基于层次聚类的路口异常车辆轨迹识别分析方法与流程
本发明涉及交通管控领域中的车辆轨迹识别领域和路口合理性分析领域,具体涉及一种基于层次聚类的路口异常车辆轨迹识别分析方法。
背景技术:
随着机动车数据的集聚增长,全国各城市都面临着日益严峻的交通拥堵问题,因此,对车辆轨迹的研究对于交通管理与疏导是十分必要的。迄今为止,已经有较多的学者对车辆轨迹相似性及异常轨迹进行了一定研究,如裴剑(裴剑,彭敦陆.一种基于lcss的相似车辆轨迹查询方法[j].2016)在采集大量车辆行驶gps数据基础上,基于数据清理形成轨迹,通过ramer-douglas-peucker算法对原始轨迹轮廓抽取,基于lcss算法求相似子轨迹。
另一方面,现阶段城市道路上布设有大量的电警、卡口、球机等监控摄像头,产生了巨大的结构化数据,而将这些数据运用实现车辆轨迹分析更成了目前研究的主流之一。如发明cn201710492719.5提出一种车辆非有效行驶轨迹识别方法,通过对车辆轨迹的识别的层次聚类,实现最优路径推荐,针对停车问题进行轨迹路径规划;发明cn201510159009.1提出一种基于广域分布交通系统的异常轨迹检测方法,通过无监督聚类确定异常交通轨迹点和异常轨迹。
现阶段的车辆轨迹分析研究主要集中在两个方面,一是基于gps定位数据/手机移动通信数据等位置数据实现的单一车辆轨迹分析;二是对整个路网,长距离车辆行驶异常轨迹的判定,目前暂缺对路口车辆轨迹的有效分类和判别,以及车辆轨迹的路口交通管理运用。
技术实现要素:
本发明提出一种基于层次聚类的路口异常车辆轨迹识别分析方法,对路口球机监控设备历史视频数据进行提取,利用lcss算法、dtw算法和层次聚类算法实现车辆轨迹聚类分析,基于路口渠化信息划分车辆轨迹模式,识别出路口异常车辆轨迹,进而分别对各模式下车辆轨迹再次聚类分析,精细化识别各流向异常车辆轨迹,分析异常原因,从而建立异常轨迹数据库,为路口渠化设计和信控方案合理性评估提供支撑依据。
基于层次聚类的路口异常车辆轨迹识别分析方法,包括如下步骤:
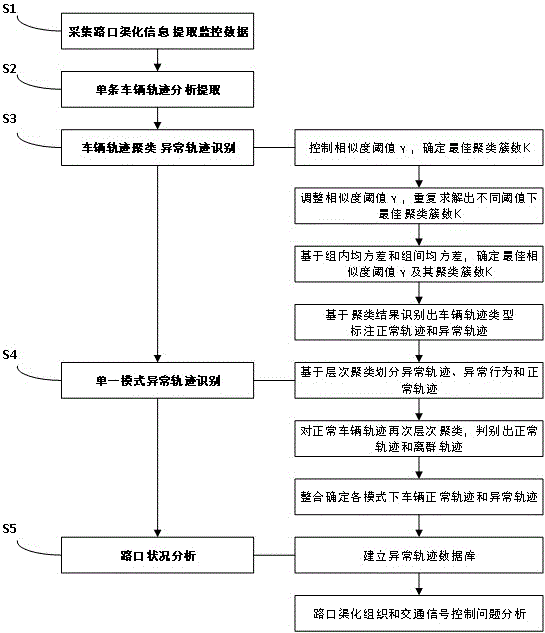
步骤1,采集路口渠化信息,提取路口监控视频数据完成数据清洗;
步骤2,针对不同车辆id实现单条轨迹分析,提取数据特征点,确定车辆轨迹;
步骤3,基于lcss算法和层次聚类算法实现路口车辆轨迹聚类,划分出车辆轨迹模式类型,识别出正常车辆轨迹和异常车辆轨迹;
步骤4,基于步骤3模式分析的车辆轨迹类型提取出单一模式正常车辆轨迹,进一步对单一模式车辆轨迹分析,识别出单一模式下异常车辆轨迹和正常车辆轨迹;
步骤5,基于步骤3和4中的异常车辆轨迹,对路口状况进行分析。
进一步地,所述步骤1中,具体包括如下分步骤:
步骤1-1,对路口类型及其渠化信息进行采集;
步骤1-2,基于单位时间段内路口监控视频根据不同车辆id提取出原始轨迹点,记为p(f,x,y),其中f表示帧数,x和y表示轨迹点坐标数值;
步骤1-3,基于原始轨迹点p在二维坐标内绘制出车辆原始轨迹点,从中确定缺失重要特征数据和不正确数据并进行剔除,实现原始轨迹点清洗;其中缺失重要特征数据为偏离数据,其可组成短路径但偏离线路走向,不正确数据即无法平滑连接的密集散点集,其无法构成路径轨迹。
进一步地,所述步骤2中,具体包括如下分步骤:
