基于CLA-BLSA模型的短时交通流预测方法
本发明属于交通流预测研究领域,具体涉及一种基于混合深度学习的短时交通流预测方法。
背景技术:
1、实时而又准确的短时交通流量预测是实现智能交通系统的关键环节,因此,实现高精度的短时交通流预测一直以来都是交通领域的研究热点。目前的交通流预测主要有四种方法,包括统计分析的预测模型、非线性理论模型、仿真预测模型、智能预测模型。基于统计分析的预测模型大多模型简单,计算较快,但不能处理突发交通状况,精度一般。非线性理论模型大部分理论复杂,计算量大。仿真预测模型计算量大,实时性不高,不适用于大规模数据的交通流量预测。智能预测模型无需建立精确的数学模型,可以基于流量历史数据预测将来流量,但现有的预测模型对复杂环境中交通流数据缺失或者异常、交通流的时空相关性挖掘存在处理困难的现象,未充分考虑历史交通流量的周期变化特性,且在使用模型进行预测的过程中缺少对内部优化算法的改进等各种各样的原因,其预测精度有待提高。
技术实现思路
1、本发明将conv-lstm、bi-lstm和注意力机制进行融合提出了一种组合式的短时交通流量预测方法。通过引入注意力机制的conv-lstm模块捕获交通流的时空特性,并利用融合自注意力机制的bi-lstm模块对历史交通流的日周性特征和周周期性特征进行提取,与其他现有的预测方法对比,本发明具有更优越的预测性能。
2、其次考虑到交通流复杂的时空特性以及每日和每周呈现出的规律性,本发明提出了一种融合了conv-lstm、bi-lstm和注意力机制的cla-blsa模型,充分挖掘交通流的时空特性和复杂非线性特征,提升交通流预测的精度。该模型包含时空特征提取模块(cla)、交通流量日期性特征提取模块(blsa)和交通流量周期性特征提取模块(blsa)三个模块。其中cla模块是带有注意力机制的conv-lstm模块,该模块用于提取交通流的时空特征。同时,设计了两个blsa模块用于捕获交通流每日和每周的周期变化特性,blsa模块由基于自注意力机制的bi-lstm模块构成。最后采用lookahead优化算法通过指定内部循环优化器,更新快速权重、慢速权重的方式对模型进行优化。
3、本发明采用的技术方案为基于cla-blsa模型的短时交通流预测方法,该方法包括如下步骤,
4、步骤1.交通数据预处理
5、对观测点的历史交通数据集进行异常数据修复处理,并对修复后的数据进行标准化处理。
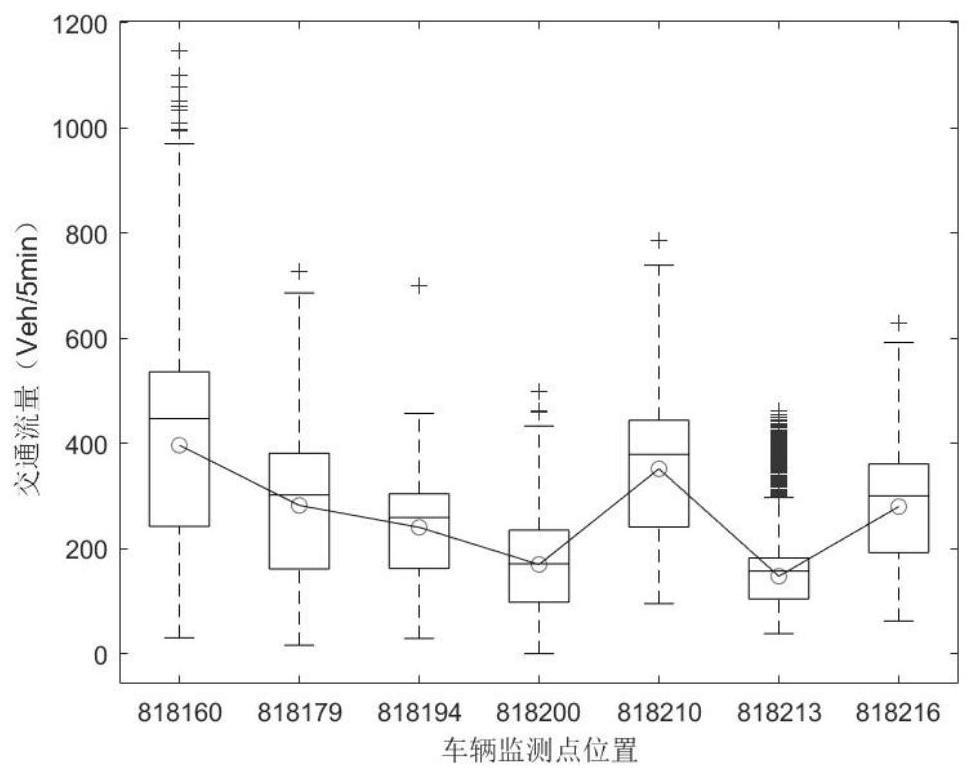
6、步骤1.1首先采用箱形图(box-plot)方法对异常数据进行识别,箱形图的上限之上或者下限之下的值被判定为异常值。
7、步骤1.2采用邻近点均值法对异常交通流进行修复,邻近点均值法通常选取异常值邻近前后时刻的交通数据进行异常修复,计算公式为:
8、
9、式中,n表示相邻时间点的数据取值个数,本发明中取n值为10;xt表示t时刻的交通流;表示t时刻的异常数据修复值。
10、步骤1.3对交通流数据作归一化处理,采用min-max标准化方法把交通流数据统一映射在[0,1]区间。计算公式如下:
11、
12、式中,f表示原始数据;x表示归一化后的值;fmax表示原始数据的最大值;fmin表示原始数据的最小值。
13、步骤1.4数学模型构建
14、假设研究区域有m个车辆观测点,表示当前时刻为t时m个车辆观测点的交通流量,表示t时刻第i个观测点的交通流量。预测的目标是在给定前n个时刻的历史交通流序列的情况下,预测第n+1个时刻的交通流量xn。
15、设表示在t时刻观测点p的交通流,观测点p从t-1时刻到t时刻的历史交通流可表示为然后m个观测点的历史交通流组成的时空交通流矩阵如下所示:
16、
17、式中,为预测区域m个观测点在t时刻的交通流量。
18、步骤2.构建时空特征提取模块cla模块
19、cnn和lstm是cla模块的关键组成部分,cnn由两个卷积层和一个池化层组成,卷积层使用一维卷积处理交通流输入矩阵,池化层采用最大池化法。lstm网络中采用了两层lstm,并在cnn和lstm组成的conv-lstm模块中引入了注意力机制。
