一种基于多源数据融合的城市道路流量预测方法与流程
本发明涉及一种基于多源数据融合的城市道路流量预测方法。
背景技术:
道路交叉路口和道路断面流量是城市交通状况的重要组成部分,准确、合理地进行交通状况预测是进行交通控制和交通流诱导的基础。传统的城市道路交通断面流量获取方法有三种,第一也是通常的做法是通过人口调查方法获取,这不仅耗费大量的人力物力资源,而且调查周期长,这些原因导致人群分布感知的结果缺少时效性。第二是利用环形线圈检测器、视频车辆检测器等硬件设备,采用识别视频或圧感检测道路断面流量。第三是通过城市短时交通流量预测来获取城市交通流量;现行的预测方法有卡尔曼滤波预测、时间序列预测等,通过建立道路交通流模型进行预测,其中不乏一些模型应用到了城市道路的实时预测。众所周知,一份全面、准确、合理、实时的交通流量是实际应用智能交通的基础,但经分析,上述获取道路段断面流量的方法仍然存在下列缺点:
1)大面积覆盖仍然仍需投入较大的成本;
2)受限于检测地的实际状况以及硬件设置问题,检测中存在异常信息;
3)方法和模型涉及到大量的向量计算,算法复杂,计算量过大。
综上所述,目前的道路流量预测方法仍然存在不足,或调查覆盖面过少,难以获得实时信息;或预测方法技术较复杂,实施难度较高,模型计算量大,难以大面积应用到实际交通。由此可见,提供一种高效、经济的方法对交通流量进行科学合理地预测,对于智能交通系统中交通规划、交通诱导、交通管理、交通控制与安全都具有重要意义。
技术实现要素:
本发明所解决的技术问题是,针对现有技术的不足,提出一种基于多源数据融合的城市道路流量预测方法,通过融合手机信令数据和卡口数据建立动态预测模型,预测城市道路断面流量,数据获取便利,成本低,实施简单,便于在多个城市开展流量预测工作。
一种基于多源数据融合的城市道路流量预测方法,包括以下步骤:
步骤一:基于手机信令数据提取常驻居民的出行od,每个出行od为一个二维向量,其第1个分量为出行的起始节点,第2个分量为出行的终止节点;将出行od分配至城市路网上,得到路段的分配流量;
步骤二:基于卡口记录区分常用车与非常用车,提取常用车与非常用车流量,得到卡口对应路段的总观测流量与常用车观测流量;
步骤三:选取区域内具有观测流量的路段,根据其分配流量与观测流量,建立表征该区域内路段的分配流量与观测流量的时变相关关系的线性回归方程;
步骤四:根据线性回归方程及区域内常用车占比建立该区域内路段流量的动态预测模型,用于预测该区域内不具有观测流量的路段的流量;所述常用车占比为区域内被卡口记录的常用车观测流量占总观测流量的比例;
步骤五:对该区域内不具有观测流量的路段,将其分配流量输入动态预测模型,预测其时变的流量。
进一步地,在所述的步骤一中,对手机信令数据进行基于稳定点的住址小区判断,进而判断用户是否为常驻居民;具体步骤如下:
1.1)对手机信令数据进行处理,统计用户各个时段在各个位置的累计停留时间;
1.2)获取用户夜晚时段累计停留时间t最长的位置,判断t是否超过最低阈值,若超过,则判定该位置所处小区为用户的住址小区,该用户为常驻居民;否则,判定该用户不是常驻居民。
本发明将用户累计停留时间超过一定阈值的位置作为稳定点;将用户夜晚时段累计停留时间t最长且超过最低阈值的稳定点作为住址小区;最后以用户是否具有住址小区为依据判断用户是否为常驻居民。
进一步地,在所述的步骤1.1)中,对手机信令数据进行处理包括清洗掉其中包含的异常数据;异常数据包括两种,一种是缺少了基站编号的手机信令数据;另一种是缺少了时间记录或其记录的时间与实际时间不符的手机信令数据。
