基于多粒度的特征对比和融合框架的多模态情感分析方法
本发明属于情感分析,尤其涉及基于多粒度的特征对比和融合框架的多模态情感分析方法。
背景技术:
1、随着短视频平台(如抖音、微博)的普及,使得视频这种包含多种模态的形式成为主要的信息载体,这种多模态数据通常由三个通道组成:转换语言(文本)、视觉(图像)和声学(语音)数据。文本模态包含了演讲者口语的语义、视觉模态提取说话者的面部特征(例如,头部方向、面部表情和姿势)、音频模态则反映了话语的相位(例如,音高、带宽和强度)。许多研究者发现只从单一的文本、语音或视觉模态分析视频往往会导致丢失过多的重要信息,从而产生歧义,因此多模态数据特征的完整性给内容的推荐和分类带来了新的挑战,例如情感分析。
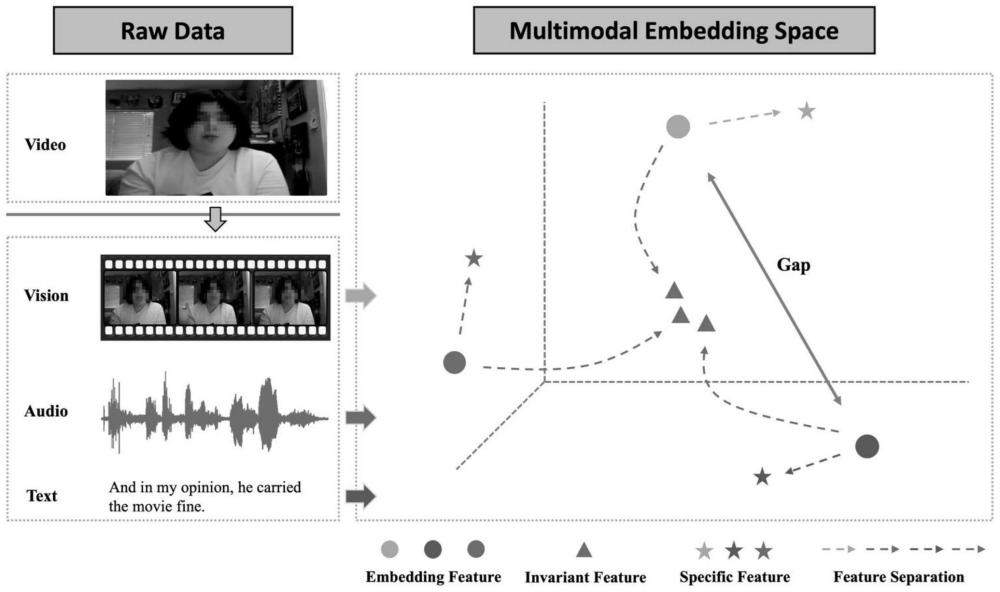
2、对于多模态情感分析任务(msa),通常把原始视频划分成片段作为输入数据。如图1所示,首先获取视频片段(video),然后通过预处理工具获得模型所需要的多模态输入,即视觉(vision)、语音(audio)和文本(text)。msa的目标是从所有输入模态中提取特征,再利用融合技术将这些模态特征组合起来,输出情感极性。现有的大多数工作,都没有或者不完全考虑了多模态数据中跨模态的不变性特征以及模态独立性特征。如图1所示,原始多模态特征(embedding feature)在嵌入空间中会存在较大距离(gap),所以许多之前的工作直接进行融合会导致噪声传播。我们要解决的问题就是如何充分将模态的嵌入特征进行有效分离,即获得不变性特征(invariant feature)以及独立性特征(specific feature),从而噪声传播问题。这也是部分之前的工作没有关注或没有彻底解决的问题。
3、先前关于情感分析的工作主要集中在利用文本或视觉模态进行预测,但是最近工作逐渐倾向使用多模态数据,如面部表情(v),声学音调(a),和口语(t)。在msa任务中,多模态融合一直是最关键的步骤,之前的大部分工作都集中在早期或晚期融合。早期融合是指在单模态编码之前将多个模态的输入拼接到单个特征中,例如williams等人(2018)连接初始化输出特征,然后使用lstm来捕获特征中的时间序列表示。chen等人提出了sentimentalwords aware fusion network(swafn)来计算文本和其他模态之间的相互关系。晚期融合则通常使用独立模块学习单模态表示,并在推理后期将其融合。例如zadeh等人(2017)提出了一种张量融合网络(tfn),该网络首先用对应子模块对所有模态进行编码,然后用三重笛卡尔乘积对单模态、双模态和三模态的相互作用进行建模。之后zadeh等人又提出了一种由长短期记忆网络(lstm)组成的记忆融合网络(mfn),以学习三个模态(文本、视频和音频)的特定视图和跨视图交互。此外,akhtaret等人提出了一个深度多任务学习框架,以在多模态数据下联合学习情绪的极性和强度。delbrouck设计了一种基于transformer的联合编码器(tbje),该编码器以声学和文本特征作为输入,对两种模态进行联合编码。rahman等人直接研究了bert,设计了功能门来控制单模态的数据流。最近的工作中,大家又提出了许多新的学习框架。例如hazarika et al.(2020)试图重构表示空间中的模态特征和损失,以有效地捕捉不同模态之间的共性并缩小它们的差距。yu et al.(2021a)和maiet al.(2020)也探索了多任务联合学习,通过模态之间的转换来关注模态的一致性和差异性。tsai等人(2019a)和luo等人(2021)分别利用跨模态和多尺度模态表示来实现模态对齐,并试图计算成对模态之间的跨模态注意力。han et al.(2021b)提出了一种新的框架,通过最大化多模态融合结果和单模态输入特征之间的互信息来对输入数据进行降噪。rahman等人(2020)提出了一种多模态自适应门(mag),并重新对预训练语言模型进行微调,以便其能够适应多模态情感分析任务。然而,大部分先前的工作没有考虑表示单模态的多粒度信息,从而丢失对应的关键因素。其次,一些工作平等对待三种模态的贡献,并设计复杂的融合模块以获得更好的结果,会导致模型复杂度高且性能下降的问题。
