一种面向二次事故预防动态车道与可变限速协同控制方法与流程
本发明属于道路交通安全设计、智能交通管理与控制技术领域,尤其涉及一种面向二次事故预防的动态车道与可变限速协同控制方法。
背景技术:
快速道路属于少数能提供完全不间断高速交通流的公路设施类型,在区域交通运输体系中起骨架作用,而事故的发生会形成固定瓶颈,造成伤亡与财产损失,还会产生额外的排放和能源浪费。另外,事故的发生还可能引发二次事故,不仅进一步加剧已有事故的影响,还会极大危害应急人员的生命健康。因此对二次事故发生概率及严重程度的有效控制即是事故预防管理领域的重要任务。
在事故影响下将会形成沿纵向的速度差与横向各车道间的速度差。前者会迫使上游来车剧烈减速,而后者也会产生强烈的换道需求从而形成时走时停波。两类现象叠加一方面降低通行能力,另一方面也增加了追尾等二次事故风险。
动态车道控制与可变限速控制技术均以此出发,基于探测器获取的交通信息在事故发生后于上游交通条件较好处发布合理换道建议和速度建议以降低二次事故风险。前者旨在缓解事故形成的横向速度差,而后者则以平滑纵向速度差为目的。因为控制中心可获取全局交通状态,其发布的换道建议和速度建议具有较高的合理性。
技术实现要素:
发明目的:本发明的目的是提出面向二次事故预防的动态车道与可变限速协同控制方法,通过动态车道与可变限速协同控制降低快速道路事故发生后因受迫换道、盲目换道及受迫减速等行为形成的追尾等二次事故风险。
技术方案:为实现本发明的目的,本发明所采用的技术方案是:一种面向二次事故预防的动态车道与可变限速协同控制方法,该方法包括以下步骤:
1)构建面向二次事故预防的动态车道与可变限速协同控制系统,包括交通指令发布设备、交通数据采集设备、协同控制模型(actor)与评价模型(critic),交通指令发布设备与交通数据采集设备沿快速道路布设,协同控制模型与评价模型均为神经网络模型,协同控制模型与评价模型共同组成控制-评价模型(actor-critic);
2)选择可变信号板作为交通指令发布设备,布设于交通龙门架上,悬于道路横断面上方;一台龙门架即为一道控制断面,挂有多片可变信号板,一片可变信号板针对一车道同时发布动态车道与可变限速指令,其中动态车道指令包括“正常通行”、“建议向左换道”、“建议向右换道”三种;可变限速指令包括“保持默认限速”、“下调限速20km/h”两种,可变限速控制指令不区分车道,同一断面的所有车道具有相同的限速,控制断面间距设为500米;
3)选择流量监测摄像头作为交通数据采集设备,间隔地布设于交通龙门架与单悬臂杆上,悬于道路横断面上方,一台龙门架或一支悬臂杆即为一道探测断面,挂有多台摄像头,一台摄像头针对一车道,监控上游50米长区间,每隔1秒采集监控区间内的车道占用率(%)、速度(m/s)、排队长度(m)等交通信息(车道占用率反映交通密度,当一车道被机动车完全占满时对应的占用率为100%)。多道探测断面共同采集的交通信息经过预处理后共同组成交通状态。探测断面间距设为250米。当探测断面与控制断面重合时,摄像头与可变信号板共用相同的龙门架;当探测断面位于两控制断面中间时,摄像头安装于单臂悬臂杆上;
4)构造一神经网络作为控制-评价模型,包含协同控制模型与评价模型两部分,协同控制模型与评价模型共用相同的输入层和中间层,仅输出层不同,每隔一个控制周期t,神经网络以交通状态作为输入值,同时输出控制策略与控制策略的“价值”(value),其中,控制策略为动态车道与可变限速协同控制,一方面引导上游来车提前于合理断面处减速,一方面引导上游来车提前于合理断面处换道至相邻开放车道;“价值”为一个实数,是对控制策略的长短期综合效益的量化,越大表示相应控制策略在相应交通状态下具有越大的效益,也就是越合适。
进一步的,所述步骤3)中,交通状态由摄像头采集。记摄像头每隔1秒采集实时交通状态为矩阵
注意到修正交通状态st不仅包括当前的交通状态
进一步的,所述步骤4)中控制-评价模型每隔一个控制周期t=25s,基于该时刻的修正交通状态st,t=kt,
