用于大模型一体机的数据加密安全保护方法与流程
本发明涉及数据处理,具体涉及用于大模型一体机的数据加密安全保护方法。
背景技术:
1、办公一体机是一种常见的大模型一体机设备,作为一件现代办公室不可或缺的设备,其融合了多种功能,包括打印、扫描、复印和传真等,以达到提高工作效率和简化办公流程的效果,办公一体机内置了大容量的存储器,用于保存各种文档、扫描数据和打印任务,这些数据涉及敏感的财务信息、客户记录和商业文件,并且在传输时需要保证传输文件的防篡改和偷窥,并且实现数据备份操作,因此需要对办公一体机内的存储数据经过加密保存,避免敏感信息的丢失。
2、一体机设备中的明文数据具有较高的频率特征,即有强特征性,混沌加密算法对明文数据的强特征具有较高的敏感度,所以通过混沌加密算法对明文数据加密后,获得的密文数据中任然保留着明文数据的强特征,导致密文数据容易被破解,密文数据的安全性低。
技术实现思路
1、本发明提供用于大模型一体机的数据加密安全保护方法,以解决现有的问题。
2、本发明的用于大模型一体机的数据加密安全保护方法采用如下技术方案:
3、本发明一个实施例提供了用于大模型一体机的数据加密安全保护方法,该方法包括以下步骤:
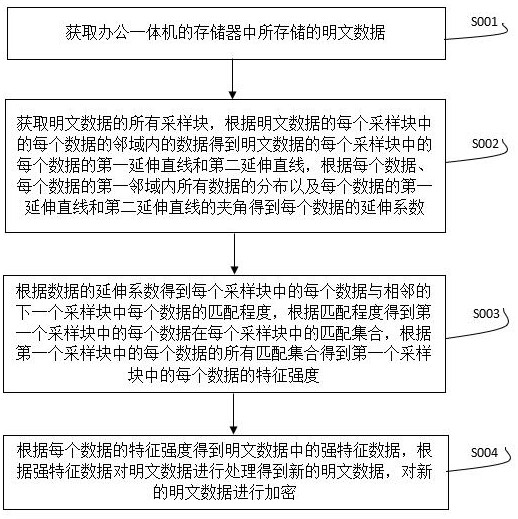
4、将办公一体机的存储器中存储的每个文件作为明文数据;
5、将明文数据作为第一个采样块,对第一个采样块进行多次的下采样获得明文数据的所有采样块,将每次下采样的结果作为一个采样块,根据每个采样块中的每个数据的邻域内的数据得到每个采样块中的每个数据的第一延伸直线和第二延伸直线,根据每个数据、每个数据的第一邻域内所有数据的分布以及每个数据的第一延伸直线和第二延伸直线的夹角得到每个数据的延伸系数,所述每个数据的延伸系数表征了每个数据的邻域内数据之间的差异;
6、根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度,根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合,根据第一个采样块中的每个数据的所有匹配集合得到第一个采样块中的每个数据的特征强度;
7、根据每个数据的特征强度得到明文数据中的强特征数据,根据强特征数据对明文数据进行处理得到新的明文数据,对新的明文数据进行加密。
8、进一步地,所述明文数据的所有采样块的具体获取步骤如下:
9、统计明文数据中行字符个数和明文数据中的所有行数,将明文数据的所有行中字符个数最多的一行的字符个数记为hs,将明文数据中的所有行数记为h,根据hs和h得到调整行数,公式为,其中,表示对进行向下取整;从明文数据的第一行开始,将明文数据中的每h行作为二维平面上一行的数据,依次将明文数据转换在二维平面上的数据;然后对二维平面上的数据进行下采样操作,将每次下采样后的结果记为一个采样块;得到明文数据的所有采样块;
10、其中,每个采样块中的每个数据是一个字符。
11、进一步地,所述根据每个采样块中的每个数据的邻域内的数据得到每个采样块中的每个数据的第一延伸直线和第二延伸直线,包括的具体步骤如下:
12、以每个数据为中心点,获取个数据个数的邻域,将其记为第一邻域;再获取每个数据的八邻域,将其记为第二邻域,其中,a为预设阈值;
13、将明文数据的每个采样块中的任意一个数据记为目标数据,先获取目标数据的第二邻域,计算目标数据与对应的第二邻域内每个数据之间的差异,将与目标数据差异最小的第二邻域内的一个数据记为第一方向数据,将与目标数据差异第二小的第二邻域内的一个数据记为第二方向数据;其中,差异表示差值的绝对值,且每个数据之间的差异计算是通过十进制数进行运算的,即首先将每个字符转换为二进制数,再将二进制数转换为十进制数;
14、将目标数据的第二邻域内的所有数据记为标记数据,在目标数据的第一邻域内获取第一方向数据的第二邻域内的数据,将第一方向数据的第二邻域内的数据除去标记数据后剩余的数据记为第一方向数据的第三邻域,计算第一方向数据与对应的第三邻域内每个数据之间的差异,将与第一方向数据差异最小的第三邻域内的一个数据记为第三方向数据;
15、在目标数据的第一邻域内获取第二方向数据的第二邻域内的数据,将第二方向数据的第二邻域内的数据除去标记数据后剩余的数据记为第二方向数据的第三邻域,计算第二方向数据与对应的第三邻域内每个数据之间的差异,将与第二方向数据差异最小的第三邻域内的一个数据记为第四方向数据;
16、再获取目标数据、第一方向数据、第二方向数据、第三方向数据和第四方向数据的位置坐标,通过目标数据、第一方向数据和第三方向数据的位置坐标使用最小二乘法进行直线拟合,将得到的直线记为第一延伸直线;通过目标数据、第二方向数据和第四方向数据的位置坐标使用最小二乘法进行直线拟合,将得到的直线记为第二延伸直线。