步骤2-1,基于同一车辆id下的原始轨迹数据p进行分析,在统计时间段t内对单位时间提取定量数据实现轨迹特征点提取;
步骤2-2,基于提取的特征点进行轨迹绘制,根据f帧数大小排列,确定车辆轨迹,记为tr={p|pi,1≤i≤n,n为轨迹点数}。
进一步地,所述步骤3中,具体包括如下分步骤:
步骤3-1,控制相似度阈值γ,确定簇数k的范围,基于层次聚类算法确定相似度阈值γ下最佳聚类簇数kopi以及其聚类结果;
步骤3-2,重复步骤3-1,调整相似度阈值γ,重复求解出不同相似度阈值γ下的最佳聚类簇数kopi,记为
步骤3-3,基于
步骤3-4,基于最佳阈值γopi和最优聚类簇数kopi,确定车辆轨迹的聚类结果,识别出车辆轨迹模式类型,确定正常车辆轨迹和异常车辆轨迹;
具体来说,基于步骤3-3确定的最佳阈值γopi和最优聚类簇数kopi进行车辆轨迹层次聚类,根据步骤1的路口渠化信息,对聚类的车辆轨迹模式进行分类,将根据路口渠化流向下划分以外的车辆轨迹默认为异常车辆轨迹,其余则为正常车辆轨迹。
进一步地,所述步骤3-1中,包括如下分步骤:
步骤3-1-1,控制相似度阈值γ,通过lcss算法确定两两轨迹之间的最长公共子序列和最长公共子序列相似度距离;
步骤3-1-2,根据上一步骤的最长公共子序列相似度距离列出相似度矩阵s[a][b],即为邻近矩阵;
步骤3-1-3,确定聚类簇数k的范围;具体来说,根据步骤1的路口渠化信息确定聚类簇数k的最小数值;
步骤3-1-4,给定簇数k,不断重复步骤3-1-1和3-1-2得到层次聚类的聚类结果;
步骤3-1-5,根据步骤3-1-3给定的簇范围确定出控制相似度阈值γ一定时k值不同的聚类情况,根据不同k值聚类下的组内距和组间距建立评价体系,从而确定最佳聚类簇数kopi,具体如下:
根据步骤3-1-4的聚类结果提取出组内轨迹的所有特征点pi,根据特征点pi确定确定划分k组情况下k个聚类簇中心{c1,c2,c3,...,ck},1<k≤k,其中簇中心ck为该组内所有特征点的中心;
根据k组簇中心分别求得k组内的组内距τk以及组间距
基于不同组数k下的组内距均值
进一步地,所述步骤3-3中,包括如下分步骤:
步骤3-3-1,根据
步骤3-3-2,根据
步骤3-3-3,基于不同的相似度阈值γ及其kopi下的组内均方差
进一步地,所述步骤4中,具体包括如下分步骤:
步骤4-1,提取出单一模式下正常车辆轨迹,基于正常车辆轨迹的轨迹特征点数值,以轨迹的轨迹相似度λ、加速度方差α2、弧长比σ作为特征数值进行层次聚类,划分出异常行驶轨迹、异常行为轨迹和正常车辆轨迹;
步骤4-2,整合上一步骤分析得到的正常车辆轨迹,在dtw算法下对上一步骤的正常车辆轨迹再次进行层次聚类,判别出正常车辆轨迹和离群轨迹;
步骤4-3,重复步骤4-1至4-2,对路口各模式下车辆轨迹分析,划分各流向中异常行驶轨迹、异常行为轨迹、离群轨迹和正常车辆轨迹,其中将异常行驶轨迹、异常行为轨迹和离群轨迹均默认为异常车辆轨迹。
进一步地,所述步骤4-1中,具体包括如下分步骤:
步骤4-1-1,对车辆轨迹trj的轨迹相似度λ、加速度方差α2、弧长比σ进行求解;
根据车辆轨迹特征确定相似度计算公式,如lcss算法或dtw算法,求得车辆轨迹相似度λ;
基于车辆轨迹tr的轨迹特征点确定各车辆轨迹的加速度方差α2,即:
式中,αi+1表示特征点i+1的加速度,其中fi和fi+1表示帧数,
