一种基于知识图谱的资源推荐系统及方法与流程
本发明涉及教学资源推荐,具体是涉及一种基于知识图谱的资源推荐系统及方法。
背景技术:
1、随着移动互联网和各种教育资源平台的蓬勃发展,教育现代化的研究热点正转向为学习者提供个性化的教育资源推荐服务。智能知识推荐是在线教育中的重要组成部分,优秀的智能资源推荐系统能够根据不同用户的不同学习需求与学习能力为用户推荐个性化的教育资源,帮助用户在学习较少内容的前提下,精准推荐相关知识资料,掌握目标知识技能。目前,传统的推荐方法一般是静态的,分为基于协同过滤的推荐和基于内容的推荐,近年来还出现了基于深度学习和强化学习的推荐。尽管目前已经提出许多推荐算法,但由于在线教育用户需求的不断增长,基于关键词直接检索知识资源已经无法满足用户日常需求,不能从大量的课件资源中获得准确的信息,需要找到更好的知识推荐方案。因此,为了提高推荐结果的准确性,为了向学习者动态地推荐个性化的学习内容,探索结合学科知识图谱对在线教育学习者进行个性化的知识推荐具有重要的现实意义。
技术实现思路
1、为解决上述技术问题,提供一种基于知识图谱的资源推荐系统及方法,本技术方案解决了上述的基于关键词直接检索知识资源已经无法满足用户日常需求,不能从大量的课件资源中获得准确的信息的问题。
2、为达到以上目的,本发明采用的技术方案为:
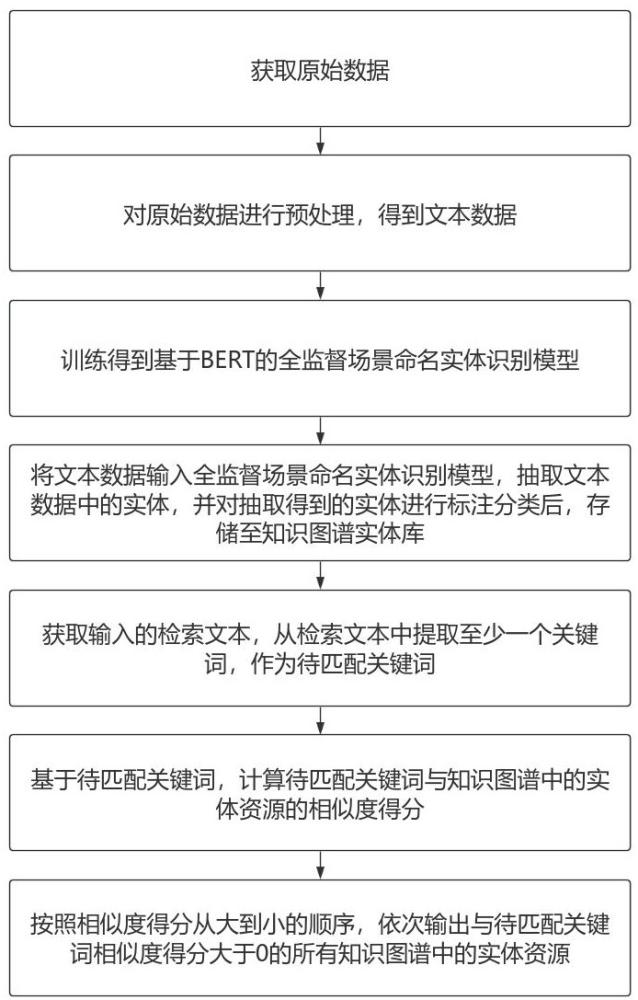
3、一种基于知识图谱的资源推荐方法,包括:
4、获取原始数据,所述原始数据至少包括课件资源、视频资源、教材资源以及学生个性化数据;
5、对原始数据进行预处理,得到文本数据;
6、训练得到基于bert的全监督场景命名实体识别模型;
7、将文本数据输入全监督场景命名实体识别模型,抽取文本数据中的实体,并对抽取得到的实体进行标注分类后,存储至知识图谱实体库;
8、获取输入的检索文本,从检索文本中提取至少一个关键词,作为待匹配关键词;
9、基于待匹配关键词,计算待匹配关键词与知识图谱中的实体资源的相似度得分;
10、按照相似度得分从大到小的顺序,依次输出与待匹配关键词相似度得分大于0的所有知识图谱中的实体资源。
11、优选的,所述对原始数据进行预处理,得到文本数据具体包括:
12、对原始数据进行分类,并将所有原始数据采用代码批量另存为pdf格式,得到pdf数据;
13、统一使用python中的pdfminer解析器对于pdf数据进行解析,提取出其中的文字信息到txt文件;
14、对txt文件中的乱码文字进行清理,得到txt格式的文本数据。
15、优选的,所述训练得到基于bert的全监督场景命名实体识别模型具体包括:
16、从文本数据提取若干样本数据;
17、采用人工的方式对样本数据中的实体进行识别和标注,得到训练数据;
18、将训练数据按照8:1:1的方式划分为训练集、测试集和验证集;
19、基于训练集、测试集和验证集,于实验室服务器上训练基于bert的全监督场景命名实体识别模型。
20、优选的,所述将文本数据输入全监督场景命名实体识别模型,抽取文本数据中的实体,并对抽取得到的实体进行标注分类后,存储至知识图谱实体库具体包括:
21、通过全监督场景命名实体识别模型,于文本数据中抽取头实体,关系,尾实体,得到知识图谱三元组;
22、利用neo4j图数据库对知识图谱三元组进行知识存储。
23、优选的,所述基于待匹配关键词,计算待匹配关键词与知识图谱中的实体资源的相似度得分具体包括:
24、分别计算待匹配关键词与知识图谱中的实体资源的标签种类占比、标签数量占比和资源得分,所述标签种类占比、标签数量占比和资源得分的取值范围均为[0,1];
25、分别设置标签种类占比权重、标签数量占比权重和资源得分权重;
26、按照标签种类占比权重、标签数量占比权重和资源得分权重,对标签种类占比、标签数量占比和资源得分进行加权求和,得到待匹配关键词与知识图谱中的实体资源的相似度。
27、优选的,所述标签种类占比的计算方式为:
28、将知识图谱中的实体资源的相同标签划分为同一标签种类;
