纸币的识别方法和系统与流程
本发明属于货币识别技术领域,尤其涉及一种纸币的识别方法和系统。
背景技术:
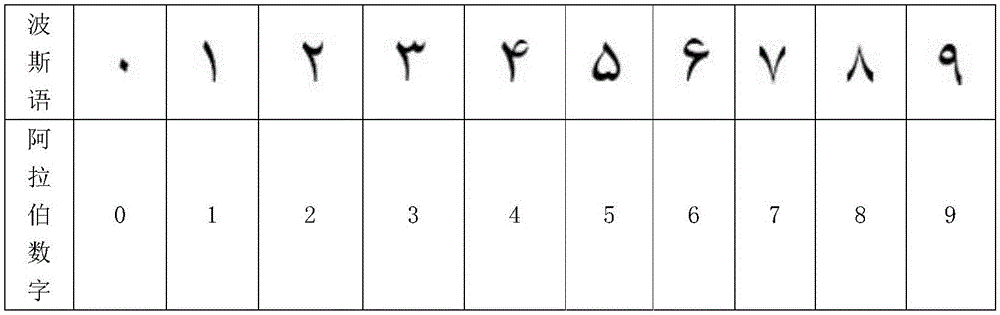
冠字号识别对于纸币的正常流通有着重要的意义,对于冠字号的识别,非常重要的一环就是冠字号的定位与切割。而伊朗币10万里亚尔面值和5万里亚尔面值的冠字号前侧都存在分式,需要特殊处理才能合理的切割出冠字号的分式部分,如图1所示。伊朗使用波斯数字,波斯数字与阿拉伯数字对照表详见图2。现有对带有分式的伊朗币的切割方法难以做到精确,若按照数字字符的切割方法容易出现较大的误差。
上述问题亟待解决。
技术实现要素:
针对现有技术的对带有分式的伊朗币的切割方法难以做到精确,若按照数字字符的切割方法容易出现较大误差的缺陷,本发明实施例提供一种纸币的识别方法和系统。
本发明提供一种纸币的识别方法,包括:
截取伊朗币上覆盖冠字号字符的一固定大小的冠字号区域图;
对所述冠字号区域图进行二值化处理,获取所述冠字号区域图的二值化区域图;
通过预设大小尺寸的窗口竖直扫描所述二值化区域图,识别所述二值化区域图中字符的上切线和下切线;
通过双模版匹配算法识别出所述二值化区域图中各个冠字号字符间的列切线;
根据所述上切线、下切线和所述列切线定位出所述伊朗币中各冠字号字符的位置。
优选的,所述截取伊朗币上覆盖冠字号字符的一固定大小的冠字号区域图之前包括:
校正所述伊朗币的放置方向,将伊朗币上冠字号区域的分式排列到字符左侧。
优选的,所述通过预设大小尺寸的窗口竖直扫描所述二值化区域图,识别所述二值化区域图中字符的上切线和下切线具体包括:
通过预设尺寸大小窗口圈定所述二值化区域图的倒数第二行起始行START行内的白色像素点,并将所述白色像素点的总数SUM赋予初始值为0的MAX;
窗口向上扫描一行,将SUM减去上一窗口最后一行的白色像素点数,加上现在窗口所在的起始行的白色像素点数得到当前窗口内白素像素点的总数SUM;若当前SUM大于MAX,则把当前SUM赋予MAX,当前窗口起始行的行号赋予起始行START;
重复窗口向上扫描一行的动作,直至窗口向上扫描到窗口的起始行到达冠字号的高度值为止;
输出结束行的行号,结束行=START+冠字号高度。
优选的,所述双模版具体包括:
第一模板{0,50,74,98,122,146,170,194},用于切割冠字号的分式长度为50像素的二值化区域图;
第二模板{0,45,73,93,115,137,159,181},用于切割冠字号的分式长度为45像素的二值化区域图。
优选的,所述通过双模版匹配算法识别所述二值化区域图中各个字符间的列切线具体包括:
统计二值化区域图所在的左起第1列至第8列上的列切线分数:列切线分数=白点数*列切线穿越白点数的次数,将各个列的列切线分数相加得到列切线总分赋予SUM1,记录起始列第一列的坐标赋予START1;
将起始列向右移一位,计算当前从起始列起向右8列的列切线总分SUM2,若SUM2<SUM1,则将SUM2的值赋予SUM1,且当前起始列的坐标赋予START1;
重复将起始列向右移一位的动作,直至起始列到达分式的第四十列为止,返回此时的起始列坐标START1;
计算通过第一模板START1+50列上的列切线分数ROW1;计算通过第二模板START1+45列上的列切线分数ROW2;若ROW1>ROW2,则识别二值化区域图中各个字符间的列切线采用第二模板,反之,则识别二值化区域图中各个字符间的列切线采用第一模板。
本发明还一种纸币的识别系统,包括:
截取模块,截取伊朗币上覆盖冠字号字符的一固定大小的冠字号区域图;
调整模块,用于对所述冠字号区域图进行二值化处理,获取所述冠字号区域图的二值化区域图;
扫描模块,用于通过预设大小尺寸的窗口竖直扫描所述二值化区域图,识别所述二值化区域图中字符的上切线和下切线;
匹配模块,用于通过双模版匹配算法识别出所述二值化区域图中各个冠字号字符间的列切线;
定位模块,用于根据所述上切线、下切线和所述列切线定位出所述伊朗币中各冠字号字符的位置。
优选的,所述系统还包括:
校正模块,用于校正所述伊朗币的放置方向,用于将伊朗币上冠字号区域的分式排列到字符左侧。
优选的,所述扫描模块具体包括:
圈定单元,用于通过预设尺寸大小窗口圈定所述二值化区域图的倒数第二行起始行START行内的白色像素点,并将所述白色像素点的总数SUM赋予初始值为0的MAX;
向上扫描单元,用于窗口向上扫描一行,将SUM减去上一窗口最后一行的白色像素点数,加上现在窗口所在的起始行的白色像素点数得到当前窗口内白素像素点的总数SUM;若当前SUM大于MAX,则把当前SUM赋予MAX,当前窗口起始行的行号赋予起始行START;
第一重复单元,用于重复窗口向上扫描一行的动作,直至窗口向上扫描到窗口的起始行到达冠字号的高度值为止;
输出单元,用于输出结束行的行号,结束行=START+冠字号高度。
优选的,所述双模版具体包括:
第一模板{0,50,74,98,122,146,170,194},用于切割冠字号的分式长度为50像素的二值化区域图;
第二模板{0,45,73,93,115,137,159,181},用于切割冠字号的分式长度为45像素的二值化区域图。
优选的,所述匹配模块具体包括:
统计单元,用于统计二值化区域图所在的左起第1列至第8列上的列切线分数:列切线分数=白点数*列切线穿越白点数的次数,将各个列的列切线分数相加得到列切线总分赋予SUM1,记录起始列第一列的坐标赋予START1;
计算单元,用于将起始列向右移一位,计算当前从起始列起向右8列的列切线总分SUM2,若SUM2<SUM1,则将SUM2的值赋予SUM1,且当前起始列的坐标赋予START1;
重复单元,用于重复将起始列向右移一位的动作,直至起始列到达分式的第四十列为止,返回此时的起始列坐标START1;
采用单元,用于计算通过第一模板START1+50列上的列切线分数ROW1;计算通过第二模板START1+45列上的列切线分数ROW2;若ROW1>ROW2,则识别二值化区域图中各个字符间的列切线采用第二模板,反之,则识别二值化区域图中各个字符间的列切线采用第一模板。
有益效果:本发明提供的纸币的识别方法和系统,通过窗口扫描分别找到冠字号的行切线和列切线,扫描时只涉及加法和减法,精确又快速,极大降低了识别误差率,可拓展性强;通过双模板匹配列切线使得列切线的定位更合理、稳定,为后续步骤的识别提供了良好的单个数字图像数据。
附图说明
图1为伊朗币10万里亚尔面值和5万里亚尔面值的货币图;
图2为波斯数字与阿拉伯数字对照表;
图3为本发明实施例提供的纸币的识别方法步骤图;
图4为本发明另一实施例提供的将截取的冠字号区域图进行二值化处理后的效果图;
图5为本发明另一实施例提供的纸币的识别方法步骤图;
图6为本发明另一实施例提供的纸币的识别方法中从二值图的倒数第二行开始统计示意图;
图7为图6中提供的纸币的识别方法中窗口开始往上扫描示意图;
图8为本发明另一实施例提供的上切线行和下切线行对带有分式冠字号横向切割结果图;
图9为本发明另一实施例提供的切线画在阿拉伯数字6中间形成6次穿越次数的效果图;
图10为本发明另一实施例提供的纸币的识别方法的切割结果图;
图11为本发明实施例提供的纸币的识别系统结构图;
图12为本发明另一实施例提供的纸币的识别系统结构图;
图13为本发明另一实施例提供的纸币的识别系统中扫描模块的组成结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种纸币的识别方法,如图3所示,包括:
S100、通过RGB传感器截取伊朗币上覆盖冠字号字符的一固定大小的冠字号区域图;
具体的,在纵向150DPI,横向200DPI分辨率下的RGB传感器下截取一块冠字号区域,尺寸为230*80。
200DPI即一英寸有200个像素点。200/25.4=230/宽,计算出宽=29.21mm。
150DPI即一英寸有150个像素点。150/25.4=80/高,计算出高=13.55mm。
S200、通过直方图调整所述冠字号区域图得到二值化区域图;
具体的,将截取的冠字号区域图进行二值化处理包括,如图4所示,:通过直方图拉伸,可设大于等于127为白色,小于127则为黑色。
S300、通过固定大小的窗口竖直扫描所述二值化区域图,识别所述二值化区域图中字符的上切线行和下切线行;
S400、通过双模版匹配所述二值化区域图,识别所述二值化区域图中各个字符间的列切线;
S500、根据所述上切线、下切线和所述列切线定位出所述伊朗币中各冠字号字符的位置。