20、预测点及其邻近点的时空交通流矩阵是conv-lstm模块的输入,conv-lstm模块对矩阵的每个时刻进行卷积运算,利用卷积核滤波器通过滑动滤波器获得局部感知域,从而提取到空间特征。
21、
22、式中,表示卷积层的输出;σ表示激活函数;ws表示滤波器的权重;bs表示偏差;*表示卷积运算。
23、通过两个卷积层对空间特征信息进行卷积操作后,传递到池化层进行最大池化操作,池化后的输出为然后将cnn模块的输出序列连接到lstm网络中。
24、为捕获更深层次的交通流的时间特征,conv-lstm模块中采用两层lstm对交通数据进行处理,第一层lstm的隐藏状态作为第二层lstm的输入。第一层lstm处理cnn模块的输出序列并从头到尾计算每个时刻t的隐藏状态序列然后将作为第二个lstm层的输入,然后计算出第二个lstm层每个时刻t的隐藏状态将最后一个时刻的隐藏状态作为最终时空特征序列进行输出。
25、标准的conv-lstm模块无法判断出不同交通流序列的重要程度并予以不同权重的关注,因此,本文在conv-lstm模块中引入注意力机制,以判断不同时间内交通流序列的重要程度级别。
26、每个时刻lstm的输出的加权总和是conv-lstm模块的输出,计算公式如下:
27、
28、
29、
30、式中,n+1表示交通序列的长度;βk表示t-(k-1)时刻的时间注意力值;s=(s1,s2,...,sn+1)t表示交通流序列中各部分的重要性;vs、whs、wls表示可学习权重参数;
31、步骤3.构建交通流的日周期特征和周周期特征提取模块blsa模块
32、一般来说,某个观测点的交通流量不只是受到邻近观测点的交通状况影响,还受到历史时间的交通流量影响,除此之外交通流量变化还具有周期性,因此,本节分别考虑了交通流量的日周期性和周周期性。为了充分体现交通流的周期性,根据前一天时刻t相同时刻的前后n个时间间隔的交通流量来构造具有日周期性的交通流矩阵,如下式所示:
33、
34、式中,td表示与前一天时刻t的相同时刻。
35、同样根据与上周时刻t相同时刻的前后n个时间间隔的交通流量来构造有周周期性的交通流矩阵,如下所示:
36、
37、式中,tw表示与上周时刻t的相同时刻。
38、城市道路交通流量的分布一般离不开居民的出行规律,每天和每周的交通流量都具有一定的周期性,此外,一定时间内的交通流不仅取决于前一时刻的交通流,而且还会影响下一时段的交通流,因此,本文提出了一个bi-lstm网络结合自注意力机制(self-attention)的blsa(bi-lstm self-attention)模块以提取交通流的日周期特征和周周期特征。经过bi-lstm层的特征提取,blsa模块引入的自注意力机制能够从bi-lstm层的隐藏层状态输出自动地选择性学习不同时间周期之间的相关性影响,从而捕获不同交通流序列之间所隐含的时间依赖。blsa模块主要由两个bi-lstm网络组成,分别用于提取交通流的日周期特征和周周期特征。其中bi-lstm网络由两个lstm层组成,用于前向传递和后向传递,因此可以提取来自两个方向的交通流量特征。经过bi-lstm层的特征提取,获得交通流时空的周期性特征,然后通过自注意力机制选择性学习bi-lstm层输出的隐藏层状态。两个bi-lstm网络的输入分别是预测时间点之前的时间和后一天、后一周的交通流量数据。
39、和表示bi-lstm模块的输入,和表示bi-lstm模块的输出。和表示正向lstm网络的输出,和表示反向lstm网络的输出。和为日周期性特征,和为周周期性特征。
40、在bi-lstm中引入自注意力机制对每个时刻tbi-lstm的隐藏状态输出和进行选择性学习,首先根据输入和计算和
41、
42、
43、
44、
45、
46、
47、式中,wdk、wwk、wdq、wwq、wdv、wwv为可学习权重参数。
48、采用放缩点积法分别计算q和k的相似性:
49、
50、
51、计算时间步长为t-k时注意力权重值和表示如下所示:
52、
53、
