基于失水量预测的淡水基浆制备方法、系统及钻井液与流程
本发明涉及钻井工程,具体对添加有降滤失剂nh4-pan的淡水基浆作为钻井液的,特别涉及基于失水量预测的淡水基浆制备方法、系统及钻井液。
背景技术:
1、在钻井工程中,钻井液具有冷却钻头、携带岩屑、平衡地层压力以及保护井壁的作用。钻井液的种类繁多,以淡水基浆为例,淡水基浆是一种使用淡水作为连续相(即基础液体)的钻井液。淡水基浆通常适用于那些不需要特别处理的地层,如非黏土性地层或低渗透性地层。
2、水解聚丙烯腈(nh4-pan / na-hpan,商品名普遍称之为水解聚丙烯腈钠盐)是一种经过水解处理的聚丙烯腈产品。nh4-pan是一种呈淡黄色的粉末,易溶于水,其水溶性呈碱性。nh4-pan的聚丙烯腈分子链中引入了羧酸基团(-cooh)等亲水性基团,使其具有良好的水溶性。同时nh4-pan还保留了部分吸附基团,如腈基(-cn)和酰胺基(-conh2),这些基团可以与淡水基浆中的黏土颗粒发生吸附作用,从而起到降滤失和防塌的作用。
3、nh4-pan的降解行为与钻井液的稳定性和性能相辅相成,因此nh4-pan在钻井工程通常作为淡水基浆的降滤失剂,其耐温最高可达250℃,性能稳定,可以有效降低钻井液的滤失量,提高钻井效率。
4、例如,如下现有技术公开了一种高密度钻井液的配制方法,通过水解聚丙烯腈两种沉降稳定性,流动性好且失水量小,粘度和切力适中,具有易于调节和控制等良好特性,能满足高压注水油层的钻井需要:
5、李国璋,陈明林,辜良国,等.高密度钻井液的配制方法[p].cn88100200.3:1989-08-23.
6、又又例如,如下现有技术公开了一种无荧光防塌降滤失剂,通过水解聚丙烯腈实现吸水膨胀,控制失水量,可以提高钻井进度:
7、李振华.石油勘探钻井液用无荧光防塌降滤失剂[p]. cn200710055961.2: 2008-02-06.
8、但是,这些现有技术均是基于nh4-pan按照固定的配比预设配置的降滤失剂或钻井液。正如前文所述的,nh4-pan的降解行为会影响钻井液的稳定性和性能。如果通过测定表观降解活化能,完全可以计算出降滤失剂在不同钻井条件下的降解速率,从而有针对性地调整钻井液的配方,提高其稳定性,延长使用寿命。
9、为此,本发明提出基于失水量预测的淡水基浆制备方法、系统及钻井液。
技术实现思路
1、有鉴于此,本发明希望提供基于失水量预测的淡水基浆制备方法、系统及钻井液,以解决或缓解现有技术中存在的技术问题,即如何在钻井工程作业进行的过程中针对性地调整钻井液的配方,并对此至少提供一种有益的选择。本发明实施例的技术方案是这样实现的:
2、第一方面,基于失水量预测的淡水基浆制备方法:
3、(一)概述:
4、本发明旨在利用动力学处理降滤失剂nh4-pan的一级降解理论模式作为理论基础,通过svr模型描述降滤失量随时间的变化规律。结合svr模型进行预测未来时间点降滤失量fl(t+1)。并通过在当前时间t测得表观降解活化能ea和降滤失量fl,实现对淡水基浆的制备进行实时调整。
5、(二)验证动力学模式可行性:
6、2.1以动力学处理降滤失剂nh4-pan的一级降解的理论模式的可行性:
7、测定水解聚丙烯腈(nh4-pan)作为降滤失剂在特定条件下的表观降解活化能。通过在不同温度下观察nh4-pan在淡水基浆中的降解行为,并利用动力学公式和arrhenius经验公式进行计算,可以得出表观降解活化能ea。