17、进一步地,所述根据每个数据、每个数据的第一邻域内所有数据的分布以及每个数据的第一延伸直线和第二延伸直线的夹角得到每个数据的延伸系数,包括的具体步骤如下:
18、每个数据的延伸系数的计算公式为:
19、
20、式中,表示第j个采样块中的第k个数据,表示第j个采样块中的第k个数据的第一邻域内所有数据的均值,表示第j个采样块中的第k个数据的第一延伸直线和第二延伸直线的夹角,表示余弦函数,表示第j个采样块中的第k个数据的延伸系数,表示绝对值符号。
21、进一步地,所述根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度的具体公式如下:
22、
23、式中,表示第j个采样块中的第k个数据,表示第j+1个采样块中的第个数据,表示第j个采样块中的第k个数据的延伸系数,表示第j+1个采样块中的第个数据的延伸系数,表示第j个采样块中的第k个数据与第j+1个采样块中的第个数据之间的匹配程度,表示以自然常数为底的指数函数,表示绝对值符号。
24、进一步地,所述根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合,包括的具体步骤如下:
25、将第一采样块中的任意一个数据记为参考数据,计算参考数据与第2个采样块中每个数据之间的匹配程度,获取参考数据与第2个采样块中每个数据之间的匹配程度大于或者等于预设阈值t的所有数据,组成参考数据的第一匹配集合;
26、从第一匹配集合中的第一个数据开始,依次遍历第一匹配集合中的每个数据,计算第一匹配集合中第一个数据与第3个采样块中每个数据之间的匹配程度,获取第一匹配集合中第一个数据与第3个采样块中每个数据之间的匹配程度大于或者等于预设阈值t的所有数据,将其记为第一匹配集合中第一个数据的匹配集合;然后再计算第一匹配集合中第二个数据与第3个采样块中每个数据之间的匹配程度,获取第一匹配集合中第二个数据与第3个采样块中每个数据之间的匹配程度大于或者等于预设阈值t的所有数据,将其记为第一匹配集合中第二个数据的匹配集合;依次遍历第一匹配集合中的每个数据,得到第一匹配集合中每个数据的匹配集合,对第一匹配集合中所有数据的匹配集合进行并运算,将得到的结果记为参考数据的第二匹配集合;
27、同理再根据第二匹配集合中每个数据与第4个采样块中每个数据之间的匹配程度,得到参考数据的第三匹配集合;
28、依次,当相邻两个采样块的两个数据之间的匹配程度没有一个大于或者等于预设阈值t时停止;
29、此时,则得到参考数据在每个采样块中的匹配集合。
30、进一步地,所述根据第一个采样块中的每个数据的所有匹配集合得到第一个采样块中的每个数据的特征强度,包括的具体步骤如下:
31、每个数据的特征强度的计算公式为:
32、
33、式中,表示明文数据中第个数据的所有匹配集合中的数据总个数,表示明文数据中第个数据的所有匹配集合的个数,表示明文数据中第个数据的特征强度,表示以自然常数为底的指数函数,c表示下采样的次数,为预设阈值。
34、进一步地,所述根据每个数据的特征强度得到明文数据中的强特征数据,包括的具体步骤如下:
35、当明文数据中的每个数据特征强度大于或者等于预设阈值th时,则判定该数据为强特征数据。
36、进一步地,所述根据强特征数据对明文数据进行处理得到新的明文数据,包括的具体步骤如下:
37、将明文数据中除了强特征数据之外的所有数据记为非强特征数据;
38、随机生成一个盐序列,在明文数据中的所有强特征数据后面加入盐序列,得到新的明文数据;
39、其中,明文数据中所有非强特征数据不做改变,在明文数据中保持不变。
40、进一步地,所述对新的明文数据进行加密,包括的具体步骤如下:
41、使用密码学安全的散列函数对新的明文数据进行散列操作,生成一个不可逆的散列值,将散列值结合logistics混沌加密算法,获得新密文。
42、本发明的技术方案的有益效果是:本发明通过对明文数据进行下采样处理,得到若干个采样块,根据采样块中每个数据的邻域内的数据分布得到每个数据延伸系数,提高了对强特征数据获取准确性,根据数据的延伸系数得到每个数据的所有匹配集合,完成了强特征数据的筛选,根据每个数据的匹配集合得到每个数据的特征强度,根据每个数据的特征强度得到明文数据中所有的强特征数据,再根据强特征数据对明文数据进行处理,得到新的明文数据,对新的明文数据进行加密,通过对明文数据中的强特征数据后面加盐来改变强特征数据之间的位置关系,以达到弱化明文数据中强特征的效果,提高了密文数据的安全性。
- 还没有人留言评论。精彩留言会获得点赞!