一种基于深度学习的AI加速器混合量化方法及硬件设计
本发明涉及芯片,尤其涉及一种基于深度学习的ai加速器混合量化方法及硬件设计。
背景技术:
1、随着深度学习的发展,各种高性能、深层次的卷积神经网络涌现出来,广泛运用在语义分割、图像识别和目标检测等领域,但高性能也带来了高昂的计算和内存成本,而边缘端部署卷积神经网络已经目前深度学习的热门趋势,但是边缘端的嵌入式设备资源受限,对能耗也有很高的要求,且有相应的实时性要求,直接部署大型的卷积神经网络不太现实,需要在保证网络模型准确率的前提下,尽量压缩模型,减少模型的尺寸大小和网络参数的存储空间,将模型轻量化,提高神经网络模型部署到嵌入式设备后的应用效果。
2、实现模型的轻量化的方法有很多,包括剪枝、量化、低秩分解和知识蒸馏等,其中量化可以通过减少神经网络中权重和激活的维数,将原本使用较多比特表示的参数量化为使用较少比特表示,近年来,随着模型轻量化的发展,多种量化方法也被提出,它们能够与硬件优化相结合,有效减少硬件乘法器资源和加法器资源的消耗。2011年,研究者成功将神经网络中32位浮点数表示的网络参数用8位定点数表示,成功将网络的存储需求减小为原来的四分之一,达到了模型压缩的目标。后来又发展出了二值化量化方法,二值化量化是将权重和激活值量化为1和-1两个值表示,这种方法虽然可以大幅降低存储开销和计算复杂度,但是会带来很大的精度损失,后来又衍生出三值化量化方法,将神经网络参数压缩为-1,0和1三个值表示,相对于二值化网络,三值化量化方法在一些场景具有更高的准确度。
3、但是这些量化方法都会在不同程度上对网络的准确率造成一定影响,因为一个卷积神经网络不同层的权重参数的重要程度不同,所以把它们量化为同一比特的定点数会造成网络精度和性能的下降,从而影响边缘端部署的实时性和准确度。
技术实现思路
1、为了解决上述技术问题,本发明的目的是提供一种基于深度学习的ai加速器混合量化方法及硬件设计,实现一个网络内不同层参数的混合量化,合理的将影响程度不同的网络参数量化为不同比特,提高轻量化网络的性能和准确率。
2、本发明所采用的第一技术方案是:一种基于深度学习的ai加速器混合量化方法,包括以下步骤:
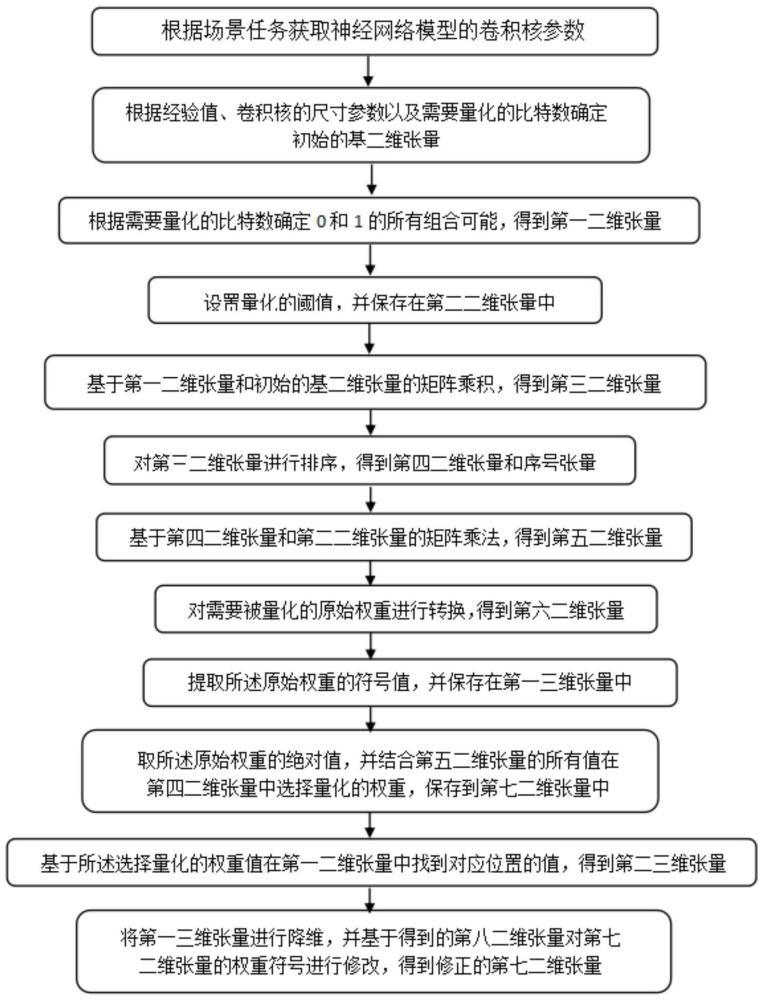
3、根据场景任务获取神经网络模型的卷积核参数;
4、根据经验值、卷积核的尺寸参数以及需要量化的比特数确定初始的基二维张量;
5、根据需要量化的比特数确定0和1的所有组合可能,得到第一二维张量;
6、设置量化的阈值,并保存在第二二维张量中;
7、基于第一二维张量和初始的基二维张量的矩阵乘积,得到第三二维张量;
8、对第三二维张量进行排序,得到第四二维张量和序号张量;
9、基于第四二维张量和第二二维张量的矩阵乘法,得到第五二维张量;
10、对需要被量化的原始权重进行转换,得到第六二维张量;
11、提取所述原始权重的符号值,并保存在第一三维张量中;
12、取所述原始权重的绝对值,并结合第五二维张量的所有值在第四二维张量中选择量化的权重,保存到第七二维张量中;
13、基于所述选择量化的权重值在第一二维张量中找到对应位置的值,得到第二三维张量;
14、将第一三维张量进行降维,并基于得到的第八二维张量对第七二维张量的权重符号进行修改,得到修正的第七二维张量。
15、进一步,所述基二维张量表示卷积核所有权重共用的一组基底;所述第一三维张量表示符号位的数据;所述第二三维张量为一个卷积核中每个权重数据独有的线性张量。
16、进一步,所述取所述原始权重的绝对值,并结合第五二维张量的所有值在第四二维张量中选择量化的权重,保存到第七二维张量中这一步骤,其具体包括:
17、取所述量化权重的绝对值,从小到大排序后分别与第五二维张量的所有值进行比较,得到比较结果;
