一种基于GVG的代码注释生成方法
本发明涉及代码注释生成,具体涉及一种基于gvg的代码注释生成方法。
背景技术:
1、在软件工程领域,需要软件开发人员快速、准确地理解现有的代码,从而高效地去完成系统或软件的功能变更和工程维护等任务。高质量的代码注释以自然语言的形式表示了源代码的整体思路和关键细节,是帮助开发人员快速理解源代码的关键。
2、但是,人工编写代码注释耗费时间,且书写效率不高、编写注释的质量参差不齐、正确性难以保证。因此,代码注释自动生成技术的重要性得以体现。代码注释自动生成技术是计算机科学和自然语言处理(nlp)的交叉应用,结合了代码分析、自然语言理解和文本生成的技术,以提高代码的可读性、可理解性和维护性,现如今代码注释自动生成技术已成为程序理解领域的研究热点之一。
3、现有的自动生成代码注释的方法有:基于模板的生成方法、基于信息检索的生成方法和基于深度学习的生成方法。基于模板的生成方法存在模板匹配问题以及语义捕捉不足等问题,基于信息检索的生成方法存在单词汇受限以及上下文理解不足的问题,而当今普遍使用的深度学习方法,在信息处理时大多采用抽象语法树ast语法树进行序列化处理,这造成了代码结构的缺失,进而影响了生成注释的质量,而有研究提出的图神经网络处理方法,忽略了代码信息的上下文时序,引起了程序顺序性所带来的误差。因此,如何解决代码的语法、语义及时序所引发的问题,成为了自动代码注释生成领域不可避免的核心问题。同时,现主流的代码注释生成方法大多专注于某一种编程语言,因此,如何设计出一种方案,能够对多种编程语言进行注释,是本领域技术人员需解决的技术问题。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明提供一种基于gvg的代码注释生成方法。能够识别代码类别,对多种编程语言进行注释。
2、为实现上述效果,本发明的技术方案如下:
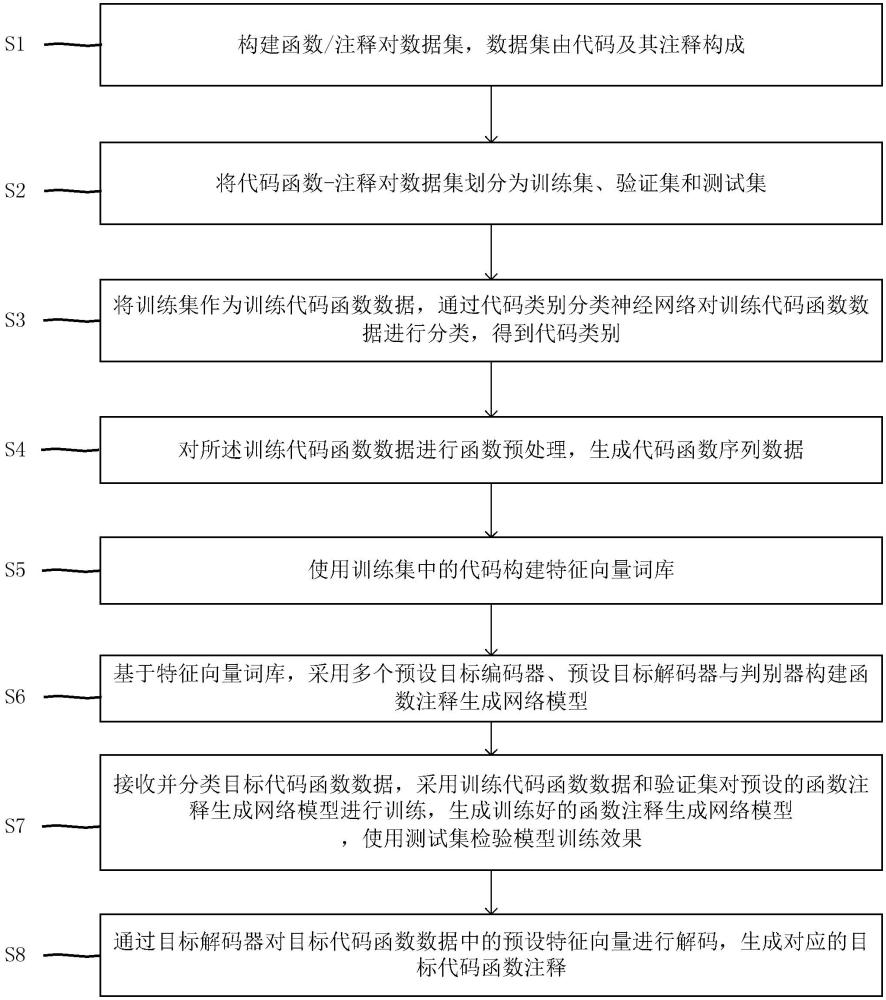
3、第一方面,本发明提供一种基于gvg的代码注释生成方法,包括以下步骤:
4、步骤1:构建函数/注释对数据集,数据集由代码及其注释构成;
5、步骤2:将代码函数-注释对数据集划分为训练集、验证集和测试集;
6、步骤3:将训练集作为训练代码函数数据,通过代码类别分类神经网络对训练代码函数数据进行分类,得到代码类别;
7、步骤4:对所述训练代码函数数据进行函数预处理,生成代码函数序列数据;
8、所述代码函数序列数据包括原始单词序列、原始代码标识符序列、标点符号序列,原始代码标识符包括驼峰标识符和蛇形标识符;
9、步骤5:使用训练集中的代码构建特征向量词库;具体包括:
10、步骤5.1:通过按行读取的方式获取第一文件中的代码数据,对每一行代码使用空格进行切割,得到代码单词组列表;
11、步骤5.2:为代码构建代码索引词典,将代码单词组列表中的单词按顺序以“单词-位置”的形式保存到代码索引词典中;
12、步骤5.3:构建特征向量词库,使用词嵌入的方式将代码索引词典中的单词进行从单词到特征向量的映射;
13、步骤6:基于特征向量词库,采用多个预设目标编码器、预设目标解码器与判别器构建函数注释生成网络模型;
14、步骤7:接收并分类目标代码函数数据,采用训练代码函数数据和验证集对预设的函数注释生成网络模型进行训练,生成训练好的函数注释生成网络模型,使用测试集检验模型训练效果;
15、步骤8:通过目标解码器对目标代码函数数据中的预设特征向量进行解码,生成对应的目标代码函数注释。
