基于Pair-copula理论的多点光伏出力概率预测方法和系统与流程
本发明涉及光伏发电技术领域,具体地,涉及一种基于pair-copula理论的多点光伏出力概率预测方法和系统。
背景技术:
随着对光伏发电的鼓励性政策的出台、光伏电池组件效率提升、工艺进步和原材料成本下降等,光伏发电单元的建设成本在逐渐下降,我国光伏发电产业得到了迅猛发展。自2009年起,我国积极推广光伏发电的市场化发展,使得我国成为世界上光伏发电发展最快的国家。其中,分布式光伏由于建设规模灵活、安装简单、靠近用户等特点,是光伏发电的重要形式。以前,由于投资成本大、产业模式不成熟等原因,分布式光伏发展缓慢。2017年,随着一系列分布式光伏接入电网的规则要求等方面的支持政策的出台、地方政府对分布式光伏的补贴和光伏发电成本的下降,分布式光伏呈爆发式增长,新增装机量占比也在大大提升。分布式光伏系统环保、经济,对太阳能的应用起到积极的推动作用,必将会在未来一段时间内继续保持高速发展。对于电网,光伏发电的波动性和不确定性在并网过程中会对电网造成很大的冲击,不利于电力系统调度与运行。因此,需要对光伏出力进行预测,将“不确定”变为“可预知”,更好地进行电力系统的规划,推动光伏产业进一步发展。
国内外对光伏出力点预测的研究主要围绕物理法和统计法展开。物理法是对天气预报和光伏发电系统进行物理建模;统计法包括时间序列法,马尔科夫链法,支持向量机法和神经网络法。目前,国内外的研究主要集中在对单点光伏出力的预测,通过统计法或者物理法预测单点光伏发电功率,取得一定成果。但是,国内对光伏电站群出力的预测的研究成果和工程应用较少。随着国内光伏产业的迅猛发展,将会出现大量光伏电站建成并投入使用,为确保大规模光伏电站安全可靠并网,进行光伏电站群出力预测的研究至关重要。综上分析,国内外对于光伏出力预测的研究主要通过算法优化对模型进行改进,忽略了筛选原始数据的重要性,在提高预测精度方面存在瓶颈;相关研究主要集中在单点光伏出力预测方面,缺乏对多点光伏联合出力预测的研究。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于pair-copula理论的多点光伏出力概率预测方法和系统。
根据本发明提供的一种基于pair-copula理论的多点光伏出力概率预测方法,包括:
聚类步骤:对光伏电站群进行聚类,确定最佳聚类数目;
统计步骤:基于最佳聚类数目,对光伏电站群进行分类,得到多个聚类电站,统计各聚类电站的光伏出力值和联合出力,得到单点光伏出力的概率预测结果;
参数识别步骤:对单点光伏处理概率预测结果进行二维copula函数的参数识别,得到偏相关系数;
求解步骤:根据偏相关系数,求解pair-copula函数的相关性参数;
预测步骤:利用pair-copula函数和单点光伏出力的概率预测结果,得到多点光伏出力的概率预测结果。
优选地,所述聚类步骤包括:
特征归一步骤:选取n个光伏电站的特征指标,将不同量纲和数量级的特征指标的指标数据进行标准化处理,采用以下公式:
其中,x*为归一化后的指标数据,x为实际指标数据,max为光伏电站群的指标数据中的最大值,min为光伏电站群的指标数据中的最小值;
计算聚类中心步骤:随机选取k个光伏电站的特征指标作为聚类中心,记为第一聚类中心,按照欧式距离将剩余n-k个光伏电站归类到第一聚类中心的所在簇,计算剩余n-k个光伏电站的聚类中心,记为第二聚类中心;
