一种光伏电站的异常数据检测方法、装置及电子设备与流程
本发明涉及光伏电站数据处理领域,更具体的说,涉及一种光伏电站的异常数据检测方法、装置及电子设备。
背景技术:
分布式光伏发电与大电网结合的方式在节省投资、降低能耗、提高电力系统稳定性和灵活性等方面具有很大优势。
目前,分布式光伏发电站地理位置分散,存在着电站的运行情况监测较难,故障处理不及时等情况,如果能够及时检测到分布式光伏发电站的异常数据,就可以提高分布式光伏发电站的监控能力以及故障处理能力,确保电力系统的稳定性和安全性。
技术实现要素:
有鉴于此,本发明提供一种光伏电站的异常数据检测方法、装置及电子设备,以解决亟需检测分布式光伏发电站的异常数据的问题。
为解决上述技术问题,本发明采用了如下技术方案:
一种光伏电站的异常数据检测方法,包括:
获取至少一个光伏残差数据;
计算所述光伏残差数据对应的密度值和距离值;
筛选出对应的密度值和距离值符合预设条件的光伏残差数据,并作为至少一个光伏残差数据的聚类中心点;
基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果;
将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
可选地,计算所述光伏残差数据对应的密度值,包括:
获取光伏残差数据阈值;
利用
可选地,所述计算所述光伏残差数据对应的距离值,包括:
对于每一所述光伏残差数据,确定对应的密度值大于所述光伏残差数据对应的密度值的光伏残差数据的集合;
依据
可选地,所述预设条件包括密度值大于所有的所述光伏残差数据对应的密度值的平均值、且距离值大于所有的所述光伏残差数据对应的距离值的平均值。
可选地,获取至少一个光伏残差数据,包括:
获取至少一个电站的实际运行数据和预测运行数据;
将同一所述电站对应的所述实际运行数据和所述预测运行数据做差,得到所述电站对应的光伏残差数据。
可选地,获取至少一个电站的预测运行数据,包括:
获取上一数据采集时刻的预测运行数据、权重值、以及采集的实际运行数据;
依据st=ayt-1+(1-a)st-1公式,计算得到所述电站的预测运行数据;其中,a为权重值;yt-1为上一数据采集时刻采集的实际运行数据;st-1为上一数据采集时刻的预测运行数据。
一种光伏电站的异常数据检测装置,包括:
数据获取模块,用于获取至少一个光伏残差数据;
数值计算模块,用于计算所述光伏残差数据对应的密度值和距离值;
数据筛选模块,用于筛选出对应的密度值和距离值符合预设条件的光伏残差数据,并作为至少一个光伏残差数据的聚类中心点;
聚类模块,用于基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果;
异常数据确定模块,用于将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
可选地,所述数值计算模块用于计算所述光伏残差数据对应的密度值时,具体用于:
获取光伏残差数据阈值,利用
可选地,所述数值计算模块用于计算所述光伏残差数据对应的距离值时,具体用于:
对于每一所述光伏残差数据,确定对应的密度值大于所述光伏残差数据对应的密度值的光伏残差数据的集合,依据
一种电子设备,包括:存储器和处理器;
其中,所述存储器用于存储程序;
处理器调用程序并用于:
获取至少一个光伏残差数据;
计算所述光伏残差数据对应的密度值和距离值;
筛选出对应的密度值和距离值符合预设条件的光伏残差数据,并作为至少一个光伏残差数据的聚类中心点;
基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果;
将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
相较于现有技术,本发明具有以下有益效果:
本发明提供了一种光伏电站的异常数据检测方法、装置及电子设备,在获取到电站对应的光伏残差数据之后,会依据光伏残差数据,确定所述光伏残差数据的聚类中心点,然后基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果,将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据,通过本发明,可以确定出异常数据,进而在出现异常数据时,及时进行故障处理能力,确保电力系统的稳定性和安全性。进一步的,本发明通过密度值和距离值两个维度数据来确定聚类中心点,进而使得确定的聚类中心点更准确,进而使用该聚类中心点得到的聚类结果更加准确,确定出的异常数据也更加准确。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的一种光伏电站的异常数据检测方法的方法流程图;
图2为本发明实施例提供的一种光伏残差数据的分布图;
图3为本发明实施例提供的另一种光伏电站的异常数据检测方法的方法流程图;
图4为本发明实施例提供的一种光伏残差数据对应的密度和距离的分布图;
图5为本发明实施例提供的一种光伏电站的异常数据检测装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
分布式光伏发电站地理位置分散,可能在多个地点均分布有光伏发电站,为了监测处于不同位置的光伏发电站中的异常数据,发明人发现可以通过一种基于三次指数平滑和dbscan的数据异常检测模型来检测异常数据。数据异常检测模型主要由三次指数平滑模型和dbscan(density-basedspatialclusteringofapplicationswithnoise,聚类算法)聚类算法两部分组成。三次指数平滑模型对输入的用电量数据序列进行时序建模,逐时刻预测,获取每个时刻对应的用电量预测值。然后采用dbscan聚类算法对用电量数据真实值和预测值的残差项进行聚类分析,从而实现对异常数据点的检测。具体的,人工参考真实值与预测值的残差项,依据经验确定出聚类中心点,然后使用该聚类中心点进行聚类,得到聚类结果,将该聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
但是,发明人发现,基于dbscan数据聚类的异常检测技术在确定聚类中心点时采用人工确定的方式,若人工确定的聚类中心点不准确,在数据聚类的密度不均匀、聚类间距相差很大的场景下,使用不准确的聚类中心点会会导致最小包含数minpts和扫描半径eps选取困难。进而最终导致聚类结果不准确,即聚类质量较差,进而导致筛选出的异常数据不准确。若应用在电力数据异常检测中,则会导致无法快速准确的对异常数据进行检测区分,数据处理的准确性和实时性提升效果不太显著。
为了解决由于人工确定聚类中心点的方式导致聚类中心点选取错误,进而导致聚类失败、异常数据检测失误,本发明的发明人提出了一种基于cfsfdp(clusteringbyfastsearchandfindofdensitypeaks,基于密度峰值的快速聚类算法)算法来确定聚类中心点并进行异常数据的筛选,在确定聚类中心点时,综合考虑密度和距离两个影响因素,采用密度因素可以使得相似的数据聚类到一起,采用距离因素可以使得两个聚类中心点的距离足够远,进而使得两个聚类簇的差异性更大,提高了某一数据应该落入哪一聚类簇的准确性。从而能够更快更准确的确定出聚类中线点,然后基于聚类中心点进行聚类计算,得到异常数据,会使得确定的异常数据更加准确。
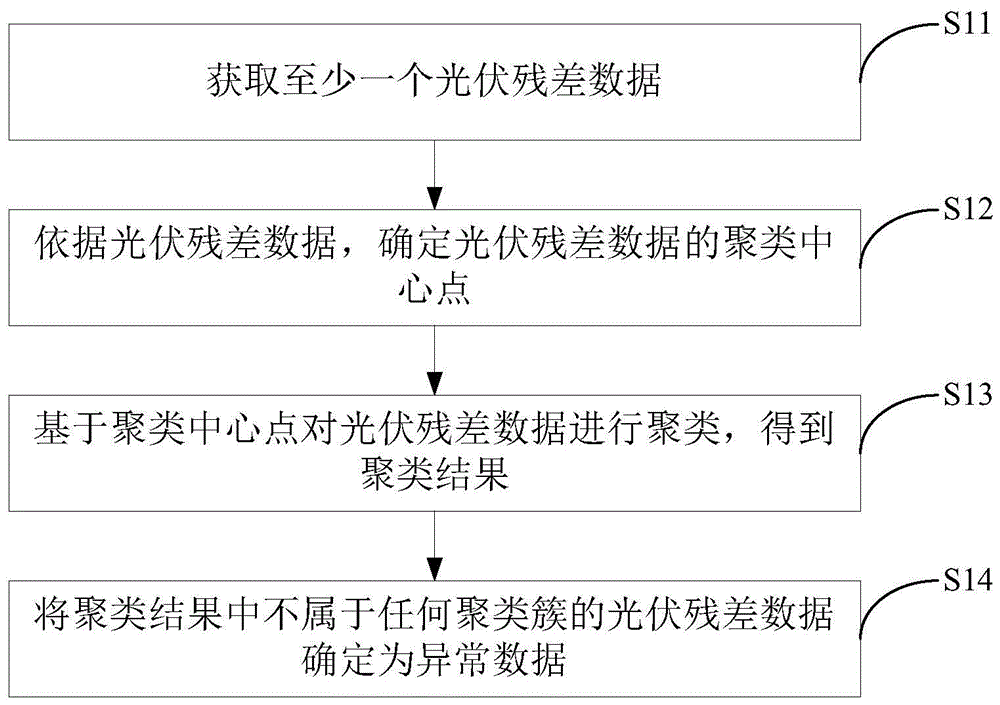
具体的,参照图1,光伏电站的异常数据检测方法可以包括:
s11、获取至少一个光伏残差数据。
分布式光伏发电站分布广泛,如可以在a、b、c、d、e、f等地点分别设置一光伏发电站,为了监测同一时刻哪一光伏发电站监测的数据为异常数据,提出了本发明实施例中的异常数据检测方法,此时需要采集每一电站采集的实际运行数据,如采集辐照度、环境温度、相对湿度等环境数据,采集发电量、有功功率、交流电压、交流电流、直流电压、直流电流、逆变器机内温度和对地绝缘阻抗等数据。本实施例中以同时采集辐照度和环境温度为例进行说明。