优选的,如图5所示,所述通过RGB传感器截取伊朗币上覆盖冠字号字符的一固定大小的冠字号区域图之前包括:
S500、校正所述伊朗币的放置方向,用于将伊朗币上冠字号区域的分式排列到字符左侧。
优选的,所述通过固定长宽的窗口竖直扫描所述二值化区域图,识别所述二值化区域图中字符的上切线行和下切线行具体包括:
S301、通过23像素*二值化区域图长度的窗口圈定所述二值化区域图的倒数第二行起始行START行内的白色像素点,并将所述白色像素点的总数SUM赋予初始值为0的MAX;
具体的,根据统计,伊朗币10万里亚尔,5万里亚尔面值的单个字符高度为23个像素,使用窗口23*230大小的窗口扫描二值图中最多白点的起始行和结束行,找到合适的上下切线。
如图6所示,从二值图的倒数第二行开始统计,统计36~59行的白色像素点个数,统计的个数记SUM,若SUM大于MAX,则把SUM的值赋给MAX(MAX初始化为0)且记起始行坐标START为36。
S302、窗口向上扫描一行,将SUM减去上一窗口最后一行的白色像素点数,加上现在窗口所在的起始行的白色像素点数得到当前窗口内白素像素点的总数SUM;若当前SUM大于MAX,则把当前SUM赋予MAX,当前窗口起始行的行号赋予起始行START;
如图7所示,窗口开始往上扫描,SUM减去59行白色像素点个数,加上35行白色像素点个数。即窗口向上平移一行,计算SUM,且与MAX比较,若SUM大于MAX则把SUM赋予MAX且更新起始行坐标START为35。
S303、重复S302步的动作,直至窗口向上扫描到窗口的起始行到达冠字号的高度值为止;
具体的,在窗口上边界值到达冠字号高度值(此例子中为23)为止。
S304、输出结束行的行号,结束行=START+冠字号高度。
具体的,经过上切线行和下切线行对带有分式冠字号横向切割结果图,如图8所示。
优选的,所述双模版具体包括:
第一模板{0,50,74,98,122,146,170,194},用于切割冠字号的分式长度为50像素的二值化区域图;
第二模板{0,45,73,93,115,137,159,181},用于切割冠字号的分式长度为45像素的二值化区域图。
具体的,目前使用的伊朗币5万列切线版模板为:
{0,50,74,98,122,146,170,194},5万/10万左右冠字号波斯数字分式第一模板(7位,宽50像素的分式算1位)
{0,45,73,93,115,137,159,181},5万/10万左右冠字号波斯数字分式第二模板(7位,宽45像素的分式算1位)
选用二个模板的原因是第一位(整个分式当做第一位)的分数线宽度的波动为48~52像素。若选用50宽度的模板,在遇到第一位宽度为40的冠字号做列切割时会出现偏差;同样选用40宽度的模板在遇到第一位宽度为50的冠字号,列切割将会失败。
优选的,所述通过双模版匹配所述二值化区域图,识别所述二值化区域图中各个字符间的列切线之前还包括:
S600、统计二值化区域图所在的左起第1列至第8列上的列切线分数:列切线分数=白点数*列切线穿越白点数的次数,将各个列的列切线分数相加得到列切线总分赋予SUM1,记录起始列第一列的坐标赋予START1;
S700、将起始列向右移一位,计算当前从起始列起向右8列的列切线总分SUM2,若SUM2<SUM1,则将SUM2的值赋予SUM1,且当前起始列的坐标赋予START1;
S800、重复S600步的动作,直至起始列到达分式的第四十列为止,返回此时的起始列坐标START1;
S900、计算通过第一模板START1+50列上的列切线分数ROW1;
计算通过第二模板START1+45列上的列切线分数ROW2;
若ROW1>ROW2,则识别二值化区域图中各个字符间的列切线采用第二模板,反之,则识别二值化区域图中各个字符间的列切线采用第一模板。
进一步的,在找带有分式的冠字号的起始列切割坐标时,找到合适的起始列的条件为:
第一位满足:1.第一位之间的连续列投影为0列不能大于20列;
2.第一位的像素点大于20。
满足以上两个条件时,认为找到合适的列切割起始列。此时计算列切割质量的得分。再进一步的,计算列切割质量得分的方法:
从模板的第0列开始,统计八个模板列坐标上白点的个数与切线穿越白点次数。白点数*切线穿越白点次数=切线的分数,八个列坐标切线的切线分数之和记为总分。如图9所示,以阿拉伯数字6为例,切线若画在数字6中间则形成6次穿越次数。
