基于视图内子特征异质性和视图兼容性的聚类方法
本发明属于数据挖掘中的聚类优化,具体涉及到基于视图内子特征异质性和视图兼容性的聚类方法。
背景技术:
1、随着多媒体技术的发展,人们获取信息的途径越来越多。与此同时,多源数据开始大量出现,即从不同的渠道、不同的特征、不同的模态获得的数据信息。多源数据主要分为多模态数据和多视图数据,其中,多模态数据是指从不同传感器或数据源获取的不同形态的输入信息(如文本、视频、音频等);多视图数据是指从多个不同的视图描述同一种数据所获取的信息,且每个视图包含不同的数据特征。在实际应用中,多视图数据主要分为三种:一是从不同物理角度描述对象,例如从不同角度拍摄目标对象获得的图像数据,这种信息普遍具有同质性;二是从不同的视角源描述对象,例如医生结合不同的生理指标来衡量患者的健康状况,如尿检、血检、心电图等;三是同一数据源的不同刻画方式,例如在图像处理中,包含图像重要信息的特征描述子可以构成多视图特征,这些特征具有异质性。相较于传统的单视图数据,多数图数据能够更准确地表达物体的全面信息,具有互补性和兼容性。
2、迫于现实应用的需要,如何构建一个高效的多视图聚类模型成为了热门问题。nie等人在文献“nie f,li j,li x.parameter-free auto-weighted multiple graphlearning:a framework for multiview clustering and semi-supervisedclassification.proceedings of the aaai conference on artificial intelligence,2016:1881-1887.”中通过修改传统的谱聚类模型,提出了一种无参数的自动加权多视图学习(parameter-free auto-weighted multiple graph learning,amgl)模型,该模型可以在没有任何超参数的情况下自动分配权重。li等人在文献“li y,nie f,huang h,etal.large-scale multi-view spectral clustering via bipartite graph.proceedingsof the thirtieth aaai conference on artificial intelligence,2015:2750-2756.”中提出了一种基于二部图的大规模多视图谱聚类方法(multi-view spectralclustering,mvsc),该方法利用局部流形融合合并异构特征。cai等人在文献“cai x,nief,huang h,et al.heterogeneous image feature integration via multi-modalspectral clustering.ieee conference on computer vision and patternrecognition,2011:1977-1984.”中将每一类特征视为一个模态,通过统一不同模态来学习一个共享的图拉普拉斯矩阵,并提出了多模态谱聚类(multimodal spectral clustering,mmsc)。nie等人在文献“nie f,li j,li x.self-weighted multiview clustering withmultiple graphs.proceedings of the aaai conference on artificialintelligence,2017:2564-2570.”中将约束拉普拉斯秩(clr)应用于多视图聚类得到自加权多视图聚类(self-weighted multi-view clustering,swmc),该方法能够自动为不同视图分配权重,并且可以省略后续处理过程。nie等人在文献“nie f,cai g,li x.multi-viewclustering and semi-supervised classification with adaptiveneighbours.proceedings of the aaai conference on artificial intelligence,2017:2408-2414.”中,基于具有自适应邻域的聚类方法提出了具有自适应邻域的多视图聚类(multi-view clustering with adaptive neighbours,mlan),该方法通过学习局部流形结构得到数据相似图,并能自动为每个视图分配适当的权重以整合所有视图。
3、虽然上述多视图聚类方法提供了良好的聚类性能,但它们有两个重要的局限性。第一,它们只考虑视图之间特征的差异,并假设视图内的子特征具有相同的权重。显然,这种假设在实际应用中是不合理的,可能会导致视图中重要属性的丢失或者视图中可忽略属性的权重过大,从而导致聚类结果不准确。第二,基于图的聚类方法虽然具有良好的性能,但大多数方法分为两个独立的步骤,即构建相似度图,然后根据相似度图将样本划分到相关的簇中,因此,相似度图的质量会严重影响样本划分的过程,从而可能导致不理想的聚类结果。