16、进一步的,步骤4对所述训练代码函数数据进行函数预处理,包括:
17、步骤4.1:将构建数据集时的代码和注释分别作为原始代码和原始注释,对原始代码进行分割以及清洗,生成原始单词序列;
18、步骤4.2:通过预设语法树解析器将所述训练代码函数数据转换为ast语法树,对ast语法树进行位置编码;
19、将位置编码融入到对应的ast语法树中作为ast语法树中节点的数据之一;使用正弦函数和余弦函数对ast语法进行位置编码,具体如下:
20、
21、
22、其中,pe表示位置编码特征向量,pos表示代码元素在输入序列中位置;表示嵌入特征向量的维度;
23、步骤4.3: 根据ast语法树提取代码的变量关系,将代码的变量关系构建为数据流图dfg。
24、进一步的,步骤4.1对原始代码进行分割以及清洗包括:
25、步骤4.1.1:将驼峰标识符按驼峰命名规则进行切割,得到一组分割单词,记为驼峰单词;
26、步骤4.1.2:将蛇形标识符按蛇形命名规则进行切割,得到一组分割单词,记为蛇形单词;
27、步骤4.1.3:将单词与单词、单词与标点符号、标点符号与标点符号之间用空格进行分割,使单词与标点符号成为独立的个体;
28、步骤4.1.4:删除代码中的转义字符;
29、步骤4.1.5:将删除转义字符后的代码按行的方式保存到预设的第一文件中;
30、步骤4.1.6:记录单词的处理痕迹,若单词由驼峰标识符或由蛇形标识符切割所得,则记为1,否则记为0;
31、步骤4.1.7:将代码单词的痕迹记录按行的方式保存到预设的第二文件中。
32、进一步的,步骤4.4结合ast语法树与数据流图dfg构建数据流语法图dfsg;具体为:
33、根据数据流图dfg中节点之间数据流的信息,向数据流添加对应的边,构建数据流语法图dfsg;即:
34、设定ast语法树存在节点a和节点b,若在数据流图dfg中存在节点a到节点b或者节点b到节点a的数据流,则为数据流添加目标连接边,目标连接边的指向取决于数据流图dfg中节点的指向。
35、进一步的,所述代码类别分类神经网络采用循环递归网络rnn,循环递归网络rnn的训练过程为:
36、为原始代码标记对应的编程语言种类标签;
37、将原始代码进行代码分单词与清洗后转化为单词序列,代码分单词与清洗包括分单词操作、去除标点符号;
38、训练循环递归网络rnn:
39、使用词嵌入的方法将代码分单词与清洗后的代码转换为特征向量;
40、使用循环递归网络rnn作为训练模型,利用特征向量及其对应的标签对循环递归网络rnn进行训练,其中,将交叉熵函数作为循环递归网络rnn的损失函数,交叉熵函数如下:
41、
42、其中,m表示编程语言的类别个数;表示符号函数,取0或1,符号函数中,若数据集中样本i的真实类别等于c,取值1,否则取值0;表示样本i属于类别c的预测概率。
43、进一步的,步骤6包括:
44、步骤6.1:
45、使用节点嵌入技术将数据流语法图dfsg中的节点转换为节点嵌入特征向量;
46、步骤6.2:使用边嵌入技术将数据流语法图dfsg中的边转换为边嵌入特征向量;
47、步骤6.3:构建图结构数据,将点嵌入特征向量和边嵌入特征向量通过维度拼接进行结合,得到图结构数据特征向量;
48、步骤6.4:使用图结构数据特征向量训练第一编码器,输出特征向量。
49、进一步的,步骤7包括:
50、步骤7.1:从特征向量提取均值特征向量和标准差特征向量;具体包括:
51、构建第一全连接层、第二全连接层作为隐层φ和隐层ψ,通过隐层φ和隐层ψ提取特征向量的特征信息;将第一全连接层的权重矩阵表示为φw={φ1, φ2, … φn},将第二全连接层的权重矩阵表示为ψw={ψ1, ψ2, … ψn};每个隐层的输出通过预设的激活函数relu进行特征向量的非线性变换;