进一步的,所述步骤4)中,为量化控制-评价模型于kt时刻输出的动作akt的实际效果,计算该控制周期结束后的(k+1)t时刻的奖励值r(k+1)t:
式中,skt,spd即为修正交通状态skt中与速度有关的元素集合,路段速度均值mean(skt,spd)与标准差s.d.(skt,spd)共同定义实际奖励值
在至少一个断面的限速控制被激活时,修正因子
进一步的,所述步骤4)中,控制-评价模型的训练算法采用深度强化学习ppo算法,并引入演员-评论家(actor-critic)框架加速收敛。
进一步的,所述步骤4)中,因为强化学习要求模型与环境多次交互,故模型训练过程在交通仿真平台上进行。在仿真平台上初始化事故仿真环境,包括路段长度、车道数、限速、流量、事故位置、事故开始时间、事故结束时间,并布设摄像头和可变信号板,形成探测断面和控制断面。开始事故仿真后基于修正交通状态skt,控制-评价模型输出的控制指令akt及“价值”v(skt),并观察奖励值rkt,计算策略梯度与估值误差并更新控制-评价模型。在交通仿真平台重复进行事故仿真,直至误差收敛得到最优控制-评价模型。
进一步的,所述步骤4)中,在得到最优控制-评价模型后,仅需其中的控制模型即可进行实际控制,即每隔一个控制周期基于修正交通状态skt输出动态车道与可变限速协同控制指令akt,既不需要评价模型输出“价值”v(skt),也不需要观测奖励值rkt。
有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果:
1、丰富了面向二次事故预防的控制策略选择。在各项动态控制技术中,可变限速因其高效的控制效果而在安全、效率、环境等领域得到广泛研究,相比之下动态车道控制所得关注较少。然而考虑到两类技术应用原理、适用范围不同,特别是在低流量时可变限速的应用存在一定的局限性,动态车道控制技术在此环境下更有助于兼顾安全与速度两项指标,应用潜力更大。将动态车道控制技术与可变限速控制结合,共同引入二次事故预防策略有助于增强控制手段的利灵活性;
2、同时考虑交通安全与运输效率两项指标。动态车道控制技术提出之初即为了缓解下游部分车道封闭后上游来车频繁低效换道的现象,然而在引导上游来车提前避开封闭车道的同时又不可避免地造成部分车道资源的浪费。同样地,可变限速控制在压缩事故影响的同时也不可避免地形成了新的瓶颈,需要在新的减速瓶颈与原有事故瓶颈之间充分权衡。本研究在动态车道与可变限速协同控制策略训练时设置了由路段速度均值与标准差组成的奖励函数,基于深度强化学习算法进行在线优化,尽可能兼顾交通安全与运输效率两项指标。
3、在考虑控制策略效果的同时也对策略复杂度与不合理性进行限制。本研究在设置策略奖励函数时引入针对策略复杂度与不合理性的修正因子,以避免强化学习时控制模型落入某些复杂且不合理的局部最优值。
附图说明
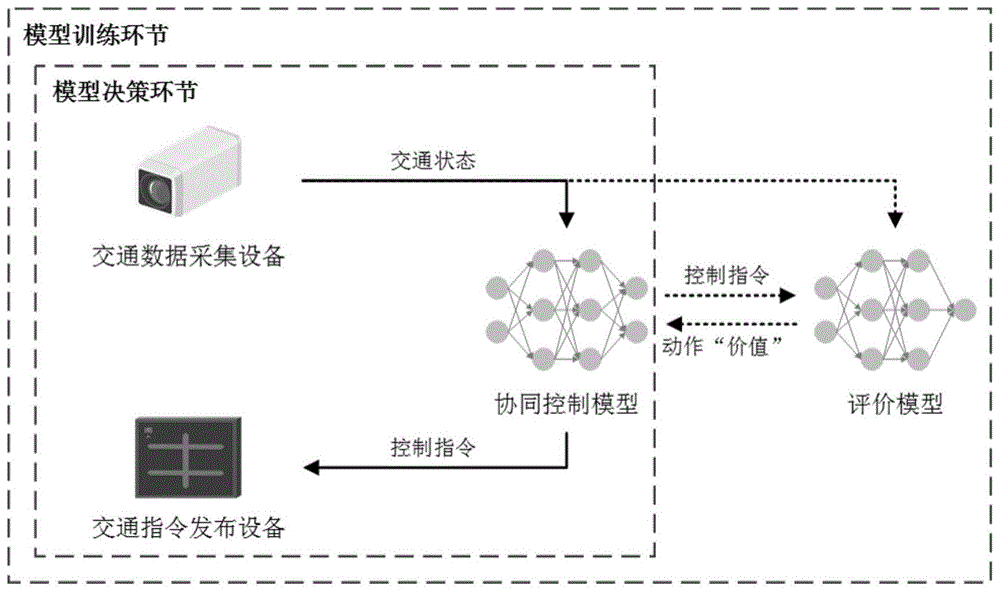
图1是本发明的控制系统组成与模型训练、决策机制示意图。
图2是本发明的快速道路设备布设示意图。
图3是本发明中协同控制模型的决策流程图。
图4是本发明中控制-评价模型的训练流程图。
图5是本发明中控制-评价模型的结构示意图。
具体实施方式
图1为本发明的控制系统组成与模型训练、决策机制示意图,包括以下步骤:
步骤一,选择可变信号板作为交通指令发布设备,布设于交通龙门架上,悬于道路横断面上方。一台龙门架即为一道控制断面,挂有多片可变信号板,一片可变信号板针对一车道同时发布动态车道与可变限速指令。其中动态车道指令包括“正常通行”、“建议向左换道”、“建议向右换道”三种;可变限速指令包括“保持默认限速”、“下调限速20km/h”两种。可变限速控制指令不区分车道,同一断面的所有车道具有相同的限速。控制断面间距设为500米。