基于车辆轨迹tr确定车辆轨迹弧长比σ,即:
式中,p1、pi、pi+1、pn均表示车辆轨迹内的特征点;
步骤4-1-2,基于上一步骤车辆轨迹tr的相似度λ、加速度方差α2、弧长比σ数值作为特征数据进行层次聚类,划分为异常行驶轨迹、异常行为轨迹和正常车辆轨迹;具体来说,以相似度λ、加速度方差α2、弧长比σ数值作为特征数据进行层次聚类,将车辆轨迹划分为三组数据,根据三组数据的数据量及各组数据离散程度确定数据类型;
计算三组车辆轨迹的轨迹数量及其与总轨迹数量的比值,若组内轨迹数量最少则那组车辆轨迹数据默认为异常行驶轨迹;
基于车辆轨迹的特征点分别求剩余两组车辆轨迹数据的离散程度ε,即:
式中,n为组内所有车辆轨迹特征点的总个数;pi为特征点,
将离散程度ε较大的那组数据默认为异常行为轨迹,较小的那组数据默认为正常车辆轨迹,同时实现正常车辆轨迹提取。
进一步地,所述步骤5中,具体包括如下分步骤:
步骤5-1,整合步骤3和4中的异常车辆轨迹,对异常车辆轨迹发生原因进行分析,同时将异常车辆轨迹与异常原因相对应,建立异常轨迹关联数据库;
步骤5-2,基于统计时间段内异常轨迹数目比例及其行为原因对路口渠化组织问题和交通信号控制问题进行分析,识别出不合理的路口渠化和不合理的路口信号方案。
进一步地,所述步骤5-2中,具体如下:
若统计时间段内异常轨迹数目大于路口异常状况阈值,则分析其渠化是否存在问题;
若同一流向下,统计时间段放行相位阶段内,异常轨迹数目大于异常状况阈值,则分析该相位阶段信号方案配置是否合理。
本发明达到的有益效果为:
1.目前的lcss车辆轨迹研究依托gps数据和路网信息,将gps点位信息与路网地图匹配实现数据初步处理和清洗,通过gps数据特征点实现聚类,将lcss相似度长度距离替换欧式距离实现层次聚类,但无法进行聚类效果的评判,本发明运用了视频号牌数据代替gps数据,利用lcss算法对车辆轨迹相似程度分析,利用路口渠化特征为无监督学习打上标签,不断迭代确定最优簇数和最优阈值,从而提高了车辆轨迹层次聚类的效果。
2.对比传统的路网车辆轨迹研究(对所有车辆轨迹一体化聚类分析),本发明以单个路口和单个流向车辆轨迹进行分析,通过lcss层次聚类算法对路口车辆轨迹分类,有效识别出路口车辆轨迹类型和异常轨迹,进一步对各模式类型下车辆轨迹分析,对各流向车辆异常轨迹识别提取,从而为路口交通冲突安全管理和拥堵管理提供有效支撑。
3.本发明创新的建立异常轨迹数据库(一一对应的异常车辆轨迹类型和轨迹异常原因),根据路口渠化信息和交通信号方案对异常车辆轨迹进行分析,通过对统计时间段内异常轨迹分析,有效识别出路口渠化组织的问题和信号方案问题,对路口渠化优化和交通信号配时方案的优化调整提供支撑依据。
附图说明
图1为本发明所述车辆轨迹识别分析方法的步骤流程图。
图2为本发明实施例中绘制出车辆原始轨迹点的示意图。
图3为本发明实施例中筛选后绘制出的车辆轨迹示意图。
图4为本发明实施例中根据聚类信息用颜色标注后的车辆轨迹示意图。
图5为本发明实施例中提取出的异常车辆轨迹示意图。
图6为本发明实施例中对南进口车道左转车辆轨迹求解出各车辆轨迹的相似度、弧长比和加速度方差列表。
图7为本发明实施例中通过层次聚类将车辆轨迹划分为正常轨迹、异常行为和异常轨迹的三种车辆轨迹示意图。
图8为本发明实施例中划分后的正常轨迹和离群轨迹示意图。