进一步地,在所述的步骤一中,基于手机信令数据提取常驻居民的出行od,得到路段的分配流量,具体包括以下步骤:
2.1)根据基站记录的常驻居民的手机信令数据确定常驻居民的出行轨迹,并判断其停留位置,基于停留位置将其出行轨迹将划分成连续的od,得到基站od;
2.2)根据基站和城市路网中路段节点的对应关系,将基站od转化成路段节点od,生成代表出行需求的od矩阵表;
2.3)使用增量分配法将生成的od矩阵表分配至城市路网上,得到路段的分配流量。
进一步地,所述步骤2.1)中,设连续记录6次记录一个用户数据的基站所在的位置为该用户的停留位置,设用户第i和i+1个停留位置分别为
进一步地,在所述的步骤二中,将卡口在多天同一个时段记录的流量用dbscan聚类算法进行聚类,以剔除流量中的异常值;聚类后得到的最大团簇中包含的点,即流量视为正常值,其余团簇内包含的点视为异常值;此外,若最大团簇中包含的点的个数小于记录流量的天数的50%,则认为卡口设备出现问题,去除该卡口设备记录的流量。
进一步地,在所述的步骤二中,根据多天的卡口记录数据将车辆分为常用车和非常用车,统计卡口记录的流量,根据卡口位置匹配各卡口对应的路段,卡口记录的流量即为其对应路段的总观测流量。
进一步地,在所述的步骤三中,线性回归方程为:
其中,ui及
由线性回归方程确定区域内路段的分配流量与该路段的常用车观测流量之间的时变关系。
进一步地,在所述的步骤四中,区域内路段流量的动态预测模型为:
fj=(β0+β1u′j+ε)/λo
其中,fj表示该区域内不具有观测流量的路段j的预测流量,u′j表示路段j的分配流量;
有益效果:
近年来,手机在全球范围已经得到迅速且相当程度的普及,覆盖范围的迅速增长,带来了海量的手机信令数据信息。各地对于基础建设的投入,也能产生一定数量的卡口数据。这两种数据在大多数城市都很容易获得。同时随着数据越来越在决策中发挥重要的作用,计算机技术也在迅速发展,使储存与计算成本下降,快速处理大量的信息数据也成为了可能。这些均给数据应用在智能交通系统(its)中提供了新方法新思路。手机一直伴随用户移动,其信令数据完整的记录了用户的出行轨迹,成为分析城市人口活动规律,进行路段状态检测的最理想的数据。然而手机信令事件随机发生,且移动网络的扫描周期通常为半小时,用户的出行位置与其手机信令事件之间没有必然关系,这种情况导致手机信令数据只能在一定程度上代表路段状况变化,而卡口观测流量作为路段流量的高精度采样能够校核分配流量。本发明通过融合这两种数据特征,获取了动态的预测模型。相比于直接检测与短时交通流量预测,基于数据融合的预测方法不仅数据获取便利,实施简单,成本低,更有覆盖面广,计算复杂度低的优点。而且随着这两种数据的获取越来越便利,该方法更能大面积地应用于多个城市;且手机数据量大,能够模型城市内部的出行需求,卡口记录的实效性强,能够动态的预测城市道路断面流量,这对智能交通系统中的交通控制、交通流诱导、交通管理、交通控制与安全都具有重要意义。
附图说明
图1为本发明流程示意图;
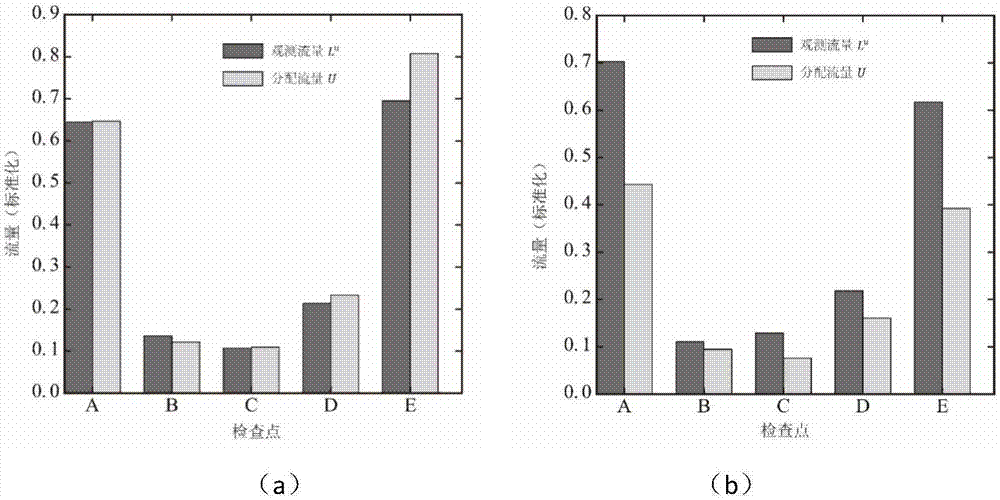
图2为本发明实施例中,龙华地区不同时段的分配流量与常用车观测流量的对应关系;图2(a)为早高峰时段(8:30)区域内不同路段(检查点)分配流量与常用车观测流量对比;图2(b)为晚高峰时段(20:30),区域内不同路段分配流量与常用车观测流量对比;
图3为本发明实施例中,龙华地区不同时段的分配流量与常用车观测流量的拟合关系;图3(a)为早高峰时段(8:30)分配流量u与观测流量lu之间的关系;图3(b)为晚高峰时段(20:30)分配流量u与观测流量lu之间的关系;