18、基于比较结果在第四二维张量的对应位置选择量化的权重值,并将量化的权重值保存到第七二维张量中。
19、进一步,所述将第一三维张量进行降维,并基于得到的第八二维张量对第七二维张量的权重符号进行修改,得到修正的第七二维张量这一步骤,其具体包括:
20、对第一三维张量进行降维,得到第八二维张量;
21、基于第八二维张量里的符号值对第七二维张量的的权重符号进行修改,得到修正的第七二维张量。
22、本发明所采用的第二技术方案是:一一种基于深度学习的ai加速器的硬件设计,设计的卷积计算单元包含若干个处理阵列单元,其中:
23、所述处理阵列单元包含若干个乘累加模块;
24、所述乘累加模块包含加法树模块;
25、所述加法树模块用于对输入激活和修正后的向量位进行累加操作;
26、所述乘累加模块基于加法树模块的输出与基底数据进行乘积操作,并对乘积结果进行累加,输出乘累加的中间值结果;
27、所述处理阵列单元对乘累加模块输出的中间值结果进行累加,直到一个卷积核和对应区域内部的输入激活的卷积操作完成;
28、所述卷积计算单元用于同时进行多个卷积操作。
29、进一步,所述修正后的向量位,其获取方式如下:
30、对权重数据进行调整,得到计算标志位和向量位;
31、基于符号位数据对向量位的数据正负性进行调整,得到修正后的向量位。
32、本发明方法、系统的有益效果是:本发明用权重量化算法将权重参数由浮点数量化成定点数,并且可以根据权重数据的大小,把每个权重数据量化成不同的比特,大大减少了权重数据所需的存储空间;通过把权重数据量化成基二维张量和第二三维张量,针对卷积神经网络每一层层内的所有权重数据进行量化,可以将所有权重数据量化至不同比特,大大减少了权重参数所需存储空间,同时网络的精度的损失很小;通过设计的乘累加模块,提高了硬件加速器计算效率和性能;通过并行处理阵列单元设计的卷积计算单元能够同时进行多个卷积操作,提高了整个卷积计算单元的计算效率。
技术特征:
1.一种基于深度学习的ai加速器混合量化方法,其特征在于,包括以下步骤:
2.根据权利要求1所述一种基于深度学习的ai加速器混合量化方法,其特征在于,所述基二维张量表示卷积核所有权重共用的一组基底;所述第一三维张量表示符号位的数据;
3.根据权利要求1所述一种基于深度学习的ai加速器混合量化方法,其特征在于,所述取所述原始权重的绝对值,并结合第五二维张量的所有值在第四二维张量中选择量化的权重,保存到第七二维张量中这一步骤,其具体包括:
4.根据权利要求1所述一种基于深度学习的ai加速器混合量化方法,其特征在于,所述将第一三维张量进行降维,并基于得到的第八二维张量对第七二维张量的权重符号进行修改,得到修正的第七二维张量这一步骤,其具体包括:
5.一种基于深度学习的ai加速器的硬件设计,其特征在于,设计的卷积计算单元包含若干个处理阵列单元,其中:
6.根据权利要求5所述一种基于深度学习的ai加速器的硬件设计,其特征在于,所述修正后的向量位,其获取方式如下:
技术总结
本发明公开了一种基于深度学习的AI加速器混合量化方法及硬件设计,该方法包括根据经验值、卷积核的尺寸参数以及需要量化的比特数确定初始的基二维张量;基于初始的基二维张量设置阈值二维张量;提取所述原始权重的符号值,并保存在第一三维张量中;基于阈值二维张量和量化的权重值得到第二三维张量。该硬件设计包括卷积计算单元、处理阵列单元、乘累加模块和加法树模块。通过使用本发明能够实现一个网络内不同层参数的混合量化,合理的将影响程度不同的网络参数量化为不同比特,提高轻量化网络的性能和准确率。本发明可广泛应用于芯片技术领域。
技术研发人员:胡湘宏,符善森,林元妙,李学铭,黄宏敏,熊晓明,蔡述庭,詹瑞典
受保护的技术使用者:广东工业大学
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!