8、以(最好是老化过的)4%的淡水基浆+2.00g nh4-pan的配比制备而成的nh4-pan浆液为例,对于一个化学反应:
9、;
10、其中,a是反应物,b是产物,k是反应速率常数;即:
11、a(反应物):代表的是降滤失剂nh4-pan。在钻井液中,nh4-pan作为添加剂的功能是降低钻井液的滤失量,从而维护井壁稳定。然而在高温条件下,nh4-pan会发生降解反应,导致其分子链断裂、性能下降;
12、b(产物):代表的是nh4-pan降解后的生成物。这些生成物是分子量较小的聚丙烯腈片段、羧酸基团或/和酰胺基团等。随着降解反应的进行,这些生成物会逐渐积累,导致钻井液的滤失量增加、性能变差。
13、其反应速率表达式为:
14、;
15、其中,k为速率常数,n为反应级数;[b’]是反应物a(nh4-pan)的浓度;t是老化时间;负号表示反应物的浓度随时间减少。
16、若降解反应为一级反应,则将反应速率表达式积分得到:
17、inb’=-kt+constant;
18、其中,b’代表的是反应物(nh4-pan)的浓度。这个公式描述了在一级反应中,反应物浓度的自然对数与时间呈线性关系。
19、在降解过程中,随着老化时间的加长,高分子,即作为降滤失剂的nh4-pan的浓度逐渐减少,而降滤失量fl逐渐增大,故降滤失剂的浓度c与降滤失量fl是表观的反比关系,那么由上式进一步整理得:
20、infl=kt+constant;
21、即,降滤失量fl的自然对数与时间也呈线性关系,斜率与反应速率常数k有关。
22、若infl对老化时间t作函数图,速率常数k视为斜率k,然后基于arrhenius经验公式得出:
23、;
24、其中,e是自然常数,t是温度,ea是降滤失剂的表观降解活化能;
25、通过在不同温度(如165℃和180℃)下测定反应速率常数k1、k2,可得出降滤失剂的表观降解活化能ea(kj/mol):
26、;
27、同理,在165℃、180℃下,经实验的nh4-pan在淡水基浆中的降解为简单的一级动力学降解。在两温(165℃、180℃)下的k、t1/2如下表所示:
28、
29、2.2 得到失水方程:
30、综上2.1中所述的失水量与老化时间的关系,说明了用动力学来处理降滤失剂nh4-pan的一级降解的理论模式的指导思想是正确的。但出失水量与时间并非直线关系,从表观上来看为复杂反应中的连续一级降解。按照如下文献给出的经验公式:
31、陈希天等.高铁酸钾水处理剂的制备条件优选及性能测试[j].江汉石油学院学报:1994,16(4):78~82.
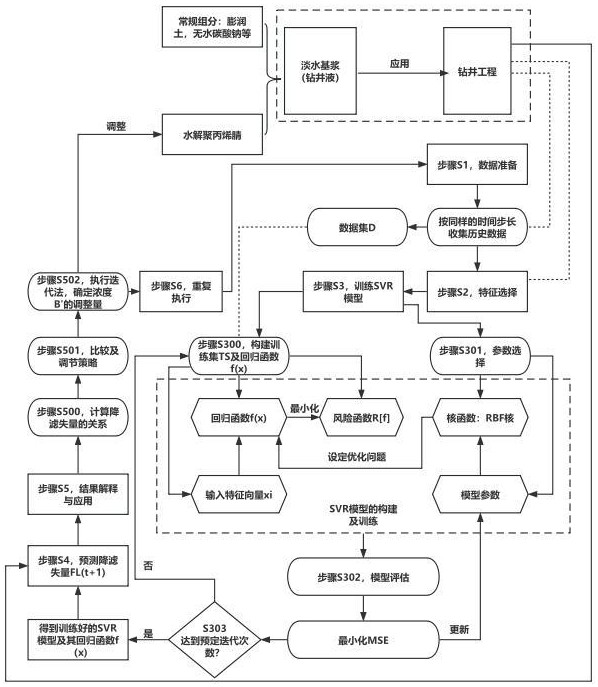
32、得如下关系并继续得出失水方程:
33、;
34、其中,ka是a降解为b的一级反应速率常数。kb是b降解为c的一级反应速率常数。
35、其中,c是最终产物,代表的是nh4-pan经过连续降解后形成的更小分子量的化合物或基团。由于降滤失剂nh4pan的分子链在高温条件下会发生断裂,形成分子量较小的片段,这些片段包括低聚物、单体、羧酸基团和酰胺基团等。
36、出失水方程是:;
37、其中,a和b均是常数,与nh4-pan的(初始)浓度b’和反应条件有关,可以按照如下文献给出的实验数据及其方法测定:
38、王友绍,等.水解聚丙烯腈在钻井液中的热稳定性研究[j].石油与天然气化工:1995,25:91~94.
