多策略标签消歧的偏多标签分类方法、设备及存储介质
本发明涉及偏多标签学习,具体涉及一种多策略标签消歧的偏多标签分类方法、设备及存储介质。
背景技术:
1、随着移动互联网的普及和5g技术的推广,越来越多的人们开始依赖于智能手机、平板电脑、摄像机等数字设备,并倾向于将这些设备生成的图像、文本、语音和视频等多样化的数据分享到在线多媒体平台上,这种趋势源于人们对社交互动、内容创作和信息共享的日益需求。近年来,海量数据的产生促进了人工智能领域的蓬勃发展,尤其是在多标签学习方向上取得了显著进展。但在传统的多标签学习研究中,往往假设一个样本被精确地标注为一个或多个标签。然而现实生活中,对于样本标注通常会花费大量的人力财力,一个公司可能对样本标注采取众包的形式,即从网上收集标注者标注的样本。这样由于标注者的专业不一致性,通常就会使得标注的标签集存在噪声。因而,偏多标签学习方法成为一个热点研究问题。
2、偏多标签分类任务中存在的主要问题在于候选标签数据集中存在部分噪声标签,严重影响模型训练。同时,单一的标签消歧策略对于处理噪声数据具有一定的局限性,无法通过考虑实例特征和标签相关性等消歧策略来纠正噪声,无法全面来捕捉到噪声数据的特点,也无法充分考虑真实标签之间的关系,影响输出结果的可靠性。因此,解决该问题的关键在于如何选择有效的标签消歧策略来进行标签去噪。例如xie等(xie ming kun, huangsheng jun. partial multi-label learning[c]. proceedings of the aaaiconference on artificial intelligence. 2018, 32(1).)作者提出了一种偏多标签分类方法,通过从特征消歧策略层面上出发,通过特征原型的方法为每个标签分配一个置信度,然后结合标签排序和置信度矩阵共同构造了偏多标签分类模型,在优化阶段交替优化标签置信度矩阵与分类器;zhang等(zhang ming ling, fang jun peng. partial multi-label learning via credible label elicitation[j]. ieee transactions onpattern analysis and machine intelligence, 2020, 43(10): 3587-3599.)作者从特征消歧策略的角度出发,通过特征最近邻关系进行标签传播来获取标签置信度,利用具有高标签置信度的可信标签,通过虚拟标签增强技术对标签进行两两排序,最终得到标签预测器;sun等(sun li juan , feng song he , wang tao , et al. partial multi-labellearning by low-rank and sparse decomposition[j]. proceedings of the aaaiconference on artificial intelligence, 2019, 33:5016-5023.)是将标签矩阵分解为真实标签矩阵和噪声标签矩阵,将真实标签矩阵约束为低秩,噪声标签矩阵假设为稀疏,从而实现样本的真实标签和噪声标签分离;li等(li zi wei, lyu geng yu, feng, songhe, partial multi-label learning via multi-subspace representation 2020,10.24963.)