一种基于文本引导的图像超分辨方法
本发明属于图像处理,具体涉及一种基于文本引导的图像超分辨方法。
背景技术:
1、图像超分辨指的是从低分辨率的图像中,重建出具有更高分辨率的图像过程。在数字图像的处理过程中,图片往往会受到多种元素的影响,例如相机硬件的不足,网络传输压缩中的损失等,最终导致得到的图像分辨率很低,通过图像超分辨率重建算法,可以使低分辨率图像能够获得更多的实用信息。已有的基于神经网络的方法已经取得了不错的重建效果,然而,需要指出的是,这些方法仅仅依赖与低清图片的信息来恢复出高清图片的细节,当低清图片包含太少的信息时,超分网络则不能很好的恢复出高清图片的细节信息。为了解决这一问题,一些工作通过加入先验信息来增加低清图片的信息,帮助网络重建出高清图像。
2、经检索,现有的技术中都是使用参考图像实现的。如公开号为cn116416132a的中国专利文献公开了一种基于多视角参考图像的图像重建方法、计算机设备及介质,该方案将多个视角的高分辨率图像作为参考图像,采用基于像素变换的有参考超分图像重建方法来对低分辨率图像进行分辨率的提升,缓解了仅仅使用单张参考图像进行超分重建所带来的全局清晰度不一致的问题。这种方式虽然在一定程度上弥补了低清图片信息不足带来的问题,但是在获取高清图片上仍然是一件难题,并且还需要多张高清参考图像进行,在现实场景获取多张参考图像的成本是一个很大的问题。
3、基于以上分析,现有技术需要一种能够使用语义信息来指导图像超分辨的方法。
技术实现思路
1、本发明的目的在于克服传统技术中存在的无法处理现实中复杂多变的图像超分辨问题,提供一种基于文本引导的图像超分辨方法,利用多模态融合的方法来解决单图像超分问题,因此能够适应各种复杂的超分场景,满足了现实中的要求。
2、为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
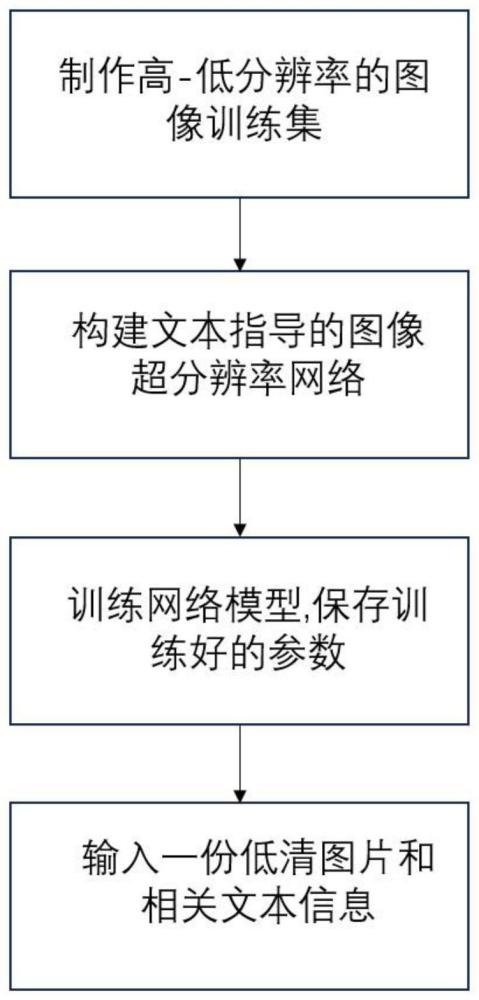
3、本发明提供一种基于文本引导的图像超分辨方法,包括如下步骤:
4、s1、利用已有的数据集,制作高分辨率与低分辨率图像数据集;
5、s2、构建基于文本提示的神经网络模型,用于模型训练;
6、s3、依据步骤s1制作的数据集对步骤s2构建的网络进行训练和测试,保存网络参数;
7、s4、将一张低分辨率图片和其对应的文本信息作为网络的输入,利用步骤s2学习得到的参数重建一张高分辨率的图像作为输出。
8、进一步地,步骤s1中,使用cub和celeba数据集制作高分辨率图像块与低分辨率图像块训练集和测试集,其中cub为一种公开的鸟类数据集,其中每张图像均提供了图像的文本信息;celeba为一种公开的人脸数据集,其中每张图像均提供了图像的文本信息;
9、制作高分辨率与低分辨率的成对图像训练集的过程为:针对使用的数据集中的每张图像,首先将高分辨率图像进行缩放裁剪,其次将得到的图像进行双三次下采样得到低分辨率图像,同时将数据集中每张图片对应的十个文本随机选取其中的一个作为低清图片的文本信息;对数据集中的所有图片进行上述处理,即可得到用于网络训练的低分辨-高分辨图像对集合,同时每张低分辨率图像都有对应的文本信息标签。
10、进一步地,步骤s1中,构建的网络模型是由多种模块组成的,分别为图像编码器、迭代细化生成器、预训练的文本编码器、预训练的clip(contrastivelanguageimagepre-training)网络(公开的多模态模型)、深度图像融合模块以及提示预测器模块;
11、模块的运行流程如下:开始时,先用预训练的文本编码器对选取的文本进行特征提取,将得到的文本特征送入到文本注意力机制中,同时将低清图片送入到图像编码器中,得到图像的特征信息,将图像特征和文本特征进行初步的对齐;然后将文本特征和图片特征同时送入到clip网络中,从clip中得到文本和图像融合后的特征,将文本融合图像后的特征进行迭代融合,恢复更多的细节信息;最后将图像送入到亚像素卷积中对图像进行上采样,然后转换成rgb图像;具体流程用公式(1)表示:
12、tf=cliptextencoder(t)
13、if=imageencoder(ilr)
14、fmult=fblock(tf,if)
15、ic=clip(fmult,tf)
16、isr=upsampling(dn…(d1(ic,tf)) (1)
17、其中,cliptextencoder()表示预训练的clip文本编码器,imageencoder()表示未训练的图像编码器,fblock()表示文本图像对齐,clip表示预训练的clip网络,t表示文本信息,tf表示文本特征,ilr表示低清图片,if表示图像特征,fmult表示多模态特征信息,ic表示从clip中引出的图像特征信息,dn()代表第n次融合细化,isr表示超分后的结果。