4、对比学习是最近广泛使用的一种学习方法。cl旨在学习有效的表现,通过对比正样本对和负样本对来学习数据的表征,使正样本对接近,而负样本对远离。cl现有工作可分为两类:自监督对比学习和监督对比学习,它们之间的区别在于标签信息是否用于形成正/负样本对。hassaniand khasahmadi(2020)通过对比图形的不同结构视图所获得的编码来学习节点和图形级别的表示,并在各种图形分类基准上达到了最优的表现。chen等人(2020)提出了一种自监督对比学习框架simclr,通过对同一图像的增强数据之间的对比来获得视觉表示。在计算机视觉中使用cl取得了良好的效果后,cl又被应用于各种多模态任务。例如akbari等人(2021)使用多模态对比学习来训练视频-音频文本转换器(vatt),用于视频-文本和视频-音频对的对齐,从而在各种计算机视觉任务(例如,音频分类和视频动作识别)上达到最先进的水平。khosla等人(2020)将自监督对比学习扩展到监督环境,即对比不同类别的样本,他们还表示,对于超参数,监督设置更稳定。hycon(mai et al.,2021)的工作介绍了msa的对比学习方法,在进行样本间对比学习时,它根据数据标签随机对正样例和负样例配对进行采样。但是之前大部分的工作都通过只对比样本自身来寻找正对或者对比其余样本寻找负对,这会使得模型学习到的知识更加片面化。
5、在以往的解决方案中,最基本的一个是在执行预测之前,将每个模态的低维特征直接拼接用于预测。其余较基本的方法是选择使用外积、递归神经网络(rnn)或基于注意力机制的模型来对多模态交互进行建模。而最近的研究通常使用学习统一表示的方法为多模态交互进行建模,可划分为两类:通过损失反向传播或特征空间中的几何操作。前者基于任务损失的反向传播梯度来调整参数、重建损失或辅助任务损失。后者通过矩阵分解或欧几里得测度优化对单模态表示的空间方向进行了加法校正。以往的研究表明,同一数据段中的不同模态通常是互补的,它们都会为对方的语义消歧提供额外的辅助信息,因为情感线索通常分布在各个模态中,所以以上方案大多采用三元对称架构,即每种模态在融合时都会经历相同过程。然而,正如最近几项研究指出,与下游任务相关的信息在不同模态之间的分布并不均匀,没有考虑到这三种模态相对重要性差异的模型架构不会做到完整的融合多模态相似表示,从而降低模型的性能。对于情感分析来说,文本模态应当为模态中的核心位置,因为文本包含最基本的语义信息,而语音模态和视觉模态则会辅助文本模态,例如音调上升的人更有可能表达积极的情绪,愤怒的表情更有可能代表消极情绪。对于跨模态中不变特征的提取和利用,以往的工作已经意识到其重要性,有研究指出,这三种模态通常都具有独特的统计特性,使它们在某些特征又相互独立,比如某一模态保持不变的情况下,其余模态可能会表现出巨大的变化。尽管以往的研究获得了优异的结果,但是大多注重于寻找模态间的融合技术或提升数据提取质量,而并没有将两者很好的结合,会丢失较多的重要信息。所以在复杂的多模态场景下,实现有效区分模态的独立性特征与不变性特征,同时完整融合多模态相似表示仍是一项重大挑战。
技术实现思路
1、本发明的目的在于提出基于多粒度的特征对比和融合框架的多模态情感分析方法,不仅可以有效捕获跨模态不变特征来识别情感分类,还可以利用模态特定特征预测情感强度。
2、为实现上述目的,本发明提供了基于多粒度的特征对比和融合框架的多模态情感分析方法,包括:
3、提取原始视频的低纬度多模态特征数据;其中,所述低纬度多模态特征数据包括:文本独立特征数据、视觉独立特征数据和语音独立特征数据;
4、将所述低纬度多模态特征数据,输入单模态特征提取模块,进行特征提取,获取单模态独立特征数据;
5、将所述单模态独立特征数据,输入多模态融合模块,进行数据融合,获取跨模态融合数据;
6、将所述跨模态融合数据,输入对比学习模块,使用msa回归主任务和对比学习子任务对分类输出模块进行训练;
7、基于训练后的所述分类输出模块,获取多模态情感预测结果。
8、可选地,获取所述单模态独立特征数据包括:
9、基于预训练语言模型bert,对原始视频中的低纬度文本模态特征数据进行特征提取,获取所述文本独立特征数据;
10、基于的时间序列编码器和语意编码器,分别对原始视频中的低纬度视觉模态特征数据和低纬度语音模态特征数据进行特征提取,获取所述视觉独立特征数据和语音独立特征数据。
