一种基于实例分割的端到端集装箱号检测识别方法
本发明涉及计算机视觉领域,具体涉及一种基于实例分割的端到端集装箱号检测识别方法。
背景技术:
1、近年来,我国社会经济的发展迅猛,国际贸易日益繁忙,货物运输行业发展日益迅速,集装箱是当今货物运输的重要运载容器,对整个交通运输体系乃至经济发展地位非凡。在集装箱的运输流转过程中,集装箱号码识别是港口集装箱管理系统中的一项关键工作,也是港口智能化升级重要环节。为满足集装箱运输管理智能化的发展,设计一种高效、精准的集装箱箱号检测识别系统具有十分重大的意义。
2、集装箱箱号就像车牌一样,每个箱体都有其唯一的编号。标准集装箱号码为11位字符,由4个英文大写字母和7个阿拉伯数字组成。对于前四个大写字母,前三个字母表示箱号所属公司的信息,第四个字母表示箱体的类别。至于后面的7个阿拉伯数字,前六位数字为每个箱体独有的注册码,最后一位数字是校验位,由前十位字符通过特定算法计算得出。箱号可以标记在集装箱的前门和侧壁,箱号类型可分为三种排列方式:水平箱号,竖直箱号和双行排列。
3、现有的集装箱箱号检测识别算法主要存在两个主要问题:
4、1)它们仅仅专注于识别一种类型的箱号。现有的大多数方法假设在简单的场景上,对一种箱号进行检测识别。并且这些检测模型以场景文本检测模型为基础,由于横排或竖排箱号内的两个间隙将11位箱号字符分成三部分,这些模型也将箱号检测为三个部分。在识别每一部分箱号后,还需要用繁杂的算法将同一箱号的三个部分重组起来。这样一来,不仅增加了算法的复杂度,还难以保证识别的准确性。
5、2)它们大多数都是两阶段算法。现有的方法基本都分为检测和识别两部分。在检测后需要对箱号进行裁剪、校正等复杂的后处理操作,往往会导致模型运行速度降低。此外,模块之间相互独立、没有约束,最终会导致误差的积累,降低模型的精度。而端到端的算法将检测和识别当成一个整体,共享视觉特征,检测损失值和识别损失值合并计算,能够达到对模型联合优化的效果。
技术实现思路
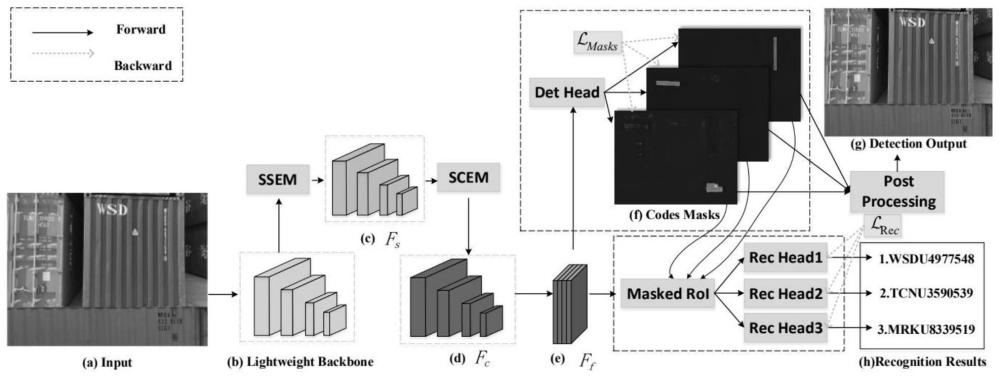
1、本发明的目的在于提供一种基于实例分割的端到端集装箱号检测识别方法,该方法将箱号检测与识别任务作为一个整体,两个任务相互约束、联合优化,减少模型误差的同时也提升了模型的效率。本发明抓住了箱号的排列、字符分布等特征,针对性地设计了检测分支和识别分支,使其能够更加适应箱号的检测和识别任务。在特征网络的设计上,本发明提出了一种由轻量级主干网络、自适应空间增强模块(ssem)、自适应通道增强模块(scem)组成的特征提取网络,以较低的计算成本提高了网络对文本特征的整合表达能力。本发明构建了集装箱号检测识别的损失函数,具体由箱号检测损失和箱号识别损失组成,总的损失函数为:在识别分支的损失函数设计上,本发明采用字符对比学习损失函数和交叉熵损失函数结合的方式,本发明提出了字符对比学习损失从字符特征向量在空间上的位置角度上,使同类型字符实例在空间上的表达更相近,而不同类型字符实例尽可能地彼此远离,从而提升识别的精度。
2、为实现上述目的,本发明的技术方案是:一种基于实例分割的端到端集装箱号检测识别方法,包括以下步骤:
3、步骤s1、获取训练所需的集装箱图片数据集,并制作数据集标签;
4、步骤s2、基于实例分割的箱号端到端集装箱号检测识别模型构建;
5、步骤s3、基于实例分割的箱号端到端集装箱号检测识别模型训练;
6、步骤s4、利于步骤s3训练的模型对集装箱号进行推理预测。
7、在本发明一实施例中,所述步骤s1具体为:
8、步骤s11、明确识别集装箱号的类型,包括横排、竖排和双行的集装箱号,集装箱图片数据集的图片内需包含集装箱号;
9、步骤s12、实地采集集装箱图片数据集图片,采集方式包括人工多角度、巡检机器人采集、港口闸机固定机位;
10、步骤s13、确定本次集装箱图片数据集中图片的集装箱号标注细节,具体为:横排、竖排的集装箱号为4个坐标,双行的集装箱号为6个坐标;
11、步骤s14、下载标注工具labelimg_windows,进行标签设置并标注图片,以xml文件形式保存。