图9为本发明实施例中所有车辆轨迹的示意图。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
基于层次聚类的路口异常车辆轨迹识别分析方法,可以对视频结构化数据分析,实现路口轨迹类型识别和分类,有效划分出异常车辆轨迹,为异常轨迹建立轨迹数据库,辅助实现交通渠化和信控方案评估分析。具体包括如下步骤:
步骤1,采集路口渠化信息,提取路口监控视频数据完成数据清洗。
步骤1-1,对路口类型及其渠化信息进行采集。如十字路口,则对东、南、西、北四个进口道的车道数目、宽度以及非机动车车道宽度进行渠化信息采集;如天桥路口,则对岔路口车道信息采集。
步骤1-2,基于单位时间段内路口监控视频根据不同车辆id提取出原始轨迹点,记为p(f,x,y),其中f表示帧数,x和y表示轨迹点坐标数值。一般情况下,监控视频源自电子警察、智能卡口、球机监控等,以角度高视野好的球机视频为主。
步骤1-3,基于原始轨迹点p在二维坐标内绘制出车辆原始轨迹点,从中确定缺失重要特征数据和不正确数据并进行剔除,实现原始轨迹点清洗。其中缺失重要特征数据为偏离数据,其可组成短路径但偏离线路走向,不正确数据即无法平滑连接的密集散点集,其无法构成路径轨迹。
步骤2,针对不同车辆id实现单条轨迹分析,提取单条轨迹的数据特征点,确定车辆轨迹。
步骤2-1,基于同一车辆id下的原始轨迹数据p进行分析,在统计时间段t内分别从各单位时间t内选取n个数据,实现轨迹特征点提取。一般情况下,单位时间t选取5-6秒,n选取25-35个,同时为方便聚类分析,提高聚类效果,每条车辆轨迹的总特征点可均取一个数值。
步骤2-2,基于提取的特征点p进行轨迹绘制,根据f帧数大小排列,确定车辆轨迹,记为tr={p|pi,1≤i≤n,n为轨迹点数}。
步骤3,基于lcss算法和层次聚类算法实现路口车辆轨迹聚类,划分出车辆轨迹模式类型,识别出正常车辆轨迹和异常车辆轨迹。
步骤3-1,控制相似度阈值γ,确定簇数k的范围,基于层次聚类算法确定相似度阈值γ下最佳聚类簇数kopi以及其聚类结果。
步骤3-1-1,控制相似度阈值γ,通过lcss算法确定两两轨迹之间的最长公共子序列和最长公共子序列相似度距离,即:
式中tr1和tr2分别为两条长度为m、n的轨迹;
步骤3-1-2,根据上一步骤的最长公共子序列相似度距离列出相似度矩阵s[a][b],即为邻近矩阵。
具体来说,将传统层次聚类中的欧式距离替换成lcss相似度距离,分别列出两两轨迹之间的相似度距离,其中以第i行为例,其行内数值为最长公共子序列的相似度距离,即为{dlcss(trj,tr1),dlcss(trj,tr2),…,dlcss(trj,trn)},式中1≤j≤n,表示第i条车辆轨迹。
步骤3-1-3,确定聚类簇数k的范围(最小值)。
具体来说,根据步骤1的路口渠化信息确定聚类簇数k的最小数值。如一个十字路口,其存在东、南、西、北四个方向的左转、直行和右转,且路口允许掉头,因此簇数k从16开始取值。
步骤3-1-4,给定簇数k,不断重复步骤3-1-1和3-1-2得到层次聚类的聚类结果。具体包括如下内容:
1)根据最长公共子序列相似度数值不断合并最接近的两条轨迹,具体来说,取min(s[a][b])进行合并,其中将轨迹重合情况排除(其数值为零)。