11、可选地,所述文本独立特征数据为:
12、
13、
14、其中,ht是指首先使用bert提取的整体文本特征,为bert需要的参数,为[cls]-token的嵌入特征,xt为初始输入的文本序列,为提取出文本特征的向量矩阵,维度为tt×dt,ot为文本独立特征数据,为文本独立特征所属的向量矩阵;
15、所述视觉独立特征数据为:
16、
17、
18、其中,为视觉模态的整体上下文序列特征,hv为视觉模态的token上下文嵌入特征,为提取图像序列特征的bibert需要的参数,为视觉模态的语义特征,xv为初始输入的图像序列,为整体视觉序列特征所属矩阵,为每一帧的视觉特征组成的序列的所属矩阵,为视觉uni_transformer需要的参数;
19、所述语音独立特征数据为:
20、
21、
22、其中,为视觉模态的整体上下文序列特征,ha为视觉模态的token上下文嵌入特征,为提取音频序列特征的bibert需要的参数,为视觉模态的语义特征,xa为初始输入的图像序列,为音频uni_transformer需要的参数。
23、可选地,所述多模态融合模块中包括并行执行的transformer,基于所述并行执行的transformer,对所述单模态独立特征数据进行融合获取所述跨模态融合数据;
24、基于所述并行执行的transformer,对所述单模态独立特征数据进行融合的方法包括:
25、
26、
27、其中,为融合模块第j层的以m模态为主,文本模态为辅的输出,同样是第j+1层的输入,为以m模态为主,文本模态为辅的第j层融合模块的输入,为以文本模态为主,m模态为辅的第j层融合模块的输入,为输出特征所属的向量矩阵,为融合模块第j层的以文本模态为主,m模态为辅的输出,同样是第j+1层的输入;
28、所述跨模态融合数据为:
29、
30、
31、
32、其中,omt为跨模态融合数据,fmt为m模态为主,文本模态为辅的最终融合表示,ftm为文本模态为主,m模态为辅的最终融合表示,为融合表示所属向量矩阵。
33、可选地,所述对比学习模块的表达式为:
34、
35、其中,di和dj表示样本和对比样例的特征,表示样本i的正样本集合,表示样本i的负样本集合,sim(di,dj)表示求di和dj的相似性,表示第i个样本的对比损失,τ表示对比损失的温度系数,dk表示样本i的对比样例特征组成的集合。
36、可选地,在训练后的所述分类输出模块中,将所述单模态独立特征数据和所述跨模态融合数据进行结合,一同用于最终的输出预测;
37、所述单模态独立特征数据和所述跨模态融合数据进行结合后的模态表示为:
38、o=concat(ov,oa,ot,ovt,oat)
39、其中,concat代表拼接操作,om代表m模态的独立性特征,omt代表经过m模态和t模态多模态融合后的不变性特征,o代表最终多模态表示,ov代表图像独立特征,oa代表音频独立特征,ot代表文本独立特征,ovt代表图像文本的多模态联合特征,oat代表音频文本的多模态联合特征;
40、所述最终的输出预测为:
41、
42、其中,代表最终输出值,mlp(final)代表将final向量输入mlp模块进行映射,w2代表权重矩阵,relu(v1o)代表relu激活函数对第一层线性层的输出做非线性变换,w1o代表w1权重矩阵乘最终获得的整体多模态表示o,b2代表偏置。
43、可选地,对所述分类输出模块进行训练还包括:设置联合损失函数;
44、所述联合损失函数为:
45、
46、其中,为联合损失函数,α和β都为损失值的正则化项,为回归损失,为对比损失。
47、本发明具有以下有益效果:
48、本发明提出一种mfcon模型的架构,包括:单模态特征提取模块、多模态融合模块、对比学习模块和分类输出模块,首先,提取原始视频的低纬度多模态特征数据;然后将低纬度多模态特征数据,输入单模态特征提取模块,进行特征提取,获取单模态独立特征数据;将单模态独立特征数据,输入多模态融合模块,进行数据融合,获取跨模态融合数据;将跨模态融合数据,输入对比学习模块,使用msa回归主任务和对比学习子任务对分类输出模块进行训练;最后基于训练后的分类输出模块,获取多模态情感预测结果。本发明不仅可以有效捕获跨模态不变特征来识别情感分类,还可以利用模态特定特征预测情感强度。
- 还没有人留言评论。精彩留言会获得点赞!