52、将特征向量输入到隐层φ输出后再通过激活函数relu进行激活获得特征向量vφ,将特征向量vφ输入到隐层ψ输出后再通过激活函数relu进行激活后获得特征向量vψ;
53、构建第三全连接层,权重矩阵表示为muw={ mu1, mu2, …,mun},用于从特征向量提取均值特征向量;
54、构建第四全连接层,权重矩阵表示为lvw= { lv1, lv2, …, lvn},用于提取标准差特征向量;将特征向量vψ分别输入到第三全连接层和第四全连接层,分别得到均值特征向量和标准差特征向量;
55、步骤7.2:使用均值特征向量和标准差特征向量进行重参化,得到特征向量;即,
56、计算标准差特征向量的标准差std,标准差std表示为:
57、
58、从高斯分布上随机采样噪声特征向量,基于均值特征向量、噪声特征向量,构建特征向量:
59、。
60、进一步的,所述采用训练代码函数数据和验证集对预设的函数注释生成网络模型进行训练,生成训练好的函数注释生成网络模型,包括:
61、将训练代码函数数据和验证集输入所述函数注释生成网络模型,生成对应的训练代码函数注释;
62、基于预设的损失函数,计算所述训练代码函数注释与关联的标准代码函数注释之间的多个轮次的平均损失值;
63、计算每一轮次的所述平均损失值与前一轮次的所述平均损失值之差,生成多个目标损失值;
64、若所有所述目标损失值的绝对值均小于预设的标准阈值时,停止训练,生成训练好的函数注释生成网络模型。
65、进一步的,步骤8所述通过目标解码器对目标代码函数数据中的预设特征向量进行解码,包括:
66、使用解码器对特征向量的编码特征进行解码,输出概率分布,将最高概率对应的单词作为输出;若概率最高的单词不是未知单词,则输出最高概率对应的单词;否则,执行以下步骤:
67、步骤9.1:将特征向量对应的原始代码进行分割以及清洗,得到目标代码函数序列数据;使用空格对目标代码函数序列数据进行切割,得到目标代码单词组列表;将目标代码词组列表中的单词按顺序以“单词-位置”的形式保存到目标代码索引词典中;使用词嵌入的方式将目标代码索引词典的单词进行从单词到特征向量的映射,得到目标特征向量词库;
68、步骤9.2:在目标特征向量词库中寻找目标替代词来代替未知单词,如果目标特征向量词库中的所有的向量与向量的编码特征的相似度小于设定阈值,则转而在特征向量词库中寻找目标替代词来代替未知单词。
69、步骤9.3:目标代码解码出注释后,清空目标特征向量词库。
70、进一步的,述判别器用于对特征向量打分,具体如下:
71、将原始注释通过词嵌入的方式编码成特征向量;
72、将特征向量与特征向量输入判别器中进行训练并打分,对特征向量打出高分,对特征向量打出低分;
73、对判别器使用bce损失函数进行训练,bce损失函数表示为:
74、
75、其中,是第i个样本的二元标签值;p()是第i个样本的打分结果,表示判别器对第i个样本的特征向量打出的评分。
76、与现有技术相比,本发明技术方案的有益效果是:
77、通过代码类别分类神经网络对训练代码函数数据进行分类能够识别代码类别,对多种编程语言进行注释。
78、在本发明中通过使用多个预设目标编码器使目标代码的注释生成更丰富;对不同的编程语言的代码生成相应注释;
79、通过构建特征向量词库,供解码器在解码输出时使用,更好地处理oov问题。
- 还没有人留言评论。精彩留言会获得点赞!