基于生成式预训练模型的病历检索系统的制作方法
本发明涉及病历检索领域,具体涉及一种基于生成式预训练模型的病历检索系统。
背景技术:
1、在医疗系统中,调取病患的医疗信息是不可或缺的步骤之一,现有的搜索病患的医疗信息的方式通常采用病历搜索,常见的病历搜索方式是基于全文检索技术方案实现病历的搜索。然而,基于全文检索实现的病历检索方案,主要依赖于全文词汇的匹配,匹配效率低,因此基于es元数据结构映射的病历检测系统营运而生。
2、目前基于es元数据结构的映射病历检索系统在使用过程中,需要操作人员根据自身需要将减速条件拆分成多个检索单元分别输入,并进行多次点选组装,以组成复杂的检索式,操作过程复杂繁琐,病历检索效率低。
技术实现思路
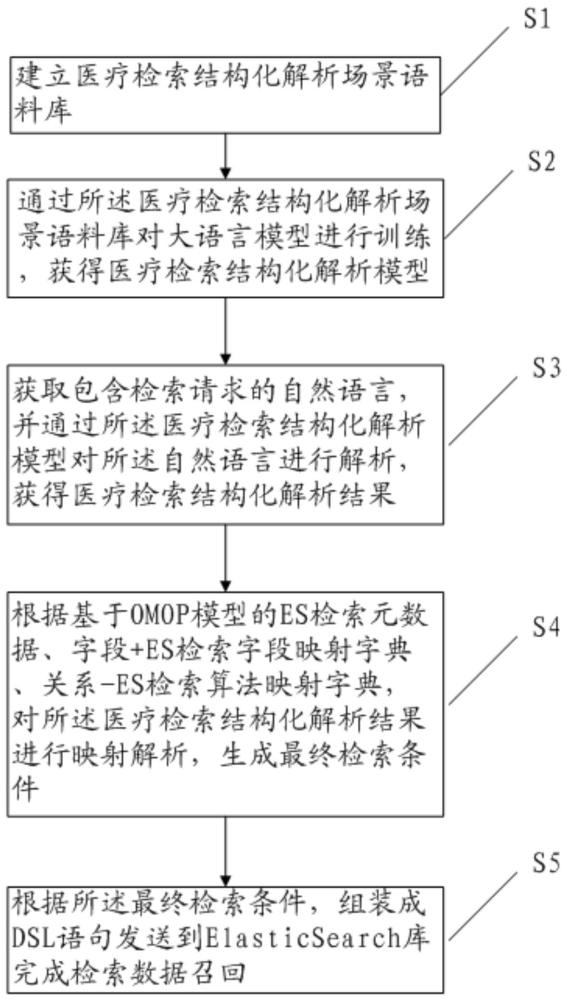
1、为实现上述本发明的目的,本发明提出一种基于生成式预训练模型的病历检索方法,包括以下步骤:
2、步骤s1、建立医疗检索结构化解析场景语料库;
3、步骤s2、通过所述医疗检索结构化解析场景语料库对生成式预训练模型进行训练,获得医疗检索结构化解析模型;
4、步骤s3、获取包含检索请求的自然语言,并通过所述医疗检索结构化解析模型对所述自然语言进行解析,获得医疗检索结构化解析结果;
5、步骤s4、根据基于omop模型的es检索元数据、字段+es检索字段映射字典、关系-es检索算法映射字典,对所述医疗检索结构化解析结果进行映射解析,生成检索条件;
6、步骤s5、根据所述检索条件,组装成dsl语句发送到elasticsearch库完成检索数据召回。
7、根据本发明的一个技术方案,在所述步骤s1中,所述建立医疗检索结构化解析场景语料库包括以下步骤:
8、步骤s11、依据业务已积累的tb级基于omop模型真实世界医疗数据,按语料生成规则生成语料库喂养数据集;所述语料生成规则如下:
9、逐表读取omop模型中数据,读取其中“字段+es检索字段映射字典”中“es检索字段”对应数据,按“关系-es检索算法映射字典”中“关系”数据,交叉生成语料库喂养数据词条;
10、步骤s12、利用语料库喂养数据集进行生成式预训练模型训练及调整;
11、步骤s13、导出保存训练后调整后语料库供后续使用。
12、根据本发明的一个技术方案,在所述步骤s2中,所述医疗检索结构化解析结果包括若干组结构化检索条件,每组结构化检索条件的输出结构为“[字段][关系][值]”。
13、根据本发明的一个技术方案,在所述步骤s4中,具体包括:
14、步骤s41、加载基于omop模型的es检索元数据、字段+es检索字段映射字典和关系-es检索算法映射字典;
15、步骤s42、根据所述基于omop模型的es检索元数据、所述字段+es检索字段映射字典和所述关系-es检索算法映射字典,对若干组所述结构化检索条件进行逐组解析和语义转换,形成多组检索单元;
16、步骤s43、对多组所述检索单元中的“[字段]”部分逐组进行数据裁剪;
17、步骤s44、根据所述结构化检索条件的字段类型,对裁剪后的多组检索单元进行关系建立和关系重整。
18、根据本发明的一个技术方案,在所述步骤s41中,具体包括:
19、通过所述字段+es检索字段映射字典,对所述结构化检索条件中的字段,与所述es检索元数据中的底层字段相关联;所述字段+es检索字段映射字典中包含对所述字段的同义词的兼容添加;
20、通过所述关系-es检索算法映射字典,对所述结构化检索条件中的关系,与所述es检索元数据中的底层逻辑关系进行映射处理;所述关系-es检索算法映射字典中包含对所述关系的同义词的相同逻辑映射处理。
21、根据本发明的一个技术方案,在所述步骤s43中所述数据裁剪的规则如下:
22、根据所述结构化检索条件中的“[字段]”部分的字段类型,进行[关系][值]的裁剪;