图3为本发明实施例中,龙华地区路段的不同时段的预测流量分布;图4(a)为早高峰时段(8:30)的预测流量分布图;图4(b)为晚高峰时段(20:30)的预测流量分布图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细描述,但不作为对本发明的限定。
下文使用的手机信令数据和卡口数据来自中国深圳2012年某日00:05至23:35,共587,286,499条信令数据;卡口数据的时间为2016.08.15-.08.28,共14天数据。本发明具体实施包括以下步骤。
步骤一:处理手机信令数据,清洗其中的异常数据,其中数据的有效率为95.319%,共记录了16,300,083个用户在5952个基站的手机记录。
步骤1:考虑绝大多数用户的生活习性,选取夜晚时段(00:00-6:00)与白天时段(7:00-22:00)各取一个累计停留时间最长且超过最低阈值(2h)的稳定点作为夜间稳定点与白天稳定点。以稳定点为主要依据,综合判断用户的居住地与工作地。其中拥有居住地的用户作为深圳常住人口,根据深圳市2013年人口普查:常驻人口1062.89万,从手机中挖掘的居民用户为879.94,与人口普查结果一致。
步骤2:将出行轨迹划分成连续的出行,由于为用户提供服务的基站位置可能不断变化,产生所谓的“乒乓效应”(在用户的位置不发生变化时,由于基站负载均衡等问题,其为用户提供服务的基站位置来回变化;或者用户在距离两个基站的位置距离相差不大的情况下,为用户提供服务的基站位置来回变化)。若直接采用为用户提供服务的基站位置变化作为用户位置的变化,容易受到乒乓现象的干扰从而产生大量的错误od数据,因此需要对这种情况进行排除,避免产生额外的出行。通过设立以下原则,排除乒乓现象产生的错误od数据:设连续记录6次记录一个用户数据的基站所在的位置为该用户的停留位置,设用户第i个停留位置为
步骤3:从手机信令数据中提取的od数据分成4份,循环分配每一份od数据到深圳路网中;每次循环时,首先按最新的路阻重新计算最短路径,然后分配一份od数据到相应的最短路径上;再按bpr路阻函数
步骤二:对卡口记录数据进行统计,14天内,一共检测到528,7649辆(2015年深圳市机动车保有量320万)。统计528万辆车的出现天数,记出现2天及其以上车辆为常用车辆,共287万,2015年深圳市机动车保有量320万。手动匹配卡口与其记录的路段,统计与路段相对应的卡口记录,作为该路段断面的总观测流量
将各卡口在多天同一个时段记录的流量分别用dbscan聚类算法进行聚类,以去除异常值;聚类后得到的最大团簇中包含的点,即流量视为正常值,其余团簇内包含的点视为异常值;此外,若最大团簇中包含的点的个数小于记录数据的天数的50%,则认为卡口设备出现问题,去除该卡口设备记录的流量数据。
dbscan聚类算法所需主要的主要参数有两个:一个参数是半径(eps),表示以给定点p(在本发明中,p表示流量)为中心的圆形邻域的范围;另一个参数是以点p为中心的圆形邻域内最少点的数量(minpts)。如果满足:以点p为中心、半径为eps的邻域内的点的个数不少于minpts,则称点p为核心点。
将卡口在多天同一个时段记录的流量数据记为数据集p={p(i);i=1,…n},其中p(i)表示该卡口在第i天该时段的流量;对于每一个点p(i),计算点p(i)到集合p的子集s={p(1),p(2),…,p(i-1),p(i+1),…,p(n)}中所有点之间的距离,距离按照从小到大的顺序排序,得到排序后的距离集合为d={d(1),d(2),…,d(k-1),d(k),d(k+1),…,d(n)},其中d(k)称为k-距离(k-距离是点p(i)到除了p(i)点以外的所有点之间距离第k近的距离);