阈值判断步骤:判断第二聚类中心与第一聚类中心之间的欧式距离是否小于设定阈值,若小于,则将第二聚类中心的所在簇对应的光伏电站确定为同类变电站,否则,则将第二聚类中心的所在簇对应的光伏电站确定为不同类变电站;
确定最佳聚类数步骤:计算聚类数目为k时的组内平方误差和,根据calinsky准则确定最佳聚类数目,其中calinsky的计算公式为:
式中:ssb为组与组之间的方差,ssw为组内方差,n为样本数,k为聚类数目,当calinsky最大时,选取k为最佳聚类数目。
优选地,所述统计步骤包括:
分类步骤:根据最佳聚类数目对光伏电站群进行分类,得到多个聚类电站,取各聚类电站中各光伏电站的光伏出力平均值作为该聚类电站的光伏出力值,记为xi,联合出力记为xk+1,对应的累积分布分别为{fi(xi),fk+1(xk+1)};
计算步骤:分别计算聚类电站中各光伏电站的光伏出力值,使用beta函数描述光伏电站的预测值和实际值的变化趋势,所述beta分布概率密度函数为:
式中,f(x:a,b)表示随机变量x在参数为a和b时的beta分布概率密度函数;
x表示随机变量;
a、b分别表示beta函数的形状参数,a>0,b>0;
b(a,b)为beta函数;
概率计算步骤:基于pair-copula理论得到联合出力的条件密度概率函数,计算公式为:
式中,v表示n维随机向量;
x表示随机变量;
vj表示v中的一个元素;
v-j表示除去vj后的剩余项;
f(x|v)表示条件v下变量x的条件概率密度函数;
f(x|v-j)表示条件v-j下变量x的条件边缘密度函数;
f(vj|v-j)表示条件v-j下变量vj的条件边缘密度函数;
优选地,所述求解步骤中,pair-copula函数的相关性参数通过以下公式求取:
式中:ρj,j+i|1,···,i-1是给定各光伏电站的出力(x1,x2,…,xj-1)时,xj和xj+i的偏相关系数;
ρj-1,j|1,···,j-2是给定各光伏电站的出力(x1,x2,···,xj-2)时xj-1和xj的偏相关系数;
下标i,j分别用以标识光伏发电站,其中1≤i≤n-j,1≤j≤n-1,n为光伏发电站总个数;
xj表示聚类电站的第j个光伏电站的光伏出力值;
xj+i表示聚类电站的第j+i个光伏电站的光伏出力值;
xj-1表示聚类电站的第j-1个光伏电站的光伏出力值。
优选地,所述预测步骤包括:
总出力计算步骤:对于(n-1)个光伏电站,(x1,x2,…,xn-1)表示各光伏电站的光伏出力值,xn表示联合出力,已知各光伏电站的单点光伏出力的情况下,联合出力xn的条件概率密度函数f(xn|x1,x2,···,xn-1)计算公式为:
式中:cn-i,n|1,2,···,n-i-1是pair-copula函数,f(xn)是联合出力xn的概率密度函数;
联合出力计算步骤:求解各类光伏发电站的光伏出力值的预测值,设光伏出力实际值为x,光伏出力预测值为y,基于copula理论,得到两者的联合概率密度函数:
式中,fx,y(x,y)表示光伏出力x和y的联合概率密度函数;
fx,y(x,y)为光伏出力x和y的联合分布函数;
fx(x)和fy(y)分别为x和y的边缘概率分布函数;
c(fx(x),fy(y))为copula概率密度函数。
根据本发明提供的一种基于pair-copula理论的多点光伏出力概率预测系统,包括:
聚类模块:对光伏电站群进行聚类,确定最佳聚类数目;
