一种基于无人机视觉感知的定点降落方法
本发明属于无人机视觉与图像处理领域,涉及一种基于无人机视觉感知的定点降落方法。
背景技术:
1、随着无人机(unmanned aerial vehicle,uav)的发展,搭载了视觉传感器的垂直起降(vertical takeoff and landing,vtol)无人机有着广泛的应用,如救援搜索、环境监测、交通流监控、物资运输等。这些应用场景无一不需要无人机具备精准定位的能力,传统的无人机定点降落方法通常依赖于全球定位系统(gps),但不可避免的是,无人机在户外进行作业时,会出现gps信号弱或gps信号缺失的情况。在gps信号失效的情况下,无人机的定位则需要依赖其他手段来实现精准定位。
2、随着深度学习和机器视觉的不断发展,目标检测算法作为视觉与图像处理领域中的关键技术,使得无人机实现自主定点精准降落得到了可能。无人机在动态场景下实现自主定点精准降落涉及到图像处理、通信传输、无人机控制以及机器学习等研究领域,其中通过对降落目标实现稳定、快速的检测,从而完成降落目标与无人机之间相对位置的计算和无人机控制。在智能交通系统(intelligent transportation system,its)中,巡逻无人机执行设定任务时,一方面可根据设定程序进行巡检任务;另一方面,当完成既定任务或需要续航时,利用视觉传感器获取降落平台的相对位置信息,从而实现自主精准降落至静止或移动的目标上实现回收或电能补给,可大幅度提高无人机的工作效率。
3、然而,经典的目标检测算法在处理多尺度变化和小目标检测时可能表现不佳,并且一些针对小目标检测的算法通常会引入大量的网络参数,影响检测速度和实时性。
技术实现思路
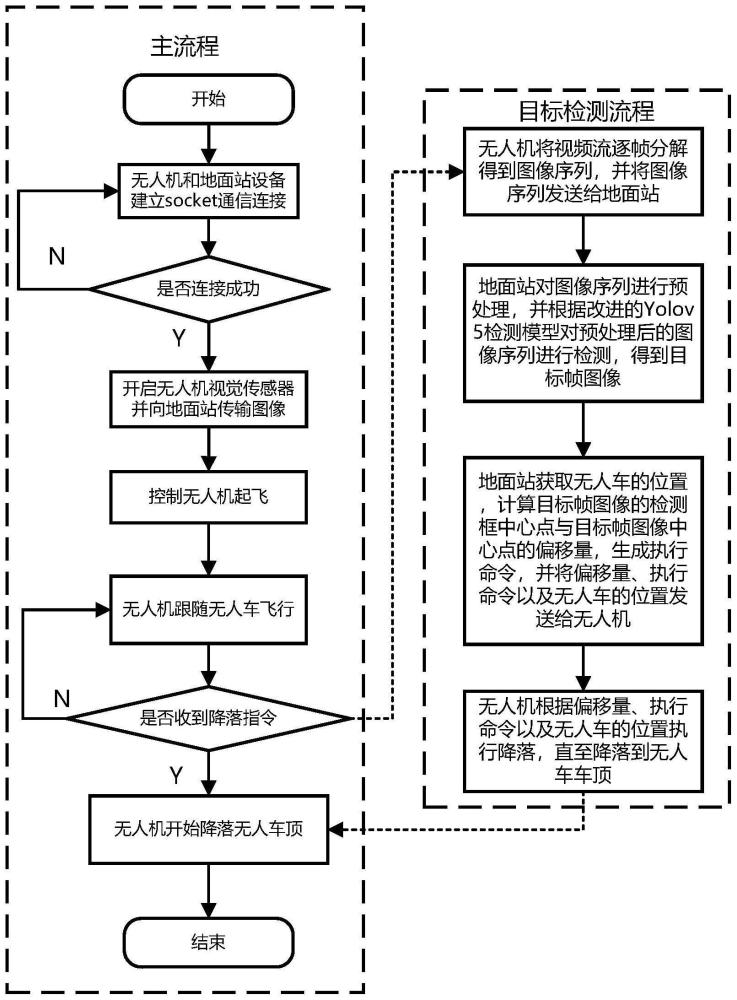
1、为解决以上现有问题,本发明提出了一种基于无人机视觉感知的定点降落方法,包括:
2、s1、无人机采集视频流,将视频流逐帧分解,得到图像序列,并将图像序列发送给地面站;
3、s2、地面站对图像序列进行预处理,并根据改进的yolov5检测模型对预处理后的图像序列进行检测,得到目标帧图像;所述目标帧图像包括降落标志、降落标志的类别信息以及检测框中心点的位置信息;
4、s3、地面站获取无人车的位置,计算目标帧图像的检测框中心点与目标帧图像中心点的偏移量,生成执行命令,并将偏移量、执行命令以及无人车的位置发送给无人机;
5、s4、无人机根据偏移量、执行命令以及无人车的位置执行降落,直至降落到无人车车顶。
6、改进的yolov5检测模型包括:input层、改进的backbone网络、改进的neck网络以及改进的head网络;改进的backbone网络对原始yolov5网络的改进包括:在原始yolov5网络的backbone网络的每个c3模块后添加一个cbam模块,将原始yolov5网络的backbone网络的第一个卷积模块替换为focus模块;其中,cbam模块为卷积注意力模块。
7、改进的neck网络对原始yolov5网络的改进包括:在原始yolov5网络的neck网络中引入bifpn;其中,bifpn为双向特征金字塔网络。
8、原始yolov5网络的neck网络包括自底向上的特征融合阶段a1和自顶向下的特征融合阶段a2,自底向上的特征融合阶段a1包括:卷积模块、upsample模块、concat模块、c3模块;自顶向下的特征融合阶段a2包括:卷积模块、concat模块、c3模块;
9、在原始yolov5网络的neck网络中引入bifpn包括:a1阶段的concat模块将a1阶段的upsample模块的输出结果f1与backbone网络中cbam模块输出的与f1同尺寸的输出结果进行融合;a2阶段的最后一个concat模块将a2阶段的卷积模块的输出结果f2和a1阶段的卷积模块输出的与f2同尺寸的输出结果进行融合,a2阶段的其余concat模块将a2阶段的的卷积模块的输出结果f3、backbone网络中cbam模块输出的与f3同尺寸的输出结果以及a1阶段的卷积模块输出的与f3同尺寸的输出结果进行融合;其中,upsample为上采样。
