一种面向实时场景补全的占据网络
本发明涉及一种面向实时场景补全的占据网络。
背景技术:
1、场景补全是3d感知中的一项关键任务,使自动驾驶和机器人系统能够在复杂环境中有效地理解和导航。其基本任务包括分析传感器数据,以准确地为每个空间区域分配语义标签,从而能够对整个3d场景进行详细描述。该描述不仅包括环境的几何结构,还赋予物体和地理特征语义。在三维语义场景完成中,激光雷达和相机是主要的传感器。激光雷达点云提供了精确的深度和稳定性,但稀疏性是一个显著的缺点。相反,图像提供丰富的颜色数据,但提供较弱的深度信息,通常需要大量计算来提取3d细节。这种限制对自动驾驶尤其不利,因为自动驾驶对实时性有严格的要求。此外,当前基于相机的方法在语义完成和几何重构能力方面都落后于基于激光雷达的方法。因此,采用激光雷达传感器作为输入成为实时3d语义场景完成方法的首选。
2、由于自动驾驶感知环境的迫切需求,已经提出了许多3d语义场景完成的方法。在使用激光雷达作为输入的方法中,根据其表示,可以将其分为两类:基于点云的方法和基于占用网格的方法。基于点云的方法以其在语义场景完成方面的卓越性能而闻名,这归功于提供高度详细的位置和深度信息的点云。该属性使基于点的方法能够精确捕捉对象边界和复杂细节,从而增强模型区分不同对象的能力。基于占用网格的方法利用从点云导出的体素化表示作为输入,其中每个体素存在于两种状态之一:占用或未占用。因此,与点云相比,占用网格提供的信息更少详细,导致语义完成能力较弱。然而,基于占用网格的方法通常由于其较低的分辨率而提供更快的推理速度。目前,处理占用网格的两种主要方法是:一种利用占用网格的完整3d数据,另一种丢弃高度维度,将其转换为2d占用网格。如lmscnet,采用2dunet架构作为骨干网络。该架构具有广泛的多尺度跳跃连接,旨在增强特征传播。尽管这种方法显示出更快的推理速度,但其在占用网格分辨率方面的局限性对捕获细粒度特征提出了挑战,导致语义场景完成性能不理想。相比之下,利用3d占用网格的方法往往在语义场景完成方面提供优异的性能,尽管代价是相对较慢的推理速度。如udnet,采用了类似于3dunet的网络结构,并引入了一些关键技术,如自上而下的块、收缩空间金字塔池和多尺度融合机制,以有效地结合上下文信息。这些改进提高了语义场景完成的准确性。然而,需要注意的是,使用udnet实现实时性能仍然是一个挑战。motionsc再次利用称为时空金字塔的2d卷积骨干网络。该网络架构专门设计用于处理临时堆叠的占用网格。与udnet相比,motionsc的语义完成性能略有下降,但它在推理速度和实时性方面表现出色。因此,困难在于在3d占用网格方法的水平上保持语义场景完成性能,同时保持类似于2d占用网格方法那样的推理速度。
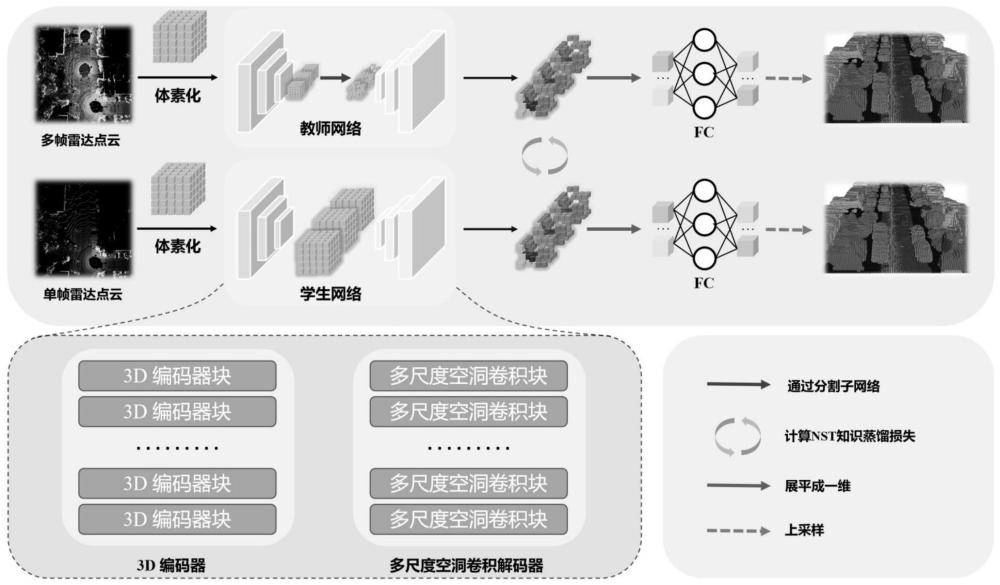
3、为了解决上述挑战,本文介绍了一种新的方法,即面向实时场景补全的占据网络,它采用了一种简单的编码器-解码器架构。我们的方法保留了占用网格的高度信息,并开发了一种具有相当大感受野的简单而有效的3d编码器。然而,仅依靠结构简单的3d编码器进行特征提取在捕捉各种特征方面存在局限性。为了克服这一问题,我们提出了一种多尺度扩展卷积解码器来集成来自不同尺度的特征。此外,考虑到单帧激光雷达点云数据的内在稀疏性和实时性能的必要性,我们提出了一种具有多帧输入的教师网络,通过引入知识蒸馏技术来指导具有单帧输入的学生网络(面向实时场景补全的占据网络)。然而,由于稀疏点云无法提供足够的空间信息来区分对象之间的边界,因此仅依赖相邻的激光雷达帧并不能有效地克服稀疏点云在远处造成的障碍,这导致了语义完成方面的困难。因此,提出了一种自动选帧算法来选择在评估范围内最大化覆盖范围的未来帧,从而缓解单帧激光雷达中的稀疏性问题。此外,考虑到无法直接从激光雷达获得占用网格,我们还将点云转换为占用网格的过程纳入网络中。
技术实现思路
1、本发明的目的在于为了能够保持实时性能,获得更好的场景补全性能;解决对小物体补全的问题,适应场景中不同大小物体的补全;解决单帧激光雷达稀疏和不完全的问题,提供一种面向实时场景补全的占据网络。
2、为实现上述目的,本发明的技术方案是:一种面向实时场景补全的占据网络,包括如下步骤:
3、步骤s1、使用自动选帧算法选择最优的未来2帧激光雷达点云,并将第3帧(当前帧)和过去的相邻2帧激光雷达点云对齐到第3帧激光雷达点云的坐标系下;