如tr1、tr2、tr3、tr4四条车辆轨迹,求解出其最长公共子序列相似度距离,邻近性矩阵s[a][b]为:
则可将tr1和tr4进行合并(其数值为0.6)作为新一个簇并进行s[a][b]求解和聚类。
2)将合并的两条轨迹默认为新簇,重复步骤直到达到设定的k簇数为止。具体来说,trj和trj-1根据上一轮聚类结果已合并,则进行第二轮层次聚类时,需要重新计算dlcss数值,且列出新的s[a][b]矩阵。
步骤3-1-5,根据步骤3-1-3给定的簇范围确定出控制相似度阈值γ一定时k值不同的聚类情况,根据不同k值聚类下的组内距和组间距建立评价体系,从而确定最佳聚类簇数kopi。具体包括如下内容:
1)根据聚类结果提取出组内轨迹的所有特征点pi,根据特征点pi确定确定划分k组情况下k个聚类簇中心{c1,c2,c3,...,ck},1<k≤k,其中簇中心ck为该组内所有特征点的中心。
2)根据k组簇中心分别求得k组内的组内距τk,即:
式中:n为第k组内的样本数量,其中1≤k≤k;dist(pi,ck)表示k组内样本点到簇中心点距离;pi为轨迹i的样本信息,其中1≤i≤n,;ck为k组的簇中心点。
进一步,求得k组情况下的组内距均值,记为
3)基于簇中心点求解出组间距
式中:k为簇中心个数,ck和ck′为簇中心点坐标。
4)基于不同组数k下的组内距均值
步骤3-2,重复步骤3-1,调整相似度阈值γ,重复求解出不同相似度阈值γ下的最佳聚类簇数kopi,记为
步骤3-3,基于
步骤3-3-1,根据
式中:
步骤3-3-2,根据
式中:
步骤3-3-3,基于不同的相似度阈值γ及其kopi下的组内均方差
步骤3-4,基于最佳阈值γopi和最优聚类簇数kopi,确定车辆轨迹的聚类结果,识别出车辆轨迹模式类型,确定正常车辆轨迹和异常车辆轨迹。
具体来说,基于步骤3-3确定的最佳阈值γopi和最优聚类簇数kopi进行车辆轨迹聚类,根据步骤1的路口渠化信息,对聚类的车辆轨迹模式进行分类,将根据路口渠化流向下划分以外的车辆轨迹默认为异常车辆轨迹,其余则为正常车辆轨迹,一般情况下,路口的异常车辆轨迹包含非机动车行驶轨迹、车辆逆行行驶轨迹、车辆暂停等异常情况。
步骤4,基于步骤3模式分析的车辆轨迹类型提取出单一模式(流向)正常车辆轨迹,进一步对单一模式(流量)车辆轨迹分析,识别出异常轨迹和正常车辆轨迹。
步骤4-1,提取出单一模式(流向)正常车辆轨迹,基于车辆轨迹tr特征点数值,以轨迹的轨迹相似度λ、加速度方差α2、弧长比σ作为特征数值进行层次聚类,划分出异常行驶轨迹、异常行为轨迹和正常车辆轨迹。
步骤4-1-1,对车辆轨迹trj的轨迹相似度λ、加速度方差α2、弧长比σ进行求解。具体包括如下步骤:
1)根据车辆轨迹特征确定相似度计算公式,如lcss算法或dtw算法,进一步求得车辆轨迹相似度λ。
若采用lcss算法,则基于lcss算法求得车辆轨迹相似度λ的计算公式即:
式中tr1和tr2分别为两条长度为m、n的轨迹;
若采用dtw相似度,则基于dtw算法求得车辆轨迹相似度λ的计算公式为:
dtw(tr1,tr2)=f(m,n)
式中tr1和tr2分别为两条长度为m、n的轨迹;tr1=[p1,p2,…,pm-1,pm]
tr2=[q1,q2,…,qn-1,qn],其中pi和qj分别代表轨迹特征点坐标,
一般情况下,lcss算法和dtw算法的选择由路口特征和轨迹数据量确定。
