一种基于知识迁移和自监督学习的纵向联邦金融风控方法与流程
本发明涉及金融风控,具体涉及一种基于知识迁移和自监督学习的纵向联邦金融风控方法。
背景技术:
1、随着信息革命的发展,海量的数据在不断地产生,然而由于隐私政策的保护,不同行业、部门之间存在数据壁垒,很多数据不能被轻易的获取,数据间相互隔离,形成了一个个数据孤岛,而仅凭各部门独立数据训练的机器学习模型,经常存在精度低和泛化能力弱等问题,主要原因在于各部门的数据量有限。联邦学习在满足数据隐私要求、数据安全保护和遵守政府法规的前提下,建立数据孤岛间沟通的桥梁,进行数据使用和机器学习建模,成为解决该类问题的一个有利方案。
2、纵向联邦是联邦学习中的一个重要分支,适用于参与者的数据特征重叠较少,而样本重叠较多的场景,比如某个地区的银行和电商的共同客户数据。在金融风控场景中,纵向联邦学习有着巨大的潜力,因为金融机构拥有借贷记录,各互联网电商拥有消费信息,在保护数据隐私的前提下,通过纵向联邦学习,可以提高对客户信用风险的评估和预测能力,降低坏账率,提高业务效率。
3、传统的纵向联邦学习针对的是用户样本重叠较多的场景,然而现实场景中经常随着参与建模的机构的增多,重叠的用户样本越来越少,仅使用传统的纵向联邦技术对重叠样本数据训练,得到的模型预测精度低,无法满足实际需求,且浪费了大量的非重叠样本数据。
4、现有的联邦技术主要通过自监督学习,利用非重叠样本的特征数据增强每个参与方模型表示层的表示能力,如专利号为cn202210924931.5的专利《基于自监督学习的纵向联邦学习方法、装置和存储介质》,然而这类方法浪费了有标签方的非重叠样本的重要标签信息。
技术实现思路
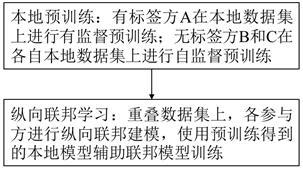
1、本发明的目的在于弥补当前技术的不足与缺点,提供一种基于知识迁移和自监督学习的纵向联邦金融风控方法。本发明的目的通过下述技术方案实现,具体包括以下步骤:
2、(1)在有标签的金融机构本地数据集上,进行有监督预训练,通过最小化损失函数得到本地预训练模型权重;
3、(2)在无标签的各互联网电商本地数据集上,分别进行自监督预训练,得到各自本地预训练模型表示层权重;
4、(3)在重叠的数据集上进行纵向联邦建模得到纵向联邦模型,并利用所述步骤(1)得到的本地预训练模型权重和步骤(2)中得到的各自本地预训练模型表示层权重辅助纵向联邦模型训练,再通过最小化目标损失函数得到训练完成的纵向联邦模型;
5、(4)利用所述步骤(3)训练完成的纵向联邦模型完成金融风控预测;所述纵向联邦模型也称为金融风控模型。
6、进一步地,所述步骤(1)中的本地预训练模型包括本地预训练模型表示层和本地预训练模型推理层。
7、进一步地,所述有标签的金融机构只有一个,即为有标签方,那么所述步骤(1)中损失函数的数学表达式为:;其中,a为有标签方,为本地预训练模型表示层,为本地预训练模型表示层权重,为本地预训练模型推理层,与纵向联邦模型有标签方推理层相同,为本地预训练模型推理层权重,为误差函数。
8、进一步地,所述步骤(2)具体为:所述无标签的各互联网电商能够有若干个,即无标签的各方,对无标签的各方分别在各自本地数据集上进行自监督学习,并采用对比学习的方法计算原始数据和增强后的数据在经过相同本地预训练模型后的相似度,通过最小化对比损失函数分别训练得到各自本地预训练模型表示层权重。
9、进一步地,若无标签的各方分别为b和c时,那么所述对比损失函数和的数学表达式为:
10、;
11、;
12、其中,和为无标签方b和无标签方c各自本地预训练模型表示层,与纵向联邦模型无标签方各自表示层相同,和为各自本地预训练模型表示层权重,和分别为参与方b和参与方c增强后的数据,为本地预训练模型映射层,为本地预训练模型映射层权重,为对比误差函数。