10、改进的neck网络对原始yolov5网络的改进还包括:将自底向上的特征融合阶段a1的卷积模块替换为dwconv模块;dwconv模块包括:dwconv层、bn层、silu激活层;其中,dwconv为深度可分离卷积。
11、改进的yolov5检测模型对原始yolov5网络的改进还包括:在原始yolov5网络的head网络中添加一个小目标检测层p2,在原始yolov5网络的neck网络中添加一个上采样特征融合模块,所述上采样特征融合模块包括:dwconv模块、upsample模块、concat模块、c3模块以及cbam模块;上采样特征融合模块将a1阶段中最后一个c3模块输出的特征图和backbone网络的第一个cbam模块输出的特征图进行融合,得到160×160尺寸的输出特征图,并将输出特征图分别输入a2阶段的第一个卷积模块和小目标检测层p2;其中,a1为自底向上的特征融合,a2为自顶向下的特征融合,upsample为上采样,dwconv为深度可分离卷积。
12、改进的yolov5检测模型的训练过程包括:
13、s21、构建数据集,将数据集输入input层进行预处理,得到新数据集和锚框;
14、s22、将新数据集中的图片输入改进的backbone网络提取特征,得到不同尺度的特征图;
15、s23、将不同尺度的特征图输入改进的neck网络进行特征融合,得到不同尺度的特征融合图;
16、s24、将不同尺度的特征融合图输入改进的head网络进行预测,得到多个预测结果;
17、s25、根据预测结果和锚框计算损失函数值,根据损失函数值更新模型参数,当达到预先设定的最大迭代次数时,得到训练好的改进的yolov5检测模型。
18、构建数据集包括:根据无人机底端部署的摄像头模组采集视频流,将视频流逐帧分解,得到图像序列;按照voc2017数据集的格式对图像序列中的图像进行处理;使用标注工具对处理后的图像中的降落标志进行标注,得到每张图像的标注文件;将图像与标注文件进行组合,得到数据集。
19、input层对数据集进行预处理包括:利用mosaic数据增强方法对数据集进行数据增强,得到新数据集;通过k-means++算法对新数据集的标注文件进行聚类,得到锚框。
20、改进的yolov5检测模型的损失函数包括:分类损失函数lclass、矩形框损失函数lciou以及置信度损失函数lobject。
21、有益效果:
22、1、本发明通过在每个c3模块后引入cbam注意力机制,由此提高网络的特征提取能力;对于低层级的cbam模块,增强了低级特征的表达能力,提高边界框定位的准确性;对于中层级的cbam模块,可以自适应地学习中层特征的通道关联性,将更多的注意力放在具有高语义重要性的通道上,增强语义信息的表达能力和目标检测的准确性;对于高层级的cbam模块,则加强了全局上下文信息和目标的语义一致性;2、本发明考虑到在neck网络增加上采样和c3操作后,小目标在特征图中信息量较少,其细节和上下文信息较模糊,因此添加的cbam可以通过通道注意力和空间注意力机制增强小目标特征的表达能力和空间定位准确性,同时缓解小目标与背景之间的比例失衡问题;3、本发明在neck网络中将卷积操作替换为dwconv操作,使输入网络中的图片能在不更改输出特征图大小的情况下,减少参数总数和计算复杂度,更好地保留空间信息,避免信息的模糊化,提升了网络检测的实时性;4、本发明增添了小目标检测层p2,使得网络可以在四种不同大小尺度范围对降落标志进行精准检测,以助于当无人机在高空搜索目标或进行降落的过程中,所检测跟踪到的降落标志尺度变化过大,避免目标丢失的情况;5、本发明通过在neck网络中采用bifpn特征金字塔网络结构,增强了模型在多个尺度上的定位能力;bifpn增加了残差连接操作,移除没有进行融合的单边输入节点,减少了计算量的同时平衡了不同尺度的特征信息,加强了网络特征融合的能力。
- 还没有人留言评论。精彩留言会获得点赞!