54、最后计算每个blsa模块的加权和输出,计算如下所示:
55、
56、
57、式中,表示由blsa模块提取的日期特征信息;表示由blsa模块提取的周期特征信息。
58、步骤4.融合交通流的时空特征和日/周周期性特征进行未来交通流预测。将步骤2提取的时空特征和步骤3提取的日/周周期性特征进行拼接融合,通过融合层(fusionlayer)将各模块的输出特征进行融合得到一个特征向量xf,如下式所示:
59、
60、式中,wα、wd和ww为模型需要学习的加权求和参数。
61、特征融合的特征向量xf经过两个全连接层进行处理后,输入到最后的输出预测层进行计算得到本章模型进行交通流预测的最终结果,其表达式如下:
62、
63、式中,表示输出预测层的输出结果;xc表示全连接层的输出向量;wp表示权重向量;bp表示偏置向量;tanh()为激活函数。
64、步骤5.损失函数构造
65、模型训练阶段,通过设置一个损失函数更新模型中的权值参数,它包括均方误差(mse)、l1权重正则化和l2权重正则化。损失函数的l1权重正则化主要是为了获得稀疏模型,可以防止模型过度拟合,损失函数的l2权重正则化的最大作用是防止模型中出现某参数数值过大而出现某一特征信息主导模型的预测性能的情况。损失函数的表达式如下所示:
66、
67、式中,λ1和λ2是正则化参数;w是权重。mse表示预测交通流与真实交通流的均方误差,表达式如下所示:
68、
69、式中,xp为预测交通流,xt是真实交通流;n是交通流数据集的数量大小。
70、l1权重正则化和l2权重正则化的定义如下:
71、
72、
73、式中,wi表示权重。
74、最终的损失函数表达式如下所示:
75、
76、根据上述损失函数,通过反向传播算法不断更新模型参数。训练好模型之后,将之前时刻的交通流数据输入到模型中进行处理,模型最后输出所有观测点在下一时刻的交通流预测值。
77、步骤6.lookahead优化算法
78、本发明采用lookahead优化算法增强本文所设计的短时交通流预测模型的鲁棒性和收敛性
79、lookahead算法优化流程如下:
80、步骤6.1给定初始化权值ω0、目标函数l、内循环优化器a、学习率α
81、步骤6.2更新快速权重。通过内部循环优化器a更新k次模型权值,对于模型的输入数据d,快速权重更新规则如下:
82、θj,i+1=θj,i+a(l,θj,i-1,d),(i=1,2,...,k)
83、式中,θj,i表示内循环权值的更新量;i表示内循环优化器的更新次数;j表示训练次数;a·()表示adam优化器函数。
84、步骤6.3更新慢速权重。按照内部循环优化器存储的k次序列权重,利用指数加权平均算法对第j次慢速权重ω进行更新,更新规则如下:
85、ωj+1=ωj+α(θj,i-ωj)
86、=α[θj,k+(1-α)θj-1,k+…+(1-α)j-1θ0,k]+(1-α)jω0
87、式中,ωj表示第j次训练后的模型权重;α表示学习率。
88、步骤6.4对第j+1次内循环优化器训练的权值进行更新:
89、θj+1,0=ωj+1
90、步骤6.5对最大训练次数和误差进行判断,判断其是否满足特定条件,若满足,则终止训练,将ωj+1作为最终权重,否则令j=j+1,并返回步骤6.2。
91、与现有交通流预测方法相比,本发明的有益效果为:针对现有的大多数预测模型对复杂环境中交通流数据缺失或者异常、交通流的时空相关性的挖掘存在处理困难的现象,同时未充分考虑历史交通流量的周期变化特性,在预测过程中未考虑使用更有效的优化算法对模型进行优化和改进等其它问题,本发明基于注意力机制的conv-lstm模块提取交通流的时空特征,同时使用融入自注意力机制的bi-lstm模块提取交通流的日/周周期特征。本发明中使用注意力机制优化各模块的结构输出,使各模块更关注更有价值的特征。最后采用lookahead优化算法在内部循环中使用指定标准优化器对数据集通过更新快速权重、慢速权重的方式对模型进行优化,从而提升交通流的预预测性能。
- 还没有人留言评论。精彩留言会获得点赞!