13、进一步地,所述步骤(3)具体为,对无标签的各互联网电商,将其本地预训练模型表示层权重用于其对应的纵向联邦子模型权重的初始化,然后在重叠数据集上进行训练,并将各自训练的结果,即纵向联邦模型无标签各方表示层计算得到的结果,发送给有标签的金融机构;有标签的金融机构利用纵向联邦模型有标签方表示层在重叠样本数据上训练,将其训练结果与接收到的纵向联邦模型无标签各方表示层计算的结果合并,然后进行纵向联邦模型推理层训练,计算纵向联邦损失函数;在纵向联邦模型训练的同时,对有标签的金融机构,通过引入约束函数到目标损失函数中,从而将其本地预训练模型知识迁移到其对应的纵向联邦子模型中,最后通过最小化目标损失函数,得到训练完成的纵向联邦模型;所述纵向联邦子模型是指在纵向联邦学习过程中各参与方使用的局部模型,所有局部模型包括纵向联邦模型有标签方表示层,纵向联邦模型无标签各方表示层,和纵向联邦模型有标签方推理层,所有局部模型的组合即为纵向联邦模型。
14、进一步地,所述有标签的金融机构利用纵向联邦模型有标签方表示层在重叠样本数据上训练,将其训练结果与接收到的纵向联邦模型无标签各方表示层计算的结果合并,其结果合并的数学表达式为:;其中,a为有标签方,b和c为无标签方,,和为各参与方重叠样本数据,为纵向联邦模型有标签方表示层计算得到的结果,和为纵向联邦模型无标签各方表示层计算得到的结果,为纵向联邦模型有标签方表示层权重,和分别为纵向联邦模型无标签方b和无标签方c表示层权重,为纵向联邦模型推理层输入数据,表示拼接各参与方中间计算结果。
15、具体地,所述纵向联邦损失函数的数学表达式为:,
16、其中,为纵向联邦模型推理层权重,为联邦误差函数;
17、所述约束函数的数学表达式为:;其中,为约束误差函数,表示部分权重,经过后与权重大小一致;
18、所述约束函数的数学表达式为:;其中,为调节系数,调节约束函数所占比重,通过最小化目标损失函数,完成纵向联邦模型训练。
19、本发明的第二个方面:一种基于知识迁移和自监督学习的纵向联邦金融风控装置,该装置包括以下模块:
20、有监督预训练模块:在有标签的金融机构本地数据集上,进行有监督预训练,通过最小化损失函数得到本地预训练模型权重;
21、自监督预训练模块:在无标签的各互联网电商本地数据集上,分别进行自监督预训练,得到各自本地预训练模型表示层权重;
22、纵向联邦模型训练模块:在重叠的数据集上进行纵向联邦建模得到纵向联邦模型,并利用所述有监督预训练模块得到的本地预训练模型权重和自监督预训练模块中得到的各自本地预训练模型表示层权重,辅助纵向联邦模型训练,再通过最小化目标损失函数得到训练完成的纵向联邦模型;
23、模型预测模块:利用所述纵向联邦模型训练模块训练完成的纵向联邦模型完成金融风控预测;所述纵向联邦模型也称为金融风控模型。
24、本发明的第三个方面:一种电子设备,包括:
25、一个或多个处理器;
26、存储器,用于存储一个或多个程序;
27、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现所述的基于知识迁移和自监督学习的纵向联邦金融风控方法。
28、本发明与现有技术相比具有以下有益效果:
29、本发明技术方案所述步骤一和步骤二均在各自本地执行,因此不会增加额外的纵向联邦通讯成本,也不会增加隐私泄露的风险。本发明根据有标签方和无标签方数据差异,采取了不同的技术方案,通过知识迁移技术,将从有标签方非重叠用户特征及标签数据中提取到的知识,迁移到了联邦子模型中;通过自监督方法,使用无标签方非重叠用户特征数据增强模型表示层的表示能力。通过这两种技术方案,本发明实现了对非重叠数据的充分利用,大大提升了少重叠样本场景纵向联邦金融风控模型的预测准确度。
- 还没有人留言评论。精彩留言会获得点赞!