技术,一方面从校园信息知识库中可以获取准确信息,一方面结合情感分析能力,产生符合上下文逻辑的情感信息,最终使得数字人得以生成优质的语音资料,并产生符合情景和情感的数字人动作,使得用户同数字人在交互的过程中,不仅可以获取准确的信息,还可以在交互过程中产生真实、生动的交互体验。结合校园场景的实际使用,用户可以通过该系统,以自然语言的形式,获得清晰的校园信息,完成校园业务流程引导,信息查询等工作,并通过结合情感分析的数字人驱动方法获得良好的使用体验。
- 还没有人留言评论。精彩留言会获得点赞!