18、进一步地,所述预训练的文本编码器是使用的clip文本编码器,用于获取文本特征信息,得到的是1x15的特征向量。
19、进一步地,所述的网络模型中,
20、图像编码器,用于提取图像的特征信息;
21、迭代细化模块,用于迭代细化图像的细节信息;
22、预测器,用于提示词的权重计算;
23、使用的图像编码器中,采用卷积和残差的形式,将输入的低清图片送入到网络中,经过卷积提取后,得到初始的特征信息;
24、使用的迭代细化模块利用从clip中提取出来的图像特征,将特征信息经过多次融合迭代,与文本信息相结合,用来迭代细化图像的特征;其中,在每一次进行迭代后,使用残差将迭代后的特征信息,和图像的特征信息进行相加,用来保持图像内容的一致性,最后通过上采样将图像放大四倍,得到高分辨率图像,在经过卷积层将特征信息恢复成rgb图像;
25、使用的预测器利用文本注意力机制计算文本之间向量的权重信息,其中,由预训练的clip文本编码器提取出文本向量后,将得到的文本向量x送入到多层感知器中,得到n个输入向量{x1,x2,…xn},计算得到q,k,v,具体表示如公式(2)所示:
26、q=q(x)
27、k=k(x)
28、v=v(x)
29、scores=s(q·kt)
30、αn=softmax(scores)
31、
32、其中,输入序列x文本向量经过线性变换得到,q(x)查询,k(x)键,v(x)值,用于计算加权后的表示,s(q·kt)为注意力打分函数,通过softmax()计算注意力权重αn,最后通过注意力权重对xn进行加权求和,得到最后的输出。
33、进一步地,使用clip-vit32:clip-vit32模型的网络架构主要由两部分组成:一个是视觉处理器,采用了visiontransformer(vit)的编码器;另一个是文本处理器,采用了一个简单的前馈神经网络;这两部分共同组成了clip-vit32模型,使其能够同时处理图像和文本数据。
34、进一步地,所述多模态融合通过仿射变换来实现,其主要方式是将文本特征向量经过两个多层感知器,得到通道级的缩放和偏移,使用这两个参数对图像特征通道进行缩放偏移得到融合后的文本信息特征,在每一次融合后,使用函数rule对其进行非线性变换,使得融合后的图像特征更加复杂,在使用文本向量之前,使用softmax()函数对其进行权重的重新计算,具体表示如公式(3)所示:
35、γ=mlp1(t)
36、θ=mlp2(t)
37、aff(in|e)=γn·in+θn (3)
38、其中,t表示文本向量,in表示图像特征信息,γ和θ分别表示通道的缩放和平移。
39、进一步地,使用基于clip模型的判别器,首先使用clip网络对图像特征进行提取,然后将提取到的多层特征信息进行进一步的收集、融合,用来做对抗损失,对抗损失的表达如公式(4)所示:
40、
41、其中sr()表示超分网络,ilr表示低清图片,e表示文本信息。
42、进一步地,在步骤s3中,采用adam优化算法,其中设置α=0.0001去训练网络;采用梯度下降法更新网络参数,用公式(5)表示:
43、
44、其中,vi+1表示本次的权重更新值,而vi表示上一次的权重更新值,而μ是上一次梯度值的权重,α是学习率,是梯度。
45、进一步地,生成网络的损失函数包含三个部分:l1损失,感知损失和生成对抗损失,具体表达式如公式(6)所示:
46、
47、l1=|sr(ilr)-ihr| (6)
48、其中,lr表示低清图片,e代表文本,d()表示判别器,e()表示图像编码器,s()使用来计算图像特征和文本特征之间的余弦相似度;
49、网络的总体损失表示如公式(7)所示:
50、lg总=lg+l1+lprecep (7)
51、其中lg表示生成对抗损失,lprecep表示感知损失,l1用来计算像素之间的损失。
52、本发明的有益效果是:
53、1、本发明考虑到现实场景超分的复杂场景,使用文本信息来对网络进行指导,通过文本信息与低清图片信息之间的互补,指导低清图片生成更多的信息,使得在低清图像特别模糊的情况下仍然能够恢复出较好的细节信息,该方法在单图像超分辨中取得了不错的效果。
54、2、本发明中网络通过文本提示和低清图像特征信息,引导出clip模型中的图像信息,相较于其他超分辨方法而言,本发明方法能够更好的对低分辨图片进行超分。
55、3、本发明利用文本先验信息,对低清图片进行先验指导,通过多模态融合模块,使得图像特征和文本特征能更好的融合,很好的增强了图像的细节部分同时减少了图像的模糊,在单图像超分中有着广泛的应用前景。
56、当然,实施本发明的任一产品并不一定需要同时达到以上的所有优点。
- 还没有人留言评论。精彩留言会获得点赞!