39、2.3技术脉络:
40、综上,本发明的技术方案的出发点已经明确:当确定了以动力学处理降滤失剂nh4-pan的一级降解的理论模式具备可行性后,利用当前时间t测得的表观降解活化能ea和降滤失量fl,如何预测出下一时间t+1下的降滤失量fl(t+1);工作人员可根据预测信息,提前对nh4-pan的浓度b’进行调整,形成对淡水基浆的制备调控(期间需要保证温度t不变,但是如果变化也可以通过前文的arrhenius经验公式重新拟合出新的表观降解活化能ea,只不过计算资源需求变高)。以实现使用新的淡水基浆时,能够使降滤失量fl(t+1)符合预期工艺需求。
41、(三)技术方案:
42、本发明选择使用支持向量机(svm)预测下一时间t+1下的降滤失量fl(t+1),其原理是基于统计学习理论和结构风险最小化原则。svm模型通过在高维特征空间中寻找最优超平面,以最大化不同类别之间的间隔,从而实现对新数据的预测。
43、将本发明所要解决的技术问题,即预测出下一时间t+1下的降滤失量fl(t+1)视为一种回归问题时,该svm模型的目标是找到一个回归函数,使得该回归函数能够尽可能准确地拟合给定的训练数据,并对fl(t+1)进行预测。因此,本发明的技术方案选择的svm模型实质上属于一种svr模型(support vector regression,支持向量回归)。其步骤包括s1~s5。
44、3.1步骤s1,数据准备:
45、按同样的时间步长收集历史数据,包括时间t、温度t(如果钻井工程中会发生温度变化的话)和钻井工程中的降滤失量fl,构成数据集d:
46、d=[(t1,t1,fl1),(t2,t2,fl2),...,(tn,tn,fln)]
47、其中,(ti,ti,fli)是任意一历史时间ti下的温度ti及降滤失量fli。
48、然后对数据进行预处理,以消除量纲和数量级对模型的影响。
49、3.2步骤s2,特征选择:
50、选择与所要预测的下一时间的降滤失量fl(t+1)相关的特征作为输入变量,输入变量为时间t及温度t。
51、1)只考虑时间对降滤失量的影响时,可以选择时间t作为唯一的输入变量:目标是找到一个函数f,使得:
52、fl(t+1) ≈ f(t)
53、这个函数f就是要通过svr模型来学习的回归函数。在实际应用中不会直接知道这个函数的具体形式,但是svr模型会尝试在高维特征空间中找到一个最优超平面来逼近这个函数。
54、2)如果在后续的钻井作业中,环境温度需要根据工况需求而产生变化,则需要选择时间t及温度t作为输入变量:在这种情况下,回归函数变为:
55、fl(t+1) ≈ f(t, t)
56、同样地,svr会尝试找到一个最优超平面来逼近这个二元形式的回归函数f(t,t);
57、为了便于后文的格式形式统一化,在后文将对回归函数撰写为f(x);
58、对于上述“1)~2)”,需要注意的是,符号“≈”表示并不期望svr能够完美地拟合所有数据点,而是希望它能够在一定程度上泛化到未见过的数据。这是通过结构风险最小化原则来实现的,即在训练误差和模型复杂度之间找到一个平衡。
59、3.3 步骤s3,训练svr模型:
60、svr模型(支持向量回归)是一种基于svm(支持向量机)的回归方法。与svm模型的分类器类似,svr模型会试图在高维空间中找到一个超平面,但应用于本发明中,svr模型是为了最小化预测误差而不是最大化类别间隔。
61、通过数据集d分出训练集ts,基于拟定的svr模型的模型参数及核函数,对svr模型进行训练。
62、3.3.1 步骤s300,构建训练集ts及回归函数f(x):