假设有23个光伏发电站,每一光伏发电站采集当前时刻的环境温度和辐照度,其中,每一光伏发电站采集当前时刻的环境温度和辐照度可以组成一向量,则23个光伏发电站则对应23个向量,每一向量即为一实际运行数据。
采集了实际运行数据之后,还需要对实际运行数据进行数据清洗,清洗脏数据,数据清洗可以包括:
第一步:首先是缺失值清洗,包括确认缺失值范围、去除不需要字段、填充缺失内容、重新取数四个阶段。
第二步:格式内容清洗,包括调节显示格式不一致、内容与该字段应有内容不符两个阶段。
第三步:逻辑错误清洗,包括去重、去除不合理值、修正矛盾内容三个阶段。
第四步:关联性验证,对多个数据来源进行关联性验证,力求多数据源之前无矛盾数据。
实际运行数据采集得到后,还需要确定当前时刻的预测运行数据,此时可以采用指数平滑算法进行预测运行数据的计算,所述预测运行数据st的计算公式为:
st=ayt-1+(1-a)st-1;其中,a为权重值;yt-1为上一数据采集时刻的实际运行数据;st-1为上一数据采集时刻的预测运行数据。
通过上述公式可以确定出每一电站对应的当前时刻的预测运行数据,即可以得到23个电站对应的当前时刻的预测运行数据。
需要说明的是,每隔固定时间,如5秒、10秒、1分钟等检测一次数据,则上一数据采集时刻即为当前时刻的上一数据采集时刻,如固定时间为5秒,则上一数据采集时刻为5秒前。a为权重值,是技术人员根据具体数据检测场景进行设定的,在此不做具体数值限定。
若实际运行数据为两个,如环境温度和辐照度,则预测运行数据中的环境温度和辐照度依据上述公式分开进行计算,分别计算得到环境温度和辐照度对应的预测数据,然后组成包括环境温度和辐照度的一个向量,作为预测运行数据。
得到每一电站对应的实际运行数据和所述预测运行数据之后,将同一所述电站对应的所述实际运行数据和所述预测运行数据做差,得到所述电站对应的光伏残差数据。得到做差结果之后,取差值绝对值作为最终的光伏残差数据。
若上述的电站数量为23个,则可以得到23个光伏残差数据,也即得到23个光伏残差向量,光伏残差数据的场景示意图可以参照图2。图2中,横坐标和纵坐标可以表示温度差值和光照差值。共有23个圆圈,每一圆圈代表一光伏残差数据。
从图2中可以看出,点23光伏残差数据离其他光伏残差数据较远,有很大可能性为异常数据。
s12、依据所述光伏残差数据,确定所述光伏残差数据的聚类中心点。
s13、基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果。
其中,聚类中心点即为在进行数据聚类时使用的中心点,在得到多个光伏残差数据之后,使用聚类中心点进行聚类,可以得到多个聚类簇,即可作为聚类结果。
在进行聚类时,可以采用dbscan算法、k-means算法、改进的knn算法等算法进行聚类。如以改进的knn算法为例,设定相应的密度阈值(也可以称为扫描半径)eps,对光伏残差数据进行聚类,即可得到聚类结果。
s14、将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
在实际应用中,不属于任何聚类簇的光伏残差数据即为异常数据。得到异常数据之后,将异常数据推送给给监控系统,供光伏运维人员查看决策,及时处理故障。
本实施例中,在获取到电站对应的光伏残差数据之后,会依据光伏残差数据,确定所述光伏残差数据的聚类中心点,然后基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果,将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据,通过本发明,可以确定出异常数据,进而在出现异常数据时,及时进行故障处理能力,确保电力系统的稳定性和安全性。进一步的,本发明通过密度值和距离值两个维度数据来确定聚类中心点,进而使得确定的聚类中心点更准确,进而使用该聚类中心点得到的聚类结果更加准确,确定出的异常数据也更加准确。
