基于FPGA的卷积神经网络加速器实现方法
本发明属于人工智能,涉及一种基于fpga的卷积神经网络加速器实现方法。
背景技术:
1、随着智能化技术的不断发展,人工智能技术已经深入各行各业地应用中。作为人工智能的主要研究分支,神经网络模型在图像检测与识别、目标跟踪和语音识别等诸多领域取得了巨大技术发展。随着神经网络结构的不断加深,在获得更高网络性能的同时,计算复杂度也随之大大提升,使得基于专用硬件设备加速神经网络成为神经网络模型应用领域关注的焦点。目前,神经网络硬件加速器以gpu、asic、fpga为主。gpu能够进行多线程并行处理,由于功耗过大的问题难以在嵌入式平台上应用。asic根据卷积神经网络的结构设计出特定的架构来支持其计算,能实现高性能与低功耗的要求,但在设计过程需要比较长的周期,成本也比较高。fpga具有可重构配置的特点,开发速度快,综合成本低的特点,特别适用于当前神经网络在边缘设备上部署的需求,因此基于fpga的神经网络模型加速研究成为当前神经网络领域研究的热点。
2、根据roof-line模型,可以用算力和带宽这两个指标衡量计算平台所能达到的最大浮点计算速度。roof-line模型的计算力公式由式(1)给出。其中,p为模型理论性能,β为计算平台带宽上限,π为计算平台算力上限,i为模型的计算强度,imax为平台计算力强度上限,等于算力除以带宽。
3、
4、可以看到,要想提升加速器的综合性能,除了考虑加速器并行处理能力,还需考虑加速器的实际带宽情况。在硬件加速器实现过程中,利用fpga的片上存储资源来缓存数据,采用合理的数据加载和复用方式,可以减少计算所需要的数据从片外加载的次数,从而有效降低外部存储器与片上逻辑资源之间的带宽压力,从而提高加速器的整体性能。
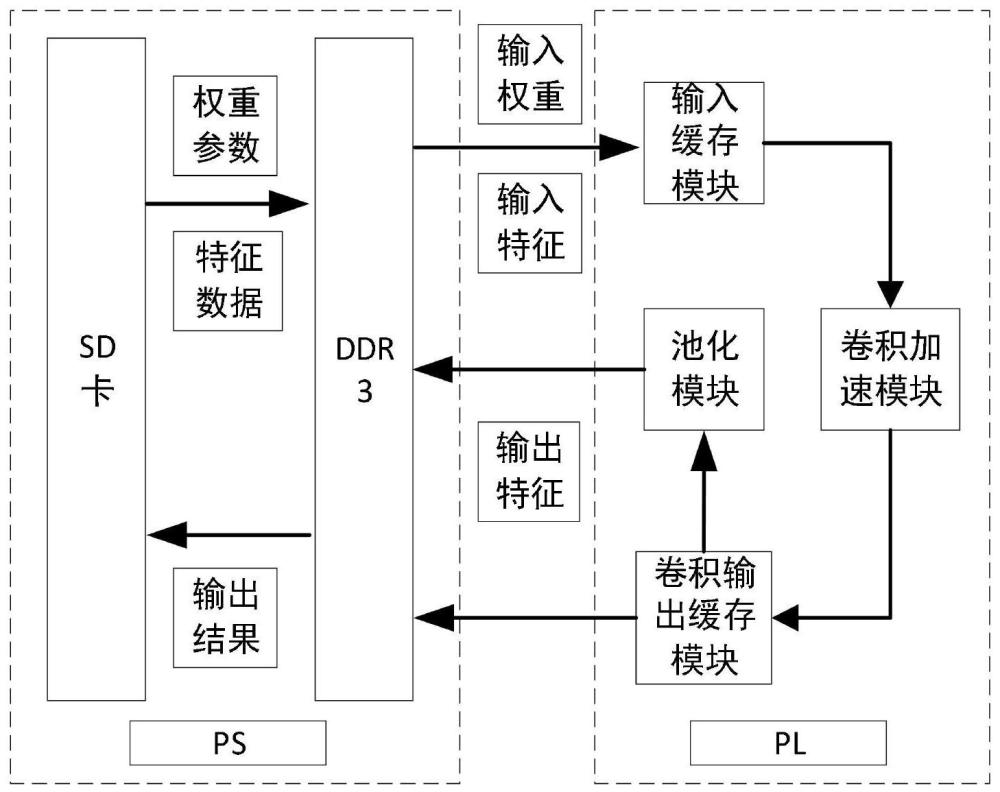
5、fpga加速卷积神经网络的时延开销主要由计算时延和数据传输时延组成。随着网络结构的逐渐复杂化,网络参数也越来越大。在卷积神经网络模型中,每一层的运算都需要从ddr中读取大量的特征数据和权重参数,数据传输和加载的效率是影响硬件加速器性能的重要因素之一。如何提高数据传输和加载效率,成为fpga加速卷积神经网络的关键问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于fpga的卷积神经网络加速器实现方法。通过采用基于行的数据流加载、自适应数据加载方案、基于流水线结构的卷积运算并行化,可以有效地提高fpga加速卷积神经网络的数据传输效率和计算性能。
2、为达到上述目的,本发明提供如下技术方案:
3、基于fpga的卷积神经网络加速器实现方法,该方法包括以下步骤:
4、在pc端上对卷积核参数进行数据分块和重排处理存储于sd卡中,将重排后的数据从sd中读取到片外存储器ddr中进行存储;
5、对输入特征数据进行分块和重排处理;
6、根据当前网络层尺寸以及片上存储空间等条件,自适应从三种数据加载方案中选择数据加载方案;
7、以基于行的数据流的形式读取分块输入特征数据到fpga片上存储器;
8、以流水线结构和并行化运算对输入特征数据和卷积核参数进行卷积运算操作,每个时钟周期能够同时完成9×ti×to次卷积运算;ti为输入通道并行度,to为输出通道并行度;
9、将卷积运算得到的部分中间结果在片上进行缓存,待计算完下一通道数据,将结果与之前结果进行累加,直至计算完所有通道结果,将数据传输给片外存储器缓存;