根据经验确定k-距离中k的值,从而确定最少点的数量minpts;本实施例中取k=4,则minpts=4;
对待聚类集合中每个点p(i)都计算k-距离,最后得到所有点的k-距离集合e={e(1),e(2),…,e(n)}。
根据得到的所有点的k-距离集合e,对集合e进行升序排序后得到k-距离集合e’,拟合一条e’集合中k-距离的变化曲线图,变化曲线图中,x轴坐标点直接使用递增的自然数序列,每个点对应一个自然数,y轴坐标点为e’集合中k-距离;选用变化曲线图中的最速递增点作为流量半径eps,斜率最大的两点的对应的k-距离的平均即为最速递增点;
根据给定minpts的值,以及半径eps的值,计算所有核心点;
根据得到的核心点集合,以及半径eps的值,计算能够连通的核心点;
将能够连通的每一组核心点,以及到核心点距离小于半径eps的点,都放到一起,形成一个簇;由此聚类得到一组簇;
本发明利用该种基于密度的异常值检测方法,能够有效的抵抗异常值(“噪声”)的干扰。本实施例中,得到卡口记录数据的有效率为72%。
步骤三:对同一区域内路段估计流量与观测流量的动态关系进行计算。根据上述步骤对手机信令数据和卡口记录数据的处理,可以由常驻居民的手机信令数据得到深圳市路段分配流量,以及深圳市卡口记录的对应路段的总观测流量以及其中的常用车观测流量,设表征区域内路段的分配流量及常用车观测流量间的时变关系的线性回归方程为:
其中,ui及
选取了深圳龙华地区进行说明,区域内包含了5个卡口。图2显示了该区域内的分配流量与常用车观测流量的对应关系。图2(a)的时间为8:30,图2(b)的时间为20:30,表征不同路段状态下(早高峰与晚高峰)两种流量的对应关系。可以看到,尽管两个时间段的具有不同的路段特征,但对于相同时段,不同路段的分配流量与常用车观测流量均表现出相同的变化趋势。在此基础上对两种流量做拟合,其常用车观测流量与分配流量的一致性很高,图3表示了同一时段龙华地区二者的拟合关系。
步骤四:根据上一步骤得到的线性回归方程,对不具有观测流量的城市道路路段,利用分配流量进行估计,同时考虑区域内常用车占比对结果造成的影响。使用
fj=(β0+β1u′j+ε)/λo
采用线性回归的拟合最优参数。以上步骤选取区域得为例,其最优参数分别为,图2(a),即8:30的最优拟合值为β0=0.211,β1=61.221,λo=0.983;图2(b),即20:30的最优拟合值为β0=0.383,β1=-66.076,λo=0.971,计算了区域内的路段断面流量。最终的路段断面预测流量分布如下图4所示,其中图4(a)为早高峰时段(8:30),图4(b)为晚高峰时段(20:30)。其中龙华区的几条快速路在早晚高峰的预测流量明显大于其他路段。同时,以留仙大道为例(放大部分),发现早高峰流量的主要趋势为由东向西,而晚高峰的流量趋势于早高峰相反,说明本发明的预测方法的预测流量能够明显的体现出早晚高峰交通流的通勤特性。
不同于传统的调查方式及短时交通流量方式,尽管分配流量难以代表真实流量,但同一时间段内的用户出行量是一个区域内实际出行的无偏估计。而进行异常点检测后的卡口数据是区域路段实际流量的抽样。通过提取常用人口和常用车辆,采用线性回归的拟合最优参数,得到区域性的动态预测模型,准确、合理的对城市交通流量对进行预测,这对智能交通中交通规划、交通诱导、交通管理、交通控制与安全等都具有非常重要的意义。
- 还没有人留言评论。精彩留言会获得点赞!