4、步骤s2、通过体素化分别将5帧激光雷达点云和第3帧激光雷达点云转换为3d占据网格,作为教师网络和学生网络的输入;
5、步骤s3、输入经过教师网络和学生网络,得到通过3d编码器和多尺度空洞卷积解码器后的占据网格特征;
6、步骤s4、通过nst知识蒸馏损失函数,计算步骤s3两个占据网格特征之间的相关性,强迫学生网络学习教师网络的特性;
7、步骤s5、通过全连接共享占据网格中每个体素之间的特征,并将占据网格进行上采样,得到最精细的占据网格。
8、在本发明一实施例中,所述步骤s1具体实现过程如下:
9、首先计算每个未来帧与当前帧(第3帧)的距离,即前两帧的点云中心到第3帧点云中心的距离,与两个距离阈值(由于有两帧未来帧,因此两个距离阈值是指未来帧到当前帧的距离阈值)进行比较,距离阈值是按照占据网格的评估范围计算的;大于距离阈值的未来帧就是被选择的最合适的帧。若是未找到符合条件的未来帧,则在剩下的未来帧中找到两帧离当前帧最远距离s与离当前帧距离为s/2的两帧作为补充;然后根据第i帧相对当前数据集第1帧的旋转矩阵r1i,通过以下公式计算出每帧相对当前帧的旋转矩阵rci;
10、
11、其中,rab为第b帧到第a帧的旋转矩阵,a,b∈{1,c,i};然后通过以下公式,将每帧的坐标转换到当前帧的坐标系之下,得到总点云ptotal;
12、
13、其中,pi为第i帧的点云,n表示n帧点云需要坐标转换,在本说明书中n为4。由此获得在评估范围内均匀分布的多帧激光雷达点云。
14、在本发明一实施例中,所述步骤s2具体实现过程如下:
15、由得到的ptotal(5帧点云总和,作为教师网络输入)和pc(当前帧点云,作为学生网络输入),根据评估范围rx,ry,rz去除不在范围内的点,并体素化成占据网格
16、
17、其中voxlize(·)表示点云体素化,表示向下取整,s表示每个小体素的大小p={ptotal,pc};通过体素化,得到学生网络和教师网络的占据网格输入和
18、在本发明一实施例中,所述步骤s3具体实现过程如下:
19、首先将占据网格分别经过教师网络和学生网络的3d编码器得到编码后的特征
20、
21、其中表示第n个3d编码器块,c表示特征通道数;整个3d编码器由n个相同结构的3d编码器块组成;学生网络和教师网络的3d编码器块个数不一样;
22、然后再经过多尺度空洞卷积解码器得到解码器输出和编码器输出的张量形状一样;解码器由多个结构相同的解码器块组成,单个解码器块过程表示如下:
23、
24、其中φn(·),n∈{1,2,3}代表不同膨胀系数空洞卷积组成的路径;每条路径的总膨胀系数分别为{3,3,3}、{9,9,5}和{19,19,3}。
25、在本发明一实施例中,所述步骤s4具体实现过程如下:
26、由步骤s3得到教师网络和学生网络中解码器的输出和然后通过nst知识蒸馏损失函数来监督学生网络学习教师网络的特性:
27、
28、其中m和n分别为特征张量x、y中的元素xi和yi的个数,k(x,y)=(xty)2是nst中的多项式核函数;x、y分别代表和
29、在本发明一实施例中,所述步骤s5具体实现过程如下:
30、为共享所有小体素之间的特征,使用全连接层实现特征之间的共享,首先将占据网格特征展平:
31、
32、其中,flatten(·)表示将形状为的特征展平为的形状,再经过全连接:
33、
34、其中fc(·)为全连接网络层,最后重新塑形成占据网格:
35、
36、其中reshape(·)表示将形状为的特征重塑成的形状;然后通过密集上采样,将每个小体素平均切分成8个更小的体素,并且将特征也平分给这八个小体素;以此达到将整个占据网格上采样为原来的两倍:
37、
38、其中upsample(·)为密集上采样函数;然后将结果的中每个体素的特征进行归一化,将概率值最大的序号最为当前体素的类别,以此更新整个体素得到最终的输出。
39、相较于现有技术,本发明具有以下有益效果:本发明提出了一种面向实时场景补全的占据网络,以教师网络为指导,在保持实时能力的同时提高语义完成性能。另外,我们提出了一种3d编码器来获得更大的特征感受野,并设计了一种多尺度扩展卷积解码器来实现多尺度的有效特征聚合。此外,编码器和解码器的块计数都是可定制的,以适应不同的硬件能力。针对点云的稀疏性,提出了一种自动选帧算法,提高了教师网络的性能,增强了网络的监督能力。
- 还没有人留言评论。精彩留言会获得点赞!