2)基于车辆轨迹tr的轨迹特征点确定各车辆轨迹的加速度方差α2,即:
式中,αi+1表示特征点i+1的加速度,其中fi和fi+1表示帧数,
3)基于车辆轨迹tr确定车辆轨迹弧长比σ,即
式中,p1、pi、pi+1、pn均表示车辆轨迹内的特征点;
步骤4-1-2,基于上一步骤车辆轨迹tr的相似度λ、加速度方差α2、弧长比σ数值作为特征数据进行层次聚类(聚类的簇组数k为3),划分为异常车辆轨迹、异常行为轨迹和正常车辆轨迹。
具体来说,以相似度λ、加速度方差α2、弧长比σ数值作为特征数据进行层次聚类,将车辆轨迹划分为三组数据,根据三组数据的数据量及各组数据离散程度确定数据类型。具体步骤如下:
1)计算三组车辆轨迹的轨迹数量及其与总轨迹数量的比值,若组内轨迹数量最少则那组车辆轨迹数据默认为异常行驶轨迹,转为下一步骤。
2)基于车辆轨迹的特征点分别求剩余两组车辆轨迹数据的离散程度ε,即
式中,n为组内所有车辆轨迹特征点的总个数;pi为特征点,
将离散程度ε较大的那组数据默认为异常行为轨迹,较小的那组数据默认为正常车辆轨迹,同时实现正常车辆轨迹提取。
步骤4-2,整合上一步骤的正常车辆轨迹,在dtw算法下对车辆轨迹再次进行层次聚类(聚类的簇组数为2),判别出正常车辆轨迹和离群轨迹。具体步骤如下:
1)提取正常车辆轨迹,基于dtw算法确定两两轨迹之间的相似度,即:
dtw(tr1,tr2)=f(m,n)
式中tr1和tr2分别为两条长度为m、n的轨迹;tr1=[p1,p2,…,pm-1,pm]
tr2=[q1,q2,…,qn-1,qn],其中pi和qj分别代表轨迹特征点坐标,
进一步确定两两轨迹之间的相似度矩阵s[a][b],以第i行为例,其行内数值为dtw轨迹相似度,即{dlcss(trj,tr1),dlcss(trj,tr2),…,dlcss(trj,trn)},式中1≤j≤n,表示第j条轨迹;n表示提取的正常车辆轨迹的轨迹总数。
2)利用相似度举证s[a][b]内各相似度数值,通过层次聚类算法将正常车辆轨迹划分为两类。
3)对于两类车辆轨迹分析,若某一组车辆轨迹数目与车辆轨迹总数目的比值小于异常阈值(一般取30%),则将该组合数据默认为离群轨迹,另一组合数据为正常车辆轨迹,否则转到下一步骤。
4)基于各车辆轨迹的特征点求解出两个组合的车辆轨迹离散程度ε,即:
式中,n为组内所有车辆轨迹特征点的总个数;pi为特征点,
步骤4-3,重复步骤4-1至4-2,对路口各模式(流向)下车辆轨迹分析,划分各流向中异常行驶轨迹、异常行为轨迹、离群轨迹和正常车辆轨迹,其中将异常行驶轨迹、异常行为轨迹和离群轨迹均默认为异常车辆轨迹。
步骤5,基于步骤3和4中的车辆轨迹识别信息中的异常车辆轨迹,对路口状况进行分析。
步骤5-1,整合步骤3和4中的异常车辆轨迹,对异常轨迹发生原因进行分析(如违法车辆行为、躲避行人异常行为、车辆冲突行为),同时将异常车辆轨迹与异常原因相对应,建立异常轨迹关联数据库。
步骤5-2,基于统计时间段内异常轨迹数目比例及其行为原因对路口渠化组织问题和交通信号控制问题进行分析,识别出不合理路口渠化和不合理路口信号方案。
1)若统计时间段内某原因异常轨迹数目大于路口异常状况阈值(一般取30%-40%,根据路口渠化类型确定),则根据其原因分析路口渠化问题是否存在问题。如统计时间段(7天)内某路口均存在车辆躲避行人异常行为,则判定非机动车道与机动车道之间渠化是否合理。