63、使用数据集d中的输入特征和对应的降滤失量fl作为训练集ts。
64、训练集ts由输入特征和对应的目标输出(降滤失量fl)组成。对于每个时间ti,有一个或多个输入特征(如果考虑温度,则包括相应的时间ti和温度ti)和一个对应的目标输出(降滤失量fli)。
65、训练集ts表示为:ts =[(x1,y1),(x2,y2),...,(xn,yn)];
66、其中,xi是输入特征向量,yi是对应的目标输出(即降滤失量fl)。
67、其中,输入特征向量xi是与降滤失量fli相关的特征组成的向量,包括:
68、1)工况温度不变化时:输入特征向量xi是时间ti;
69、2)工况温度变化时:输入特征向量xi包括时间ti和温度ti。
70、svr模型的目标是学习一个回归函数f(x)(或写作f(xi)),该函数需最小化以下风险函数r[f]:
71、;
72、其中,c是惩罚系数,用于控制模型复杂度和训练误差之间的权衡;w是超平面的法向量;|w|2是正则化项,用于防止过拟合;
73、lε(·)是ε-不敏感损失函数,定义为:
74、;
75、回归函数f(x)为:;
76、其中,φ(x)是将输入特征映射到高维空间的函数,可通过核技巧()隐式定义;b是偏置项;<·,·>表示内积(scalar product)。
77、通过拟定惩罚系数c,并通过二次规划方法优化上述风险函数r[f],可以找到最优的法向量w和偏置项b,从而确定回归函数f(x)。在预测阶段,可以使用这个函数来估计新的、未见过的数据点的降滤失量。
78、3.2.2 步骤s301,参数选择:
79、制定svr模型的核函数及其参数,使用训练集ts训练svr模型。
80、3.2.2.1 步骤s3010,核函数:
81、核函数是rbf核,也称之为径向基函数核(radial basis function, rbfkernel):
82、;
83、其中,xi和xj在本式中视为输入空间中的两个点。γ是rbf核参数,控制了高斯函数的宽度。这个参数影响着数据的映射方式,从而影响了决策边界的形状。是两点间的欧氏距离的平方。
84、rbf核通过在高维空间中对数据进行非线性映射,允许svr拟合复杂的非线性关系。
85、3.2.2.2 步骤s3011,使用训练集ts训练svr模型:
86、svr模型的训练目标是找到一个回归函数f(x)来最小化风险函数r[f]。该函数可以表示为:
87、;
88、其中:αi和αi*是通过训练优化算法找到的拉格朗日乘数;rbf核用于计算输入特征向量xi和x之间的相似性;b是偏置项;n是训练集ts中的样本数量。
89、在训练svr模型时,使用训练集ts来找到最优的拉格朗日乘数αi和αi*和偏置项b,通过设定并解决以下的优化问题:
90、;
91、目标(约束条件)是:
92、;
93、其中,是一个优化问题的表示,意味着要找到一组参数α,α^(拉格朗日乘数)和b(偏置项);
94、其中,是svr模型优化目标中的正则化项。它涉及对所有训练样本对xi和xj的核函数评估的加权和。核函数度量了样本xi和xj之间的相似性。权重是通过优化过程找到的拉格朗日乘数;
95、其中,是svr优化目标中的误差项。是松弛变量,它们允许一些样本不满足ε-不敏感区域的约束,从而增加了模型的灵活性。具体来说,当样本的预测值与实际值之差超过ε时,相应的松弛变量就会大于零,并在目标函数中被惩罚。
96、其中,c是惩罚系数,用于平衡模型复杂度(由法向量w的范数度量)和训练数据上的误差(由松弛变量度量)。