上述提出了“依据所述光伏残差数据,确定所述光伏残差数据的聚类中心点”,现对其具体实现过程进行详细介绍。具体的,参照图3,步骤s12可以包括:
s21、计算所述光伏残差数据对应的密度值和距离值。
本实施例中,采用cfsfdp算法确定聚类中心点,在确定聚类中心点时,需要确定每一光伏残差数据对应的密度值和距离值。
在实际应用中,密度值与所述光伏残差数据与除所述光伏残差数据之外的所有的光伏残差数据之间的欧式距离相关。具体的,密度值ρi的计算公式为:
在确定出密度值ρi之后,继续确定光伏残差数据的距离值σi,距离值与所述光伏残差数据的密度值、以及所述光伏残差数据与除所述光伏残差数据之外的所有的光伏残差数据之间的欧式距离相关;具体的,
其中,对于一光伏残差数据,is为对应的密度值大于该光伏残差数据对应的密度值的光伏残差数据的集合,若is不为空集,则将该光伏残差数据与is中的光伏残差数据的最小的欧式距离作为σi,若is为空集,则将该光伏残差数据与所有的光伏残差数据的最大的欧式距离作为σi。
s22、筛选出对应的密度值和距离值符合预设条件的光伏残差数据,并作为所述聚类中心点。
确定出每一光伏残差数据的密度值和距离值之后,判断每一光伏残差数据对应的密度值和距离值是否符合预设条件,预设条件可以是密度值大于所有的所述光伏残差数据对应的密度值的平均值、且距离值大于所有的所述光伏残差数据对应的距离值的平均值。也就是说,筛选出密度值和距离值均比较大的光伏残差数据,这些数据即为聚类中心点。
参照图4,在得到每一光伏残差数据的密度值和距离值之后,可以构建ρ与σ的二维图,从二维图中筛选出密度值和距离值均比较大的点,如14和19,即为聚类中心点。另外,图4中的23号点距离坐标σ轴更近,距离ρ轴更远,这个点即判定为异常点。通过聚类算法也可以筛选出23号点,该算法较现有异常检测算法而言,精度更高、运算速度更快。
本实施例中,利用基于密度与距离的cfsfdp聚类算法,通过分析离群点周围密度低和离群点距中心点远的两个特性,采用密度因素可以使得相似的数据聚类到一起,采用距离因素可以使得两个聚类中心点的距离足够远,进而使得两个聚类簇的差异性更大,提高了某一数据应该落入哪一聚类簇的准确性。即通过本发明实施例可以快速的找到离群点,即异常数据。相比于单一基于密度或单一基于距离的数据异常检测算法。一方面尽可能不破坏电力原始数据之间的关联性,另一方面降低数据的维度和复杂度,实现异常数据的准确检测,从而确保电力大数据网络的安全态势,使得异常检测的结果更加准确,运算速度更加高效。
可选地,在上述异常数据检测方法的实施例的基础上,本发明的另一实施例提供了一种光伏电站的异常数据检测装置,参照图5,可以包括:
数据获取模块11,用于获取至少一个光伏残差数据;
数值计算模块12,用于计算所述光伏残差数据对应的密度值和距离值;
数据筛选模块13,用于筛选出对应的密度值和距离值符合预设条件的光伏残差数据,并作为至少一个光伏残差数据的聚类中心点;
聚类模块14,用于基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果;
异常数据确定模块15,用于将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
进一步,所述数值计算模块用于计算所述光伏残差数据对应的密度值时,具体用于:
获取光伏残差数据阈值,利用
进一步,所述数值计算模块用于计算所述光伏残差数据对应的距离值时,具体用于:
对于每一所述光伏残差数据,确定对应的密度值大于所述光伏残差数据对应的密度值的光伏残差数据的集合,依据
进一步,所述预设条件包括密度值大于所有的所述光伏残差数据对应的密度值的平均值、且距离值大于所有的所述光伏残差数据对应的距离值的平均值。