统计模块:基于最佳聚类数目,对光伏电站群进行分类,得到多个聚类电站,统计各聚类电站的光伏出力值和联合出力,得到单点光伏出力的概率预测结果;
参数识别模块:对单点光伏处理概率预测结果进行二维copula函数的参数识别,得到偏相关系数;
求解模块:根据偏相关系数,求解pair-copula函数的相关性参数;
预测模块:利用pair-copula函数和单点光伏出力的概率预测结果,得到多点光伏出力的概率预测结果。
优选地,所述聚类模块包括:
特征归一模块:选取n个光伏电站的特征指标,将不同量纲和数量级的特征指标的指标数据进行标准化处理,采用以下公式:
其中,x*为归一化后的指标数据,x为实际指标数据,max为光伏电站群的指标数据中的最大值,min为光伏电站群的指标数据中的最小值;
计算聚类中心模块:随机选取k个光伏电站的特征指标作为聚类中心,记为第一聚类中心,按照欧式距离将剩余n-k个光伏电站归类到第一聚类中心的所在簇,计算剩余n-k个光伏电站的聚类中心,记为第二聚类中心;
阈值判断模块:判断第二聚类中心与第一聚类中心之间的欧式距离是否小于设定阈值,若小于,则将第二聚类中心的所在簇对应的光伏电站确定为同类变电站,否则,则将第二聚类中心的所在簇对应的光伏电站确定为不同类变电站;
确定最佳聚类数模块:计算聚类数目为k时的组内平方误差和,根据calinsky准则确定最佳聚类数目,其中calinsky的计算公式为:
式中:ssb为组与组之间的方差,ssw为组内方差,n为样本数,k为聚类数目,当calinsky最大时,选取k为最佳聚类数目。
优选地,所述统计模块包括:
分类模块:根据最佳聚类数目对光伏电站群进行分类,得到多个聚类电站,取各聚类电站中各光伏电站的光伏出力平均值作为该聚类电站的光伏出力值,记为xi,联合出力记为xk+1,对应的累积分布分别为{fi(xi),fk+1(xk+1)};
计算模块:分别计算聚类电站中各光伏电站的光伏出力值,使用beta函数描述光伏电站的预测值和实际值的变化趋势,所述beta分布概率密度函数为:
式中,f(x:a,b)表示随机变量x在参数为a和b时的beta分布概率密度函数;
x表示随机变量;
a、b分别表示beta函数的形状参数,a>0,b>0;
b(a,b)为beta函数;
概率计算模块:基于pair-copula理论得到联合出力的条件密度概率函数,计算公式为:
式中,v表示n维随机向量;
x表示随机变量;
vj表示v中的一个元素;
v-j表示除去vj后的剩余项;
f(x|v)表示条件v下变量x的条件概率密度函数;
f(x|v-j)表示条件v-j下变量x的条件边缘密度函数;
f(vj|v-j)表示条件v-j下变量vj的条件边缘密度函数;
优选地,所述求解模块中,pajr-copula函数的相关性参数通过以下公式求取:
式中:ρj,j+i|1,···,j-1是给定各光伏电站的出力(x1,x2,···,xj-1)时,xj和xj+i的偏相关系数;
ρj-1,j|1,···,j-2是给定各光伏电站的出力(x1,x2,···,xj-2)时xj-1和xj的偏相关系数;
下标i,j分别用以标识光伏发电站,其中1≤i≤n-j,1≤j≤n-1,n为光伏发电站总个数;
xj表示聚类电站的第j个光伏电站的光伏出力值;
xj+i表示聚类电站的第j+i个光伏电站的光伏出力值;
xj-1表示聚类电站的第j-1个光伏电站的光伏出力值。
优选地,所述预测模块包括:
总出力计算模块:对于(n-1)个光伏电站,(x1,x2,…,xn-1)表示各光伏电站的光伏出力值,xn表示联合出力,已知各光伏电站的单点光伏出力的情况下,联合出力xn的条件概率密度函数f(xn|x1,x2,···,xn-1)计算公式为:
式中:cn-i,n|1,2,···,n-i-1是pair-copula函数,f(xn)是联合出力xn的概率密度函数;
联合出力计算模块:求解各类光伏发电站的光伏出力值的预测值,设光伏出力实际值为x,光伏出力预测值为y,基于copula理论,得到两者的联合概率密度函数:
式中,fx,y(x,y)表示光伏出力x和y的联合概率密度函数;
fx,y(x,y)为光伏出力x和y的联合分布函数;
fx(x)和fy(y)分别为x和y的边缘概率分布函数;
c(fx(x),fy(y))为copula概率密度函数。
与现有技术相比,本发明具有如下的有益效果:
1、本发明在对多个光伏电站进行聚类分析的基础上,根据聚类分析的结果进行多点分布式光伏联合出力的预测,并引入pair-copula理论用一系列二维copula函数逐层合并表示出多维copula函数,克服了copula理论在高维建模时函数形式难以确定的困难,解决了多点分布式光伏联合出力的预测的问题;
2、本发明通过聚类分析对多个光伏电站进行分类,分类结果可以验证不同电站之间相关性的强弱,具有较强实用价值;
3、本发明设计思路清晰,使用方式较为简便,在工程实际中,具有广泛的适用性。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为组内平方误差和分析结果示意图;
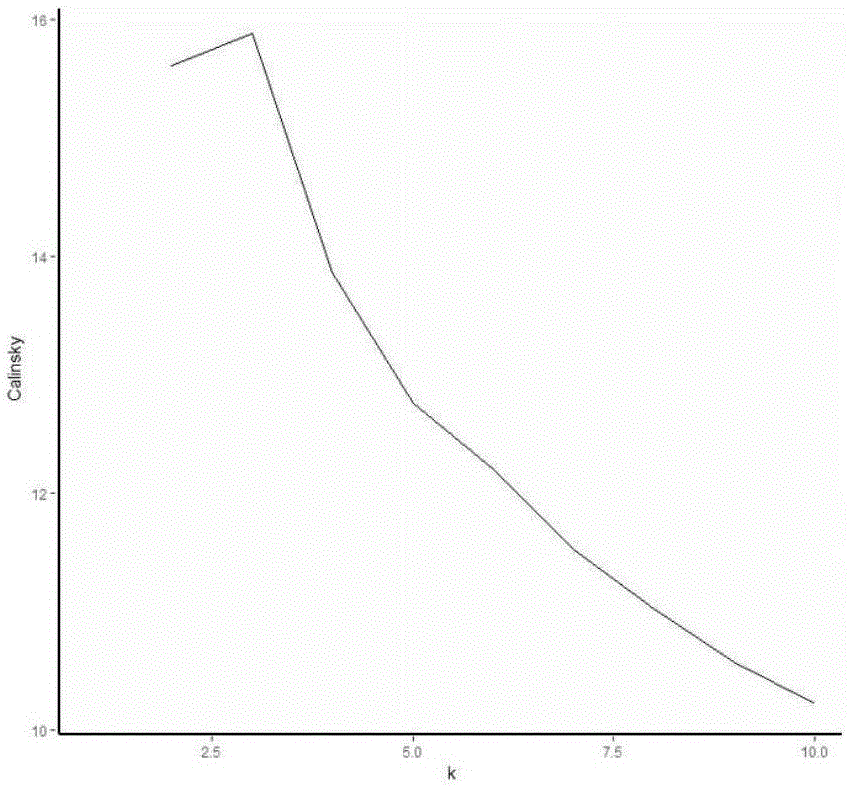
图2为calinsky分析结果示意图;
图3为聚类分析结果示意图;
图4为本发明在2018年1月31日6时预测结果示意图;
图5为本发明在2018年1月31日7时预测结果示意图;
图6为本发明在2018年1月31日9时预测结果示意图;
图7为本发明在2018年1月31日14时预测结果示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本发明提出了一种基于pair-copula理论的多点光伏出力概率预测方法,该方法基于大规模光伏电站接入电网的现状,提出了针对多点光伏联合出力的预测模型;考虑到不同电站所处空间的相关性,本发明引入聚类分析理论对光伏电站进行分类,详细介绍了最佳聚类确定的过程;考虑到高维copula函数建模的困难,基于pair-copula理论建立联合出力的条件概率预测模型,解决了多点分布式光伏联合出力的预测问题。
根据本发明提供的一种基于pair-copula理论的多点光伏出力概率预测方法,包括:
聚类步骤:对光伏电站群进行聚类,确定最佳聚类数目;
统计步骤:基于最佳聚类数目,对光伏电站群进行分类,得到多个聚类电站,统计各聚类电站的光伏出力值和联合出力,得到单点光伏出力的概率预测结果;
参数识别步骤:对单点光伏处理概率预测结果进行二维copula函数的参数识别,得到偏相关系数;
求解步骤:根据偏相关系数,求解pair-copula函数的相关性参数;
预测步骤:利用pair-copula函数和单点光伏出力的概率预测结果,得到多点光伏出力的概率预测结果。
具体地,所述聚类步骤包括:
特征归一步骤:选取n个光伏电站的特征指标,将不同量纲和数量级的特征指标的指标数据进行标准化处理,采用以下公式:
其中,x*为归一化后的指标数据,x为实际指标数据,max为光伏电站群的指标数据中的最大值,min为光伏电站群的指标数据中的最小值;
计算聚类中心步骤:随机选取k个光伏电站的特征指标作为聚类中心,记为第一聚类中心,按照欧式距离将剩余n-k个光伏电站归类到第一聚类中心的所在簇,计算剩余n-k个光伏电站的聚类中心,记为第二聚类中心;
阈值判断步骤:判断第二聚类中心与第一聚类中心之间的欧式距离是否小于设定阈值,若小于,则将第二聚类中心的所在簇对应的光伏电站确定为同类变电站,否则,则将第二聚类中心的所在簇对应的光伏电站确定为不同类变电站;
确定最佳聚类数步骤:计算聚类数目为k时的组内平方误差和,根据calinsky准则确定最佳聚类数目,其中calinsky的计算公式为:
式中:ssb为组与组之间的方差,ssw为组内方差,n为样本数,k为聚类数目,当calinsky最大时,选取k为最佳聚类数目。
具体地,所述统计步骤包括:
分类步骤:根据最佳聚类数目对光伏电站群进行分类,得到多个聚类电站,取各聚类电站中各光伏电站的光伏出力平均值作为该聚类电站的光伏出力值,记为xi,联合出力记为xk+1,对应的累积分布分别为{fi(xi),fk+1(xk+1)};
计算步骤:分别计算聚类电站中各光伏电站的光伏出力值,使用beta函数描述光伏电站的预测值和实际值的变化趋势,所述beta分布概率密度函数为:
式中,f(x:a,b)表示随机变量x在参数为a和b时的beta分布概率密度函数;
x表示随机变量;
a、b分别表示beta函数的形状参数,a>0,b>0;
b(a,b)为beta函数;
概率计算步骤:基于pair-copula理论得到联合出力的条件密度概率函数,计算公式为:
式中,v表示n维随机向量;
x表示随机变量;
vj表示v中的一个元素;
v-j表示除去vj后的剩余项;
f(x|v)表示条件v下变量x的条件概率密度函数;
f(x|v-j)表示条件v-j下变量x的条件边缘密度函数;
f(vj|v-j)表示条件v-j下变量vj的条件边缘密度函数;
具体地,所述求解步骤中,pair-copula函数的相关性参数通过以下公式求取:
式中:ρj,j+i|1,···,j-1是给定各光伏电站的出力(x1,x2,…,xj-1)时,xj和xj+i的偏相关系数;
ρj-1,j|1,···,j-2是给定各光伏电站的出力(x1,x2,···,xj-2)时xj-1和xj的偏相关系数;
下标i,j分别用以标识光伏发电站,其中1≤i≤n-j,1≤j≤n-1,n为光伏发电站总个数;
xj表示聚类电站的第j个光伏电站的光伏出力值;
xj+i表示聚类电站的第j+i个光伏电站的光伏出力值;
xj-1表示聚类电站的第j-1个光伏电站的光伏出力值。
具体地,所述预测步骤包括:
总出力计算步骤:对于(n-1)个光伏电站,(x1,x2,…,xn-1)表示各光伏电站的光伏出力值,xn表示联合出力,已知各光伏电站的单点光伏出力的情况下,联合出力xn的条件概率密度函数f(xn|x1,x2,···,xn-1)计算公式为:
式中:cn-i,n|1,2,···,n-i-1是pair-copula函数,f(xn)是联合出力xn的概率密度函数;
联合出力计算步骤:求解各类光伏发电站的光伏出力值的预测值,设光伏出力实际值为x,光伏出力预测值为y,基于copula理论,得到两者的联合概率密度函数:
式中,fx,y(x,y)表示光伏出力x和y的联合概率密度函数;
fx,y(x,y)为光伏出力x和y的联合分布函数;
fx(x)和fy(y)分别为x和y的边缘概率分布函数;
c(fx(x),fy(y))为copula概率密度函数。
根据本发明提供的一种基于pair-copula理论的多点光伏出力概率预测系统,包括:
聚类模块:对光伏电站群进行聚类,确定最佳聚类数目;
统计模块:基于最佳聚类数目,对光伏电站群进行分类,得到多个聚类电站,统计各聚类电站的光伏出力值和联合出力,得到单点光伏出力的概率预测结果;
参数识别模块:对单点光伏处理概率预测结果进行二维copula函数的参数识别,得到偏相关系数;
求解模块:根据偏相关系数,求解pair-copula函数的相关性参数;
预测模块:利用pair-copula函数和单点光伏出力的概率预测结果,得到多点光伏出力的概率预测结果。
具体地,所述聚类模块包括:
特征归一模块:选取n个光伏电站的特征指标,将不同量纲和数量级的特征指标的指标数据进行标准化处理,采用以下公式:
其中,x*为归一化后的指标数据,x为实际指标数据,max为光伏电站群的指标数据中的最大值,min为光伏电站群的指标数据中的最小值;
计算聚类中心模块:随机选取k个光伏电站的特征指标作为聚类中心,记为第一聚类中心,按照欧式距离将剩余n-k个光伏电站归类到第一聚类中心的所在簇,计算剩余n-k个光伏电站的聚类中心,记为第二聚类中心;
阈值判断模块:判断第二聚类中心与第一聚类中心之间的欧式距离是否小于设定阈值,若小于,则将第二聚类中心的所在簇对应的光伏电站确定为同类变电站,否则,则将第二聚类中心的所在簇对应的光伏电站确定为不同类变电站;
确定最佳聚类数模块:计算聚类数目为k时的组内平方误差和,根据calinsky准则确定最佳聚类数目,其中calinsky的计算公式为:
式中:ssb为组与组之间的方差,ssw为组内方差,n为样本数,k为聚类数目,当calinsky最大时,选取k为最佳聚类数目。
具体地,所述统计模块包括:
分类模块:根据最佳聚类数目对光伏电站群进行分类,得到多个聚类电站,取各聚类电站中各光伏电站的光伏出力平均值作为该聚类电站的光伏出力值,记为xi,联合出力记为xk+1,对应的累积分布分别为{fi(xi),fk+1(xk+1)};
计算模块:分别计算聚类电站中各光伏电站的光伏出力值,使用beta函数描述光伏电站的预测值和实际值的变化趋势,所述beta分布概率密度函数为:
式中,f(x:a,b)表示随机变量x在参数为a和b时的beta分布概率密度函数;
x表示随机变量;
a、b分别表示beta函数的形状参数,a>0,b>0;
b(a,b)为beta函数;
概率计算模块:基于pair-copula理论得到联合出力的条件密度概率函数,计算公式为:
式中,v表示n维随机向量;
x表示随机变量;
vj表示v中的一个元素;
v-j表示除去vj后的剩余项;
f(x|v)表示条件v下变量x的条件概率密度函数;
f(x|v-j)表示条件v-j下变量x的条件边缘密度函数;
f(vj|v-j)表示条件v-j下变量vj的条件边缘密度函数;
具体地,所述求解模块中,pair-copula函数的相关性参数通过以下公式求取:
式中:ρj,j+i|1,···,j-1是给定各光伏电站的出力(x1,x2,…,xj-1)时,xj和xj+i的偏相关系数;
ρj-1,j|1,···,j-2是给定各光伏电站的出力(x1,x2,···,xj-2)时xj-1和xj的偏相关系数;