从截取图的最左侧0列开始统计到40列,返回找到总分最小的模板起始列坐标。具体的,因伊朗币印刷条件较差,冠字号的左右动荡较大,故起始点为0行,往后扫描40列;以查找最小值的模板计算得分。
首先使用第一模板(分式宽50)模板计算得分,若得分为0.则直接使用第一模板,若大于0.则使用第二模板(分式宽45)计算得分,最后比较第一模板和第二模板的得分。使用得分较小的模板中的列切线坐标作为识别所述二值化区域图中各个字符间的列切线,最终切割结果如图10所示。
本发明实施例提供的纸币的识别方法,通过窗口扫描分别找到冠字号的行切线和列切线,扫描时只涉及加法和减法,精确又快速,极大降低了识别误差率,可拓展性强;通过双模板匹配列切线使得列切线的定位更合理、稳定,为后续步骤的识别提供了良好的单个数字图像数据。
本发明还提供一种纸币的识别系统,如图11所示,包括:
截取模块100,用于通过RGB传感器截取伊朗币上覆盖冠字号字符的一固定大小的冠字号区域图;
调整模块200,用于通过直方图调整所述冠字号区域图得到二值化区域图;
扫描模块300,用于通过固定大小的窗口竖直扫描所述二值化区域图,识别所述二值化区域图中字符的上切线行和下切线行;
匹配模块400,用于通过双模版匹配所述二值化区域图,识别所述二值化区域图中各个字符间的列切线;
定位模块500,用于根据所述上切线、下切线和所述列切线定位出所述伊朗币中各冠字号字符的位置。
优选的,如图12所示,所述系统还包括:
校正模块600,用于校正所述伊朗币的放置方向,用于将伊朗币上冠字号区域的分式排列到字符左侧。
优选的,如图13所示,所述扫描模块300具体包括:
圈定单元301,用于通过23像素*二值化区域图长度的窗口圈定所述二值化区域图的倒数第二行起始行START行内的白色像素点,并将所述白色像素点的总数SUM赋予初始值为0的MAX;
向上扫描单元302,用于窗口向上扫描一行,将SUM减去上一窗口最后一行的白色像素点数,加上现在窗口所在的起始行的白色像素点数得到当前窗口内白素像素点的总数SUM;若当前SUM大于MAX,则把当前SUM赋予MAX,当前窗口起始行的行号赋予起始行START;
第一重复单元303,用于重复窗口向上扫描一行的动作,直至窗口向上扫描到窗口的起始行到达冠字号的高度值为止;
输出单元304,用于输出结束行的行号,结束行=START+冠字号高度。
优选的,所述双模版具体包括:
第一模板{0,50,74,98,122,146,170,194},用于切割冠字号的分式长度为50像素的二值化区域图;
第二模板{0,45,73,93,115,137,159,181},用于切割冠字号的分式长度为45像素的二值化区域图。
优选的,所述系统还包括:
统计模块,用于统计二值化区域图所在的左起第1列至第8列上的列切线分数:列切线分数=白点数*列切线穿越白点数的次数,将各个列的列切线分数相加得到列切线总分赋予SUM1,记录起始列第一列的坐标赋予START1;
计算模块,用于将起始列向右移一位,计算当前从起始列起向右8列的列切线总分SUM2,若SUM2<SUM1,则将SUM2的值赋予SUM1,且当前起始列的坐标赋予START1;
重复模块,用于重复将起始列向右移一位的动作,直至起始列到达分式的第四十列为止,返回此时的起始列坐标START1;
采用模块,用于计算通过第一模板START1+50列上的列切线分数ROW1;计算通过第二模板START1+45列上的列切线分数ROW2;若ROW1>ROW2,则识别二值化区域图中各个字符间的列切线采用第二模板,反之,则识别二值化区域图中各个字符间的列切线采用第一模板。
需要说明的是,本发明实施例提供的上述系统中各个模块,由于与本发明方法实施例基于同一构思,其带来的技术效果与本发明方法实施例相同,具体内容可参见本发明方法实施例中的叙述,此处不再赘述。
本发明实施例提供的纸币的识别系统,通过窗口扫描分别找到冠字号的行切线和列切线,扫描时只涉及加法和减法,精确又快速,极大降低了识别误差率,可拓展性强;通过双模板匹配列切线使得列切线的定位更合理、稳定,为后续步骤的识别提供了良好的单个数字图像数据。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!