步骤二,选择流量监测摄像头作为交通数据采集设备,沿快速道路布设,间隔地布设于交通龙门架与单悬臂杆上,悬于道路横断面上方。一台龙门架或一支悬臂杆即为一道探测断面,挂有多台摄像头,一台摄像头针对一车道,监控上游50米长区间,每隔1秒采集监控区间内的车道占用率(%)、速度(m/s)、排队长度(m)等交通信息(车道占用率反映交通密度,当一车道被机动车完全占满时对应的占用率为100%)。多道探测断面共同采集的交通信息经过预处理后共同组成交通状态。探测断面间距设为250米。当探测断面与控制断面重合时,摄像头与可变信号板共用相同的龙门架;当探测断面位于俩控制断面中间时,摄像头安装于单臂悬臂杆上。
步骤二中,交通状态由摄像头采集,记摄像头每隔1秒采集实时交通状态为矩阵
注意到修正交通状态st不仅包括当前的交通状态
步骤三,构造一神经网络作为控制-评价模型,包含协同控制模型与评价模型两部分。协同控制模型与评价模型共用相同的输入层和中间层,仅输出层不同。每隔一个控制周期t,神经网络以交通状态作为输入值,同时输出控制策略与控制策略的“价值”(value)。其中控制策略为动态车道与可变限速协同控制,一方面引导上游来车提前于合理断面处减速,一方面引导上游来车提前于合理断面处换道至相邻开放车道;“价值”为一个实数,是对控制策略的长短期综合效益的量化,越大表示相应控制策略在相应交通状态下具有越大的效益,也就是越合适。
步骤三中,神经网络结构见图5,为带残差结构的cnn-gru神经网络。卷积层(cnn)与gru层起到提取、整合交通流空间特征的效果。加入残差结构加速收敛。经过全连接层过渡后进入两个输出层,同时输出协同控制策略与控制策略的“价值”。考虑一段三车道宽、包含7道监控断面、3道控制断面的单向快速道路路段,则控制-评价模型一次输出的控制指令包括15个变量,前3个变量分别表示于三道控制断面激活可变限速控制的概率,之后6个变量分别表示于两条外侧车道的三道控制断面引导车辆向内侧换道的概率,还有6个变量分别表示于中间车道的三道控制断面引导车辆向两侧车道换道的概率。此时图5所示神经网络各层参数如表1。
表格1控制-评价模型各层参数
步骤三中,控制-评价模型每隔一个控制周期t=25s,基于该时刻的修正交通状态st,t=kt,
步骤三中,为量化控制-评价模型于kt时刻输出的动作akt的实际效果,计算该控制周期结束后的(k+1)t时刻的奖励值r(k+1)t:
式中,skt,spd即为修正交通状态skt中与速度有关的元素集合,路段速度均值mean(skt,spd)与标准差s.d.(skt,spd)共同定义实际奖励值
在至少一个断面的限速控制被激活时,修正因子
步骤三中,控制-评价模型的训练算法采用深度强化学习ppo算法,并引入演员-评论家(actor-critic)框架。深度强化学习是一类基于试错的机器学习算法。模型通过不断地与环境交互,尝试做出整体效益最高的决策,并通过观测每一次交互的实际奖励进行优化改进。演员-评论家框架是深度强化学习算法中的一类,与其它类型算法相比具有更快的收敛速度与更高的学习效果。
步骤三中,因为强化学习要求模型与环境多次交互,故模型训练过程在交通仿真平台上进行(见图4)。在仿真平台上初始化事故仿真环境,包括路段长度、车道数、限速、流量、事故位置、事故开始时间、事故结束时间,并布设摄像头和可变信号板,形成探测断面和控制断面。开始事故仿真后基于修正交通状态skt,控制-评价模型输出的控制指令akt及“价值”v(skt),并观察奖励值rkt,计算策略梯度与估值误差并更新控制-评价模型。在交通仿真平台重复进行事故仿真,直至误差收敛得到最优控制-评价模型。
步骤三中,在得到最优控制-评价模型后,仅需其中的控制模型即可进行实际控制。图3所示,每隔一个控制周期基于修正交通状态skt输出动态车道与可变限速协同控制指令akt。既不需要评价模型输出“价值”v(skt),也不需要观测奖励值rkt。
本方法在可变限速的基础上引入动态车道控制,丰富了面向二次事故预防的控制策略选择,可在快速道路事故发生后基于交通状态发布合理的动态车道与可变限速协同控制指令,引导上游来车提前合理换道并适当速度调整,降低受迫换道、盲目换道与受迫减速形成的二次事故风险。综上所述本方法在快速道路事故预警、管理与二次事故预防领域具有实际工程应用价值。
- 还没有人留言评论。精彩留言会获得点赞!