下标i,j分别用以标识光伏发电站,其中1≤i≤n-j,1≤j≤n-1,n为光伏发电站总个数;
xj表示聚类电站的第j个光伏电站的光伏出力值;
xj+i表示聚类电站的第j+i个光伏电站的光伏出力值;
xj-1表示聚类电站的第j-1个光伏电站的光伏出力值。
具体地,所述预测模块包括:
总出力计算模块:对于(n-1)个光伏电站,(x1,x2,…,xn-1)表示各光伏电站的光伏出力值,xn表示联合出力,已知各光伏电站的单点光伏出力的情况下,联合出力xn的条件概率密度函数f(xn|x1,x2,···,xn-1)计算公式为:
式中:cn-i,n|1,2,···,n-i-1是pair-copula函数,f(xn)是联合出力xn的概率密度函数;
联合出力计算模块:求解各类光伏发电站的光伏出力值的预测值,设光伏出力实际值为x,光伏出力预测值为y,基于copula理论,得到两者的联合概率密度函数:
式中,fx,y(x,y)表示光伏出力x和y的联合概率密度函数;
fx,y(x,y)为光伏出力x和y的联合分布函数;
fx(x)和fy(y)分别为x和y的边缘概率分布函数;
c(fx(x),fy(y))为copula概率密度函数。
本发明提供的基于pair-copula理论的多点光伏出力概率预测系统,可以通过基于pair-copula理论的多点光伏出力概率预测方法的步骤流程实现。本领域技术人员可以将基于pair-copula理论的多点光伏出力概率预测方法理解为所述基于pair-copula理论的多点光伏出力概率预测系统的优选例。
在另一优选例中,基于pair-copula理论的多点光伏出力概率预测方法,包括以下步骤:
(1)对目标光伏电站群进行聚类分析,确定最佳类数;
(2)统计各类电站的光伏出力值和光伏电站群总出力值,得到各自的概率密度函数和累积分布函数;
(3)对各类电站出力及总出力进行二维copula函数的参数识别,得到一系列偏相关系数;
(4)根据公式求解pair-copula函数的相关系数;
(5)利用已经确定的pair-copula模型和各电站光伏出力的预测值,得到多点分布式光伏联合出力的条件概率分布。
所述步骤(1)中,具体实施方法如下:
确定目标光伏变电站,并对其进行聚类分析以确定最佳类数。具体过程如下:
步骤(1-1):选取n个光伏变电站的特征指标,并将不同量纲和数量级的指标数据进行标准化,公式如下:
其中,x*为归一化后的指标数据,x为实际指标数据,max为所有变电站指标数据中的最大值,min为所有变电站指标数据中的最小值;
步骤(1-2):取聚类数k从1到n,随机选取k个变电站特征数据作为聚类中心,按照欧式距离将其余变电站归类到聚类中心所在簇,并计算新的聚类中心;
步骤(1-3):判断新的聚类中心与原有的聚类中心之间的欧式距离是否小于预设的阈值;
步骤(1-4):若所述新的聚类中心与原有的聚类中心之间的欧式距离小于预设的阈值,则确定所述新的聚类中心所在簇对应变电站为同类变电站;
步骤(1-5):计算聚类数为k时的组内平方误差,并结合calinsky准则确定最佳聚类数,其中calinsky的计算公式为:
式中:ssb为组与组之间的方差,ssw为组内方差,n为样本数,k为聚类数。ssb越大,ssw越小,聚类效果越好,故calinsky越大,聚类效果越好。
所述步骤(2)中,具体实施方法如下:
统计各类电站的光伏出力值和光伏电站群总出力值,得到各自的概率密度函数和累积分布函数。
步骤(2-1):按照步骤(1)中所得到的最佳聚类数对所有光伏变电站进行分类,,取每一类各个电站光伏出力的平均值作为该类光伏电站出力值,记为xi,联合出力记为xk+1,对应的累积分布分别为{fi(xi),fk+1(xk+1)}。
步骤(2-2):分别计算各类光伏发电站的出力值,使用beta模型描述光伏电站的预测值和实际值的变化趋势,beta分布的概率密度函数为:
式中,x为随机变量,a(a>0)和b(b>0)为beta分布函数的形状参数,;b(a,b)为beta函数。
步骤(2-3):基于pair-copula理论得到联合出力的条件密度概率函数,计算公式为:
式中,v表示n维随机向量,vj表示其中一个元素,v-j表示除去vj后的剩余项。
所述步骤(3)中,具体实施方法如下:
选择kendall秩相关系数描述各类电站出力及总出力的相关性,得到二维copula函数的参数。
所述步骤(4)中,具体实施方法如下:
通过以下公式求取pair-copula函数的相关性参数ρ:
式中:ρj,j+i|1,···,j-1是给定(x1,x2,…,xj-1)时xj和xj+i的偏相关系数,ρj-1,j|1,···,j-2是给定(x1,x2,···,xj-2)时xj-1和xj的偏相关系数。
所述步骤(5)中,具体实施方法如下:
利用已经确定的pair-copula模型和各电站光伏出力的预测值,得到多点分布式光伏联合出力的条件概率分布。
步骤(5-1):对于(n-1)个光伏电站,(x1,x2,…,xn-1)表示各个光伏电站的出力,xn表示总出力,已知各光伏电站单独出力的情况下,总出力xn的条件概率密度函数计算公式为:
式中:cn-i,n|1,2,···,n-i-1是pair-copula函数,f(xn)是总出力xn的概率密度函数。
步骤(5-2):求解各类光伏发电站光伏出力的预测值,设光伏出力实际值为x,光伏出力预测值为y,基于copula理论,可以写出两者的联合概率密度函数:
式中,fx,y(x,y)为光伏出力x和y的联合分布函数,fx(x)和fy(y)分别为x和y的边缘概率分布函数,c(fx(x),fy(y))为copula概率密度函数。其中,光伏出力实际值和预测值的概率密度函数和分布函数可以对历史光伏出力数据以及历史光伏出力点预测值统计得到,copula概率密度函数可以通过历史光伏出力实际值和预测值的拟合得到。
下面结合附图与实施例对本发明作进一步说明。
步骤(1)基于2014年全球能源预测竞赛所提供的数据进行53所光伏变电站的聚类分析,确定最佳数。
表1不同聚类数下的calinsky值
calinsky分析结果表明:当聚类数为3时,calinsky达到最大值。最佳聚类数为3时,聚类结果如下:
表2聚类分析结果
步骤(2)基于bp神经网络和copula理论得到光伏发电功率的条件概率分布。
表3单点光伏出力概率预测结果
步骤(3)基于copula理论,计算二维copula函数的偏相关系数。
表4二维copula函数偏相关系数
步骤(4)根据偏相关系数,求解pair-copula函数的相关系数。
步骤(5)得到模型预测结果,并与实际值进行比较。
表5二维copula函数偏相关系数
本发明方法的平均百分误差仅为5.28%。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!