29、确定知识图谱中的实体资源的所有标签种类,记为资源标签种类;
30、确定每个待匹配关键词对应的标签种类,记为待匹配关键词标签种类;
31、通过种类占比公式计算待匹配关键词与知识图谱中的实体资源的标签种类占比;
32、所述种类占比公式具体为:
33、
34、种类占比公式中,为标签种类占比,为待匹配关键词标签种类总数量,为资源标签种类总数量;
35、所述标签数量占比的计算方式为:
36、确定每个资源标签种类下对应的标签数量;
37、通过数量占比公式计算待匹配关键词与知识图谱中的实体资源的标签数量占比;
38、所述数量占比公式具体为:
39、
40、种类占比公式中,为标签数量占比,为第i个待匹配关键词标签种类下对应的标签数量,为第j个资源标签种类下对应的标签数量;
41、所述资源得分的计算方式为:
42、确定资源的总字符长度;
43、确定每个待匹配关键词标签种类对应的标签字符长度;
44、通过资源得分公式计算待匹配关键词与知识图谱中的实体资源的资源得分;
45、所述资源得分公式具体为:
46、
47、种类占比公式中,为资源得分,为第i个待匹配关键词标签种类下对应的标签字符长度,为资源的总字符长度。
48、进一步的,提出一种基于知识图谱的资源推荐系统,用于实现如上述的基于知识图谱的资源推荐方法,包括:
49、数据采集模块,所述数据采集模块用于获取原始数据,并对原始数据进行预处理,得到文本数据;
50、模型训练模块,所述模型训练模块与所述数据采集模块电性连接,所述模型训练模块用于训练得到基于bert的全监督场景命名实体识别模型;
51、知识图谱构建模块,所述知识图谱构建模块与所述数据采集模块和所述模型训练模块电性连接,所述知识图谱构建模块用于将文本数据输入全监督场景命名实体识别模型,抽取文本数据中的实体,并对抽取得到的实体进行标注分类后,存储至知识图谱实体库;
52、检索推荐模块,所述检索推荐模块与所述知识图谱构建模块电性连接,所述检索推荐模块用于获取输入的检索文本,从检索文本中提取至少一个关键词,作为待匹配关键词,并基于待匹配关键词,计算待匹配关键词与知识图谱中的实体资源的相似度得分,同时按照相似度得分从大到小的顺序,依次输出与待匹配关键词相似度得分大于0的所有知识图谱中的实体资源。
53、可选的,所述模型训练模块包括:
54、数据集划分单元,所述数据集划分单元用于将训练数据按照8:1:1的方式随机划分为训练集、测试集和验证集;
55、训练单元,所述训练单元用于基于训练集、测试集和验证集,于实验室服务器上训练基于bert的全监督场景命名实体识别模型。
56、可选的,所述检索推荐模块包括:
57、关键词提取单元,所述关键词提取单元用于获取输入的检索文本,从检索文本中提取至少一个关键词,作为待匹配关键词;
58、权重赋值单元,所述权重赋值单元用于设置标签种类占比权重、标签数量占比权重和资源得分权重;
59、相似度计算单元,所述相似度计算单元用于分别计算待匹配关键词与知识图谱中的实体资源的标签种类占比、标签数量占比和资源得分,并按照标签种类占比权重、标签数量占比权重和资源得分权重,对标签种类占比、标签数量占比和资源得分进行加权求和,得到待匹配关键词与知识图谱中的实体资源的相似度;
60、资源输出单元,所述资源输出单元用于按照相似度得分从大到小的顺序,依次输出与待匹配关键词相似度得分大于0的所有知识图谱中的实体资源。
61、与现有技术相比,本发明的有益效果在于:
62、本发明提出了一种基于知识图谱的资源推荐系统,基于非结构化的课件知识点和课件内容,通过对采集的多源多领域的原始数据进行信息抽取,包括命名实体识别,关系抽取等步骤构建学科知识图谱。利用学科知识图谱可以把知识点间的关系通过可视化的形式进行展示,天然的用来帮助学生构建知识体系,查阅知识要点,发现知识点之间的关联。结合知识图谱,可以将输入的关键词在知识图谱中搜索一遍,找到直接相关的实体。然后再将这些实体作为关键词标签,进行基于词义的知识资源推荐。
- 还没有人留言评论。精彩留言会获得点赞!