作者将原始的标签空间分解为标签子空间矩阵和标签相关矩阵来减少噪声标签的负面影响,利用特征间的相关性将原始的带噪声的特征空间映射到一个特征子空间来减小噪声特征的影响,并通过图拉普拉斯正则项约束标签子空间;zhao等(zhao peng,zhao shi yi, zhao xu yang, et al. partial multi-label learning based onsparse asymmetric label correlations[j].knowledge-based systems, 2022, 245:108601.)作者利用标签关系矩阵并限制其稀疏性,同时考虑了非对称的标签关系,直接提取标签的置信度,建立特征与置信度之间的联系,在特征中抽取有用的信息与真实标签置信度建模。
3、然而,上述方法往往采用了从单一策略去考虑候选标签集该如何进行去除噪声标签。但是在偏多标签分类问题中,这种单一消歧策略在处理噪声数据时存在局限性,如果仅仅使用特征消歧策略或者标签消歧策略,它都无法准确捕捉噪声数据的特点,也无法充分考虑真实标签之间的关系,从而影响纠正的效果。为了解决上述问题,本发明提供了一种多策略标签消歧的偏多标签分类方法。
技术实现思路
1、本发明提出的一种多策略标签消歧的偏多标签分类方法,可至少解决上述提到的技术问题中的其中一项问题。
2、为实现上述目的,本发明采用了以下技术方案:
3、一种多策略标签消歧的偏多标签分类方法,所述方法步骤如下,
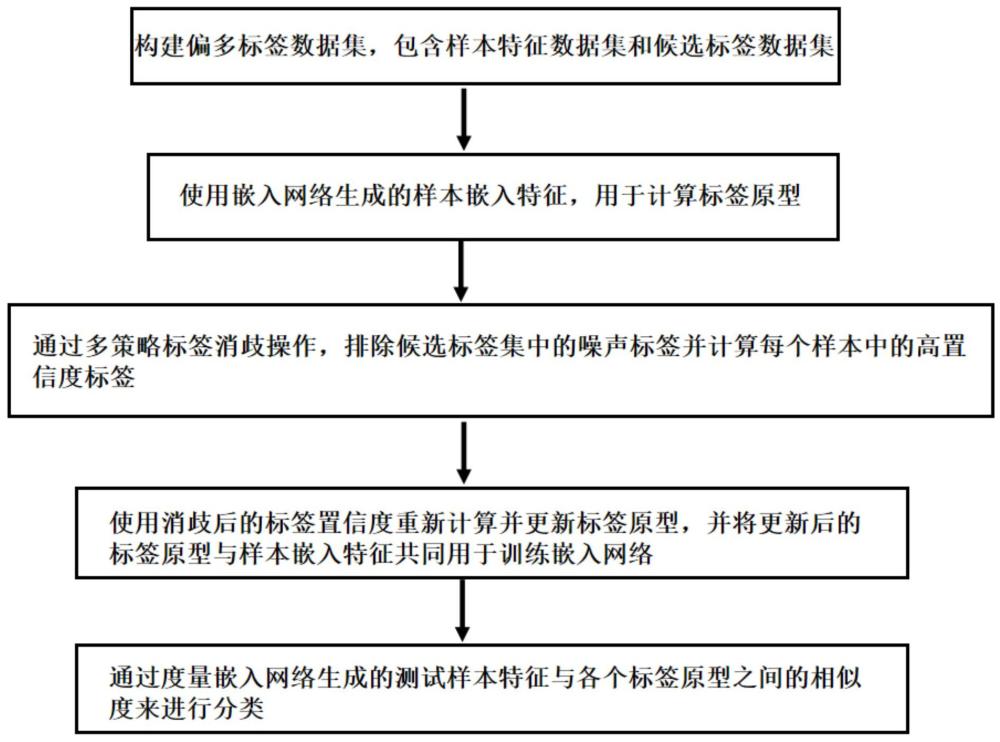
4、s1、构建偏多标签数据集,包含样本特征数据集和候选标签数据集,候选标签数据集中除了包含部分相关标签外,还包含一部分不相关的噪声标签。其中样本特征数据集和候选标签数据集都用于训练嵌入网络和计算标签原型;
5、s2、使用嵌入网络生成的样本嵌入特征,用于计算标签原型;
6、s3、通过多策略标签消歧操作,排除候选标签集中的噪声标签并计算每个样本中的高置信度标签;
7、s4、使用消歧后的标签置信度重新计算并更新标签原型,并将更新后的标签原型与样本嵌入特征共同用于训练嵌入网络;
8、s5、通过度量嵌入网络生成的测试样本特征与各个标签原型之间的相似度来进行分类。
9、进一步的,所述步骤s1具体包括:
10、构建偏多标签数据集,包括样本数据集和候选标签数据集,其中样本特征表示,其中n表示样本的个数,d是特征的维度,表示第i个样本特征的列向量,候选标签矩阵表示为,其中c是类别数,表示第i个标签列向量,表示为 (,其中=1表示第i个样本的第j个标签在此样本的候选标签集里,反之=0;
11、偏多标签分类任务的目标是从特征矩阵和候选标签矩阵中学习多标签预测模型,为新样本预测标签。
12、进一步的,所述步骤s2使用嵌入网络生成的样本嵌入特征,用于计算标签原型;具体包括,
13、s21、将样本特征送入到嵌入网络生成其嵌入特征,对应特征的维度进行变换,即。相关标签原型计算公式为:
14、
15、其中标签原型矩阵p∈,表示第j个 标签原型向量;
16、s22、不相关标签原型计算公式为:
17、
18、其中表示第j个 标签不相关原型向量。
19、进一步的:所述步骤s3通过多策略标签消歧操作,排除候选标签集中的噪声标签并计算每个样本中的高置信度标签;
20、多策略标签消歧是由标签原型消歧策略、特征-标签一致性消歧策略、标签相关性消歧策略组成。候选标签集在经过不同策略下的标签消歧操作后,可获得较为可信的标签置信度,其中置信度标签矩阵,其中表示第i个样本的标签置信度向量,,表示为[,表示为表示第i个样本下的第j个标签的标签置信度;
21、s31、通过计算样本到相关原型和不相关原型的欧式距离来计算标签原型策略下的标签置信度,计算公式为:
22、
23、其中表示在标签原型策略第i个样本下的第j个标签的标签置信度,表示当前迭代次数,表示计算两者之间的欧式距离。
24、s32、通过计算特征相似度和标签语义相似度来更新特征-标签一致性策略下的标签置信度,计算公式为:
25、
26、
27、
28、其中表示第i个样本特征与第j个样本特征之间余弦相似度,表示第i个样本的标签置信度向量与第j个样本的标签置信度向量之间余弦相似度。
29、s33、通过计算标签相关性消歧策略下的标签置信度,计算公式为:
30、
31、
32、其中表示为在第j个标签存在的情况下第k个标签存在的概率, 其中表示标签k和标签j同时出现的次数,表示标签j出现的次数,表示候选标签集中同时包含标签 k 和j 的样本数量。
33、s34、计算消歧后的置信度并对其进行归一化,计算公式为:
34、
35、
36、进一步的:所述步骤s4包括使用消歧后的标签置信度重新计算并更新标签原型,并将更新后的标签原型与样本嵌入特征共同用于训练嵌入网络;
37、s41、重新计算相关标签原型,其计算公式为:
38、
39、s42、重新计算不相关标签原型,其计算公式为:
40、
41、s43、通过欧式距离计算嵌入特征与标签原型之间的距离,其中第个样本属于类j的概率计算公式为
42、
43、其中表示第i个样本属于标签j的概率值;
44、s44、设置一个阈值,过滤掉概率值较小的标签置信度,获得真实标签,计算公式为:
45、
46、s45、计算交叉熵损失函数,计算公式为:
47、。
48、进一步的:所述步骤s5通过度量嵌入网络生成的测试样本特征与各个标签原型之间的相似度,进行分类;
49、s51、在标签原型校正之后,给定测试样本,通过计算样本特征与标签j的相关标签原型和不相关标签原型的距离,用softmax函数来预测其是否具有标签j,因此,测试样本的预测标签集可以计算如下:
50、
51、其中
52、又一方面,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述方法的步骤。
53、再一方面,本发明还公开一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如上方法的步骤。
54、由上述技术方案可知,本发明的多策略标签消歧的偏多标签分类方法,在含有多标签噪声数据情况下,通过单一的消歧策略计算标签置信度,并将消歧后的标签置信度和样本特征一起构成训练集。使用消歧后的标签置信度重新计算并更新标签原型,并将更新后的标签原型与样本嵌入特征共同用于训练嵌入网络。通过计算嵌入网络生成的测试样本嵌入特征与其各个标签原型之间的相似度,进行分类。但由于噪声标签与真实标签之间存在分布差异,导致单一的消歧策略无法正确地捕捉到真实数据的分布和标签之间的关系。为了解决这个问题,本发明通过标签原型、特征-标签一致性、标签相关性等多个消歧策略用于计算标签置信度,并选择可信度高的标签置信度数据用于模型训练,以便更好地捕捉和建模特征与标签之间的关联性,可以有效提高模型对真实标签的学习能力,减少噪声数据对模型性能的负面影响,从而提高偏多标签分类性能。
55、与现有技术相比,本发明的有益效果在于:
56、1、由于在偏多标签学习任务中,核心问题便是利用噪声标签数据进行模型训练,这会导致模型过度拟合这些错误的标签,并且无法正确地捕捉到真实的数据分布和标签之间的关系。本发明通过多策略标签消歧操作,能够排除候选标签集中的噪声标签,计算得到每个样本中较为准确的标签置信度,这样可以提高模型对噪声数据的处理能力,从而增强模型的准确性和可靠性。
57、2、本发明通过计算嵌入网络生成的样本嵌入特征与其各个标签原型之间的相似度,用来纠正噪声标签原型从而完成分类任务,而不是利用传统的二元分类器或者简单的线性变换矩阵进行分类。标签原型可以更好地捕捉样本特征与标签之间的关联性。而本发明中利用标签原型对测试样本进行预测,提供更直观和可解释的结果,这使得模型的预测结果更易于理解和解释。
- 还没有人留言评论。精彩留言会获得点赞!