97、其中,是在本式中视为松弛变量,用于处理那些不能被ε-不敏感区域包含的训练样本;c是惩罚系数,用于平衡模型复杂度(由法向量w的范数度量)和训练数据上的误差(由松弛变量度量)。
98、可采用二次规划(quadratic programminh,qp)的方法来解决上述优化问题,以找到最优的svr模型参数。可以使用优化库(如libsvm, scikit-learn等)实现。
99、3.2.3 步骤s302,模型评估:
100、使用留出法评估模型的性能,即计算均方误差mse;
101、在每轮训练迭代中,根据最小化的均方误差mse的结果调整模型参数,以优化svr模型的性能。
102、3.2.3.1 均方误差mse:
103、;
104、其中,ntest是测试集ts中样本的数量。yi是测试集ts中第(i)个样本的真实目标值。是svr模型对测试集ts中第i个样本的预测值。
105、均方误差mse度量了模型预测值与真实值之间的平均平方误差,mse的值越小表示模型的预测性能越好。
106、3.2.3.2 参数调整:
107、调整svr模型的惩罚系数c、rbf核参数γ以及不敏感损失函数的参数ε。参数调整可以通过网格搜索方法进行。
108、在使用网格搜索时,为每个参数设定一个候选值集合,然后遍历所有可能的参数组合来训练模型并计算mse。最终选择使mse最小化的参数组合作为最优参数:
109、;
110、3.2.3 步骤s303,停止训练:
111、继续循环执行步骤s301~s302。当达到预定迭代次数后(需根据实际计算资源来拟定迭代次数),停止迭代。此时的svr模型视为训练完成,并学习到了可以使用的回归函数f(x)。
112、3.3 步骤s4,预测降滤失量fl(t+1):
113、将下一时间t+1作为输入特征输入到训练好的svr模型中。svr模型根据学习到的回归函数f(x)计算预测出对应的降滤失量fl(t+1)。
114、3.3.1准备输入特征:
115、准备下一时间t+1对应的输入特征向量xt+1。这个特征向量包括时间t+1,或时间t+1与下一时间中工况预定变化的温度tt+1。
116、3.3.2应用回归函数:
117、将输入特征向量xt+1代入svr学习到的回归函数f(x)中计算预测值。回归函数的形式为:
118、;
119、然后计算预测值:将xt+1代入回归函数f(x)中,得到预测的降滤失量fl(t+1):
120、;
121、其中,xi是训练集中的输入特征向量;αi和αi*是通过训练优化算法找到的拉格朗日乘数;k(xi, xi+1)是rbf核函数,用于度量输入特征向量xi和输入特征向量xi+1之间的相似性;b是偏置项。
122、最后输出预测结果:将计算得到的降滤失量fl(t+1)作为预测结果输出。
123、3.4步骤s5,结果解释与应用:
124、分析预测的降滤失量fl(t+1),并根据钻井工程的工艺需求进行相应的调整或决策。
125、3.4.1步骤s500,细化nh4-pan浓度与降滤失量的关系:
126、基于出失水方程,得出工艺需求的降滤失量fltarget与nh4-pan的浓度b’之间的关系:
127、;
128、其中,a和b均是常数,与nh4-pan的浓度b’和反应条件有关;e是自然常数。其中,所述的反应条件为:
129、;
130、其中,ka是a降解为b的一级反应速率常数。kb是b降解为c的一级反应速率常数。a、b和c分别是作为降滤失剂的nh4-pan、nh4-pan降解后的生成物和最终产物;
131、3.4.2步骤s501,比较及调节策略:
132、将预测的fl(t+1)与工艺需求的降滤失量fltarget进行比较。如果fl(t+1)与fltarget之间的误差超出预设的误差阈值δ,则需要按照如下策略进行调整:
133、由于常数a和常数b与nh4-pan的初始浓度b'有关,因此可以通过调整b'来改变fl(t+1)的值。具体地:
134、如果fl(t+1) <fltarget,考虑增加nh4-pan的浓度b'以提高降滤失量。
135、如果fl(t+1) >fltarget,考虑减少nh4-pan的浓度b'以降低降滤失量。
136、3.4.3 步骤s502,执行迭代法,确定浓度b'的增加量或减少量:
137、根据经验或先前的数据,设定一个初始的浓度调整量δb′;
138、计算调整后的浓度b′±δb′对应的预测降滤失量fladjusted(即这个浓度下的fl(t+1));
139、比较工艺需求的降滤失量fladjusted与fltarget的差距;
140、如果差距在误差阈值δ以内,则停止迭代,使用当前的浓度b′±δb′;
141、如果差距仍然超出误差阈值δ,则根据差距的大小和方向调整δb′的值,并重复迭代计算。
142、3.4.4 步骤s503,制备新的淡水基浆:
143、基于调整后的浓度b′±δb′的作为降滤失剂的nh4-pan,将原先的淡水基浆中作为降滤失剂的nh4-pan的浓度b′调整为b′±δb′,形成新的淡水基浆并继续应用于当前的钻井工程作业中。
144、3.5 步骤s6,重复执行:
145、在钻井工程作业中,重复执行步骤s4~s5,直至钻井工程作业完成。
146、第二方面,基于失水量预测的淡水基浆制备系统:
147、所述制备系统包括控制器、处理器、与所述处理器耦接的寄存器,所述寄存器中存储有程序指令,所述程序指令被所述处理器执行时,使所述处理器执行如上述所述的制备方法中的步骤s1~s6。
148、其中在一种实施方式中:所述制备系统还包括用于制备淡水基浆的搅拌装置,所述搅拌装置由所述控制器控制;所述搅拌装置用于将nh4-pan及淡水基浆的其它组分混合在一起;所述搅拌装置执行时,实现如上述所述的制备方法中的步骤s5,并制备出所述新的淡水基浆。
149、第三方面,一种钻井液:
150、该所述钻井液为使用上述所述的所述制备系统,通过执行如上述所述的制备方法中的步骤s5所制备出的所述新的淡水基浆。
151、与现有技术相比,本发明的有益效果是:
152、一、预测机制:本发明利用动力学处理降滤失剂nh4-pan的一级降解理论模式,可以描述降滤失量随时间的变化规律。结合svr模型进行预测,能够进一步提高对未来时间点降滤失量fl(t+1)的预测准确性。通过在当前时间t测得表观降解活化能ea和降滤失量fl,本发明的技术方案实现了对钻井液性能的实时监控,有助于及时发现性能偏差并采取相应措施。
153、二、提前调整优化机制:本发明预测出下一时间t+1的降滤失量后,可以在偏差发生之前对淡水基浆中的降滤失剂nh4-pan浓度进行提前调整以实现制备新的、更符合当前工况的淡水基浆。本发明提供的这种预防性调整策略有助于避免钻井作业中因降滤失量不符合要求而导致的停工或安全事故。
154、三、提升作业效率与安全性:本发明通过提前调整降滤失剂浓度,可以确保钻井液在整个作业过程中保持稳定的性能,从而提高钻井作业的效率。同时,这种调整也有助于减少因钻井液性能不稳定而引发的安全风险。
155、四、降低成本与资源浪费:本发明的预测机制及调整机制可以避免因过度添加或不足添加降滤失剂而造成的资源浪费和成本增加。此外,减少不必要的停工和安全事故发生概率也有助于降低钻井作业的总成本。
- 还没有人留言评论。精彩留言会获得点赞!