2)若同一流向下,统计时间段放行相位阶段内,异常轨迹数目大于路口异常状况阈值(一般取30%-40%之间),则根据原因分析路口信号方案配置是否合理,如某左转相位阶段均在较多异常轨迹数目,则左转相位相序或绿灯时长设置是否合理。
以下通过具体示例对本发明提出的车辆轨迹识别分析方法进行说明。
示例1为十字路口,选取某十字路口5分钟内球机监控视频,从中提取出车辆id、帧数、x坐标、y坐标数值,基于x/y坐标绘制出车辆原始轨迹点,从中剔除不正确数据和缺失重要特征数据,如图2所示。
通过步骤3基于车辆id对其特征点进行筛选,如提取出id下的原始数据点,在其6s单位时间中随机筛选出30条数据,绘制出车辆轨迹,具体如图3所示。
进而从中将等待红灯等状况(数据点未移动)数据剔除,从5min总时长内筛选出100个特征点,同理对所有车辆id下的轨迹进行特征点提取(共305条车辆轨迹)。
基于lcss算法求解出305条轨迹之间的相似度关系,其中相似度阈值γ的初始值为30,列出相似度矩阵s[a][b],将tr1、tr2、tr3、tr4四条数据单独拎出来,其相似度矩阵为:
即轨迹tr4与轨迹tr1的相似度为0.6。
进一步不断叠加计算确定k组情况下的聚类效果,从而对比各k组情况下聚类的特征点组间距数值和组内距均值,将比值最大的k值设定为最优簇数,即确定γ=30情况下的簇数k=44。进一步调整相似度阈值γ得到不同相似度阈值及其簇数。
最终通过组间距均方差和组内距均方差确定最优阈值γ=26,其簇数k=42。在特征点轨迹轮廓基础上,根据聚类信息用颜色标注,具体包括左转(东左转、西左转、北左转、南左转)、直行(东直行、西直行、北直行、南直行)、右转(东右转、西右转、北右转、南右转)、掉头(南掉头、北掉头)和其余异常轨迹,具体如图4所示。
路口分类情况如图5所示,从中提取出异常车辆轨迹。
进一步,对南进口车道左转车辆轨迹进行提取分析,基于lcss算法求解出各车辆轨迹的相似度,同时求解出各轨迹的弧长比和加速度方差,数据列表图6所示。
通过层次聚类将车辆轨迹划分为正常车辆轨迹、异常行为轨迹和异常行驶轨迹,具体分类如图7所示。
进一步对其中的正常车辆轨迹提取分析,利用dtw算法求出轨迹之间的相似度矩阵,具体如下:
从而划分出正常车辆轨迹和离群轨迹,具体如图8所示。
对各流向下车辆轨迹分析,整合所有异常车辆轨迹,其数值未超过路口异常状况阈值(异常车辆数目小于轨迹总数的35%)对照监控视频,发现异常轨迹原因,其主要为车辆违法行为(绕路行驶)。
示例2为天桥路口,选取某天桥路口5分钟内球机监控视频,从中提取出车辆id、帧数、x坐标、y坐标数值,基于x/y坐标绘制出车辆原始轨迹点,从中剔除不正确数据和缺失重要特征数据,实现原始轨迹清洗和轨迹特征点提取。
进一步通过lcss算法和层次聚类不断迭代找到最优相似度阈值γ及其簇数k(γ=30,k=10),绘制出车辆轨迹信息,确定车辆轨迹类型,具体类别包括左转(入和出)、直行(南向北、北向南)、右转(入和出)及其他异常轨迹,进而分析出异常车辆。所有车辆轨迹如图9所示。
进一步对某单一模式下车辆轨迹分析,最终将所有非正常轨迹整合,为交通管理提供支撑依据。
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!