12、在本发明一实施例中,步骤s2中模型构建采用端到端的方式,具体如下:
13、步骤s21、构建基于实例分割的箱号端到端集装箱号检测识别模型的深度神经网络模型,由轻量级主干网络、自适应空间增强模块ssem、自适应空间增强模块ssem、检测头、识别头和后处理模块六部分组成;
14、步骤s22、构建基于实例分割的箱号端到端集装箱号检测识别模型的损失函数,具体由集装箱号检测损失和集装箱号识别损失组成,总的损失函数为:其中,
15、为检测分支的损失函数,采用骰子系数损失函数dice loss构造,表示为:
16、
17、式中,i表示第i个像素;pt表示预测的文本实例;gt表示文本实例的真实标签;
18、为识别分支的损失函数,采用对比学习损失函数和交叉熵损失函数结合的方式,表示为:
19、
20、式中,λ为超参数;
21、交叉熵损失函数的计算如下:
22、
23、式中,m表示预测文本总字符数目,即文本长度;xi表示文本行中第i个转录字符;yi表示第i个转录字符标签;
24、对比学习损失函数定义如下:
25、给定一个集装箱图片数据集batch包含n幅图像,假设三种集装箱号的数量分别为nh、nv和nt;对于横排集装箱号,在一个batch内共有4×nh个字母和7×nh个数字,对于字母来说,xi是一个batch内全部横排集装箱号中字母的第i个特征向量,yi是其真值标签,其中i∈ih≡{1,2,…,4×nh};xi的正样本集合为p(i)≡{p∈i:yp=yi,p≠i},xi的负样本集合为n(i)≡{n∈i:yn≠yi,p≠i},那么横排集装箱号中字母的对比学习损失函数计算为:
26、
27、其中,h表示横排集装箱号,letters表示字母,np表示正样本的数量,τ尺度变换因子;exp代表指数函数,sim()是计算向量相似度的函数,采用余弦相似度,公式如下:
28、
29、以此类推,计算竖排和双行集装箱号字母和数字的对比学习损失函数,总的对比学习损失函数表示为:
30、
31、其中,nums表示数字,v(vertical)表示竖直箱号,t(two-lines)表示双行箱号。
32、在本发明一实施例中,所述步骤s3具体为:
33、步骤s31、初始化基于实例分割的箱号端到端集装箱号检测识别模型的网络参数;
34、步骤s32、初始学习率lr0设置为0.001,并采取动态调整的方法,前200个epoch以固定初始学习率训练,后面300epoch则遵循“poly”多学习率策略;
35、步骤s33、对输入图像进行预处理操作,将图像输入尺寸归一化为736×736,再进行图像增强;
36、步骤s34、利用集装箱号位置标签和集装箱号字符标签作为监督信息对预处理后的图像进行训练;
37、步骤s35、保存训练好的基于实例分割的箱号端到端集装箱号检测识别模型和训练好的参数存储在服务器平台。
38、在本发明一实施例中,所述步骤s4具体为:
39、步骤s41、加载基于实例分割的箱号端到端集装箱号检测识别模型和模型参数;
40、步骤s42、对输入图像进行预处理操作,以及归一化尺寸至736×736;
41、步骤s43、通过基于实例分割的箱号端到端集装箱号检测识别模型直接得到图像中所有集装箱号的坐标以及预测的集装箱号字符串;
42、步骤s44、在图中标出集装箱号框,并输出对应的具体集装箱号。
43、相较于现有技术,本发明具有以下有益效果:
44、1、本发明使用端到端方法对网络进行训练,将箱号的检测与识别任务作为一个整体,两个任务相互约束、联合优化,减少模型误差的同时也提升了模型的效率。
45、2、本发明抓住了箱号的排列、字符分布等特征,针对性地设计了检测分支和识别分支,使其能够更加适应箱号的检测和识别任务。
46、3、本发明设计了由轻量级主干网络、自适应空间增强模块(ssem)、自适应通道增强模块(scem)组成的特征提取网络,以较低的计算成本提高了网络对文本特征的整合表达能力。
47、4、本发明提出了字符对比学习损失ccl,从字符特征向量在空间上的位置角度上,使同类型字符实例在空间上的表达更相近,而不同类型字符实例尽可能地彼此远离,提升了箱号的识别精度。
- 还没有人留言评论。精彩留言会获得点赞!