技术实现思路
1、本发明所要解决的技术问题在于克服现有技术的缺点,提供一种基于视图内子特征异质性和视图兼容性的聚类方法。
2、解决上述技术问题所采用的技术方案是:一种基于视图内异构性和视图间兼容性的多视图聚类方法,由以下步骤组成:
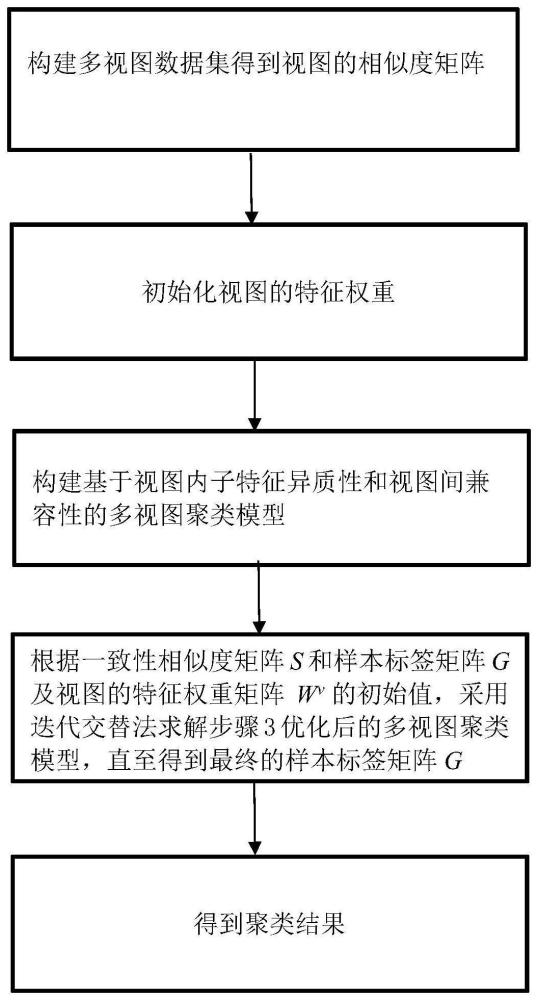
3、步骤1、构建多视图数据集得到视图的相似度矩阵
4、构建多视图样本数据集x={x1,x2,...,xv},v为视图的总数,为第v个视图的特征,v=1,2,…,v,n为样本点总数,d(v)为第v个视图特征的维数,为第v个视图中第i个样本点,定义多视图样本数据集的类别数目为c;
5、根据得到第v视图中第i个样本点与第j个样本点之间的欧式距离,i,j=1,2,...,n;对于同一视图中的每一个样本点,将其他样本点与它的欧式距离按照从小到大进行排序,选择前k个距离最小的样本点作为它的邻域点,按照下式得到第i个样本点与第j个样本点之间的相似度
6、
7、式中,为距离样本点第k+1个近样本点与样本点之间的欧式距离,为第i个样本点与第j个样本点之间的欧式距离,当i=j时,相似度
8、以相似度作为矩阵的第i行j列元素值,得到第v个视图的相似度矩阵sv∈rn×n,v=1,2,...,v;
9、步骤2、初始化视图的特征权重
10、步骤2.1、将所有v个视图的相似度矩阵相加后取平均值,得到初始的一致性相似度矩阵s,按照l=d-(st+s)/2得到初始化的拉普拉斯矩阵l,其中d为度矩阵,是对角矩阵,其第i个对角元素为sij为一致性相似度矩阵s的第i行j列元素;
11、步骤2.2、按照下式初始化视图的特征权重矩阵wv∈rd(v)×d(v),v=1,2,...,v,
12、
13、式中,是第v个视图的对角矩阵hv中第i个对角元素,是第v个视图的对角矩阵hv中第j个对角元素,为视图内第i个子特征所对应的权重,diag(*)为对角矩阵;
14、步骤3、构建基于视图内子特征异质性和视图间兼容性的初始多视图聚类模型如下:
15、
16、式中,s.t.表示目前函数受约束条件的限制,i表示单位向量,si表示一致性相似度矩阵s的第i行向量,t表示转置符号,wv表示第v个视图的权重向量,γ表示正则化参数,rank(l)=n-c表示秩约束,用于确保s对应的相似图具有精准的c个连通分量;
17、在kyfan定理的激励下,优化多视图聚类模型,得到优化后的多视图聚类模型如下:
18、
19、式中,‖*‖f为f的范数,tr为矩阵的迹,λ为正则化参数,g为样本标签矩阵;
20、步骤4、根据一致性相似度矩阵s和样本标签矩阵g及视图的特征权重矩阵wv的初始值,采用迭代交替法求解步骤3优化后的多视图聚类模型,直至得到最终的样本标签矩阵g;
21、所述迭代交替法为:
22、步骤1)、固定一致性相似度矩阵s和样本标签矩阵g,得到下式:
23、
24、hv为第v个视图的对角矩阵,其第i个对角元素是的第i个对角元素,
25、求解下式更新视图的特征权重矩阵wv:
26、
27、步骤2)、固定样本标签矩阵g和视图的特征权重矩阵wv,得到下式:
28、
29、
30、
31、式中,gi和gj分别为固定样本标签矩阵g的第i行和第j行向量,i,j=1,2,...,n;
32、令向量中的第j个元素为得到通过拉格朗日函数和kkt条件式得到并求解更新一致性相似度矩阵s,μ∈r为拉格朗日乘子,(*)+=max(*,0);
33、步骤3)固定一致性相似度矩阵s和视图的特征权重矩阵wv,按照下式求解更新样本标签矩阵g:
34、
35、样本标签矩阵g的最优解由l的c个最小特征值所对应的的特征向量构成;
36、步骤4)、迭代停止判断
37、分别将一致性相似度矩阵s和样本标签矩阵g及特征权重矩阵wv的上次值和此次更新得到的值代入下式目标函数obj:
38、
39、若得到的两个目标函数值obj的差值≤设定的阈值,则停止迭代,得到的g为最终的标签矩阵;若超出设定的阈值,则返回步骤1)继续迭代更新;
40、步骤5、按照下式得到聚类结果:
41、yi=argmax1≤j≤c gij,i=1,2,...,n
42、式中yi为第i个样本的标签,gij是步骤4得到的最终的样本标签矩阵g的第i行j列元素。
43、作为一种优选的技术方案,所述步骤4的步骤2)中正则化参数γ为:
44、
45、式中,为向量中的第k+1个元素。
46、作为一种优选的技术方案,步骤4的步骤4)中阈值为10-8。
47、本发明的有益效果如下:
48、本发明自动的为每个视图中的子特征赋予权重,既考虑了视图间的一致性,又考虑了视图间子特征的差异性,从而使每个属性获得更精准的权重;此外,所提方法通过学习局部流形结构得到数据相似性图,并在构建相似性图的同时通过施加秩约束进行聚类划分,解决了传统基于图的聚类严重依赖于相似性图的问题,从而获得更好的聚类结果。
- 还没有人留言评论。精彩留言会获得点赞!