进一步,数据获取模块用于获取至少一个光伏残差数据时,具体用于:获取至少一个电站的实际运行数据和预测运行数据,将同一所述电站对应的所述实际运行数据和所述预测运行数据做差,得到所述电站对应的光伏残差数据。
进一步,获取至少一个电站的预测运行数据,包括:
获取上一数据采集时刻的预测运行数据、权重值、以及采集的实际运行数据,依据st=ayt-1+(1-a)st-1公式,计算得到所述电站的预测运行数据;其中,a为权重值;yt-1为上一数据采集时刻采集的实际运行数据;st-1为上一数据采集时刻的预测运行数据。
本实施例中,在获取到电站对应的光伏残差数据之后,会依据光伏残差数据,确定所述光伏残差数据的聚类中心点,然后基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果,将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据,通过本发明,可以确定出异常数据,进而在出现异常数据时,及时进行故障处理能力,确保电力系统的稳定性和安全性。进一步的,本发明通过密度值和距离值两个维度数据来确定聚类中心点,进而使得确定的聚类中心点更准确,进而使用该聚类中心点得到的聚类结果更加准确,确定出的异常数据也更加准确。
另外,利用基于密度与距离的cfsfdp聚类算法,通过分析离群点周围密度低和离群点距中心点远的两个特性,采用密度因素可以使得相似的数据聚类到一起,采用距离因素可以使得两个聚类中心点的距离足够远,进而使得两个聚类簇的差异性更大,提高了某一数据应该落入哪一聚类簇的准确性。即通过本发明实施例可以快速的找到离群点,即异常数据。相比于单一基于密度或单一基于距离的数据异常检测算法。一方面尽可能不破坏电力原始数据之间的关联性,另一方面降低数据的维度和复杂度,实现异常数据的准确检测,从而确保电力大数据网络的安全态势,使得异常检测的结果更加准确,运算速度更加高效。
需要说明的是,本实施例中的各个模块的工作过程,请参照上述实施例中的相应说明,在此不再赘述。
可选的,在上述异常数据检测方法及装置的实施例的基础上,本发明的另一实施例提供了一种电子设备,包括:存储器和处理器;
其中,所述存储器用于存储程序;
处理器调用程序并用于:
获取至少一个光伏残差数据;
计算所述光伏残差数据对应的密度值和距离值;
筛选出对应的密度值和距离值符合预设条件的光伏残差数据,并作为至少一个光伏残差数据的聚类中心点;
基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果;
将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据。
本实施例中,在获取到电站对应的光伏残差数据之后,会依据光伏残差数据,确定所述光伏残差数据的聚类中心点,然后基于所述聚类中心点对所述光伏残差数据进行聚类,得到聚类结果,将所述聚类结果中不属于任何聚类簇的光伏残差数据确定为异常数据,通过本发明,可以确定出异常数据,进而在出现异常数据时,及时进行故障处理能力,确保电力系统的稳定性和安全性。进一步的,本发明通过密度值和距离值两个维度数据来确定聚类中心点,进而使得确定的聚类中心点更准确,进而使用该聚类中心点得到的聚类结果更加准确,确定出的异常数据也更加准确。
另外,利用基于密度与距离的cfsfdp聚类算法,通过分析离群点周围密度低和离群点距中心点远的两个特性,采用密度因素可以使得相似的数据聚类到一起,采用距离因素可以使得两个聚类中心点的距离足够远,进而使得两个聚类簇的差异性更大,提高了某一数据应该落入哪一聚类簇的准确性。即通过本发明实施例可以快速的找到离群点,即异常数据。相比于单一基于密度或单一基于距离的数据异常检测算法。一方面尽可能不破坏电力原始数据之间的关联性,另一方面降低数据的维度和复杂度,实现异常数据的准确检测,从而确保电力大数据网络的安全态势,使得异常检测的结果更加准确,运算速度更加高效。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!