23、其中,所述字段类型包括文本字段、数字字段和日期字段;
24、所述“[关系]”裁剪通过将“关系-es检索算法映射字典”的所有[关系]列的内容与所述结构化检索条件中的“[关系]”进行正则匹配,若存在,被裁剪的所述检索单元中的“[关系]”部分为对应字典值;
25、所述文本字段的默认的“[关系]”部分为“包含”,所述文本字段的对应的“[值]”部分为所述结构化检索条件正则匹配处后续文本内容;
26、所述数字字段的默认的“[关系]”部分为“等于”,所述数字字段的对应的“[值]”为所述结构化检索条件正则提取到的第一个数值;如果该数字字段的“[关系]”部分为“区间内”或“区间外”,则继续正则提取第二个数值,如果提取不到则先不设置“[值]”部分的内容,后续通过人工录入设置;
27、所述日期字段的默认“[关系]”部分为“等于”,所述日期字段的对应的“[值]”部分为所述结构化检索条件正则提取到的第一个符合“yyyy-mm-dd”格式的文本;如果该日期字段的“[关系]”部分为“区间内”或“区间外”,则继续正则提取第二个符合“yyyy-mm-dd”格式的文本,如果提取不到则先不设置“[值]”部分的内容,后续通过人工录入设置。
28、根据本发明的一个方面,一种基于生成式预训练模型的病历检索系统,包括:
29、医疗检索结构化解析模块,用于对经包含病历检索条件的自然语言进行解析,生成医疗检索结构化解析结果;
30、检索映射模块,用于对所医疗检索结构化解析结果进行映射解析,生成检索条件;
31、病历检索模块,用于根据所述检索条件,组装成dsl语句发送到elasticsearch库进行检索和数据召回;
32、其中,所述检索映射模块包括:
33、映射字典模块,用于构建和加载基于omop模型的es检索元数据、字段+es检索字段映射字典和关系-es检索算法映射字典;
34、语义转换模块,用于根据所述es检索元数据、所述字段+es检索字段映射字典和所述关系-es检索算法映射字典,对所述医疗检索结构化解析结果进行逐组解析,生成多组检索单元;
35、数据裁剪模块,用于根据底层数据类型,对所述检索单元中字段部分的原始数据进行裁剪;
36、关系重整模块,用于对多组所述检索单元的关系进行生成和重整,生成检索条件。
37、根据本发明的一个技术方案,所述医疗检索结构化解析模块包括:
38、语料库构建模块,用于构建医疗检索结构化解析场景语料库;
39、训练模块,用于通过所述医疗检索结构化解析场景语料库,对生成式预训练模型进行多轮训练,并输出医疗检索结构化解析模型;
40、医疗检索结构化解析模型模块,用于通过所述医疗检索结构化解析模型,进行输入语言的结构化解析。
41、根据本发明的一个技术方案,所述医疗检索结构化解析模块还包括语音识别模块,用于根据输入的语言提取文字,并将其输入至所述医疗检索结构化解析模型模块。
42、本发明实施例的基于生成式预训练模型的病历检索方法及系统,相比于现有技术,具有以下有益效果:
43、本发明通过经医疗检索结构化解析场景语料库训练形成的医疗结构化解析模型,对包含检索请求的自然语言解析转化成医疗检索结构化解析结果,并根据基于omop模型的es检索元数据、字段+es检索字段映射字典、关系-es检索算法映射字典,对医疗检索结构化解析结果进行映射解析形成检索条件,对病历进行检索,检索过程操作简单,无需用户对检索请求进行拆分和多次点选及组装查询条件,可简化用户的输入,屏蔽数据模型层,让用户聚焦业务检索需求本身,大大提高病历检索的效率和便捷程度,提高用户体验。通过gpt服务预置检索语法库,完成自然语言语法拆解,结合es元数据结构映射,实现符合期望的病历检索召回。
44、本发明,通过语义转换形成多组检索单元,并通过检索单元关系重整,对检索条件进行完善和确认,提高了检索条件的准确性,进而提高病历检索的效率。
- 还没有人留言评论。精彩留言会获得点赞!