10、完成当前层所有运算后,将当前层计算结果传输到片上以进行下一层网络计算。
11、进一步,所述自适应从三种数据加载方案中选择数据加载方案具体为:
12、三种数据加载方案分别为:w-h-c加载、w-c-h加载、位于w-h-c和w-c-h之间的加载;
13、w-h-c加载是不需一次运算完所有通道数据,在计算过程中,只需从片外加载一次卷积核参数,然后通过重复加载输入特征数据进行运算;
14、w-c-h加载是一次就计算完所有通道数据,计算过程中,只需从片外加载一次输入特征数据,然后通过重复加载卷积核参数数据进行运算,只需缓存w×h的中间结果;
15、位于w-h-c和w-c-h之间的加载方案取以上两种方案的中间方案进行数据加载,即对输入数据按w、h、c三个方向都进行分块处理;
16、在卷积神经网络中,前若干层卷积层的输入特征数据采用w-c-h数据加载,最后若干层,采用w-h-c的数据加载方案;处想中间的网络层,根据fpga的片上缓存资源和当前网络层尺寸,划分w、h、c的分块大小。
17、进一步,所述以基于行的数据流的形式读取分块输入特征数据到fpga片上存储器具体为:
18、采用基于行数据的输入数据流加载缓存结构,在数据加载方面,只需缓存特征图的两行数据,当开始加载第三行数据,开始卷积运算;在数据回传方面,得到输出数据后立即回传,无需等待得到整幅输出特征图;
19、基于行数据的输入数据流加载结构完成一次卷积层加速总时间ttotal2=t1×2/f1+t2,t1为卷积层读取数据时间,f1为一幅特征图的总行数,t2为卷积层计算计算时间。
20、进一步,所述以流水线结构和并行化运算对输入特征数据和卷积核参数进行卷积运算操作具体为:
21、通过展开卷积运算过程,然后依靠fpga计算来加速,卷积运算并行化处理方式包括核内并行、输入通道并行和输出通道并行;
22、卷积运算过程是六层的for循环;
23、核内并行是通过同时读取一幅特征图的tk×tk个数据,然后与对应权重进行乘累加操作,其中tk为卷积核的长度;
24、输入通道并行是指同一时钟周期读取ti通道特征图像素点,然后与对应的权重数据进行乘累加操作,ti为输入通道并行度;
25、输出通道并行是指在同一时钟周期读取to通道卷积核参数并与特征图像素点进行乘累加操作,to为输出通道并行度;
26、对卷积运算的循环进行流水线处理;设完成一次卷积的时间消耗为tc,当前层所需要执行的卷积运算次数为nc,两次卷积运算之间的时间间隔为tinterval;若未采取流水线处理,tinterval=tc=3;当前层卷积运算的总时间消耗ttotal3=tc×nc=6;若采取流水线处理,tinterval=1,当前层运算的总时间ttotal4=tc+nc-1=4。
27、本发明的有益效果在于:
28、(1)解决了不同大小输入特征图带来的输入数据复用率下降,导致dsp利用率降低的问题。
29、(2)提升了卷积加速器的计算吞吐率。相比传统算法,本方案的乘法运算次数降低2.25倍,加速器吞吐率提升2倍。
30、(3)可以将计算单元的乘法运算之间的时间间隔降低至1个时钟周期,有效提升乘法器的利用率,可以减少片上缓存资源的开销,同时支持计算模块的流水线计算。
31、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!