数据存储方法和系统与流程
本发明涉及存储领域,特别是涉及一种数据存储方法和系统。
背景技术:
在媒体自动化测试中,各种媒体信息都需要处理和保存,特别是音频和视频码流,数据量非常大。这些大量的数据超出了计算机的存储和处理能力,更是当前文件传输速率所不及的。如何有效地存储并且传输这些数据以及如何从这些数据中快速匹配到所需的信息都是用户面临的难题。因此,为了存储、处理和传输这些数据,必须采用一种高效的数据存储方法对数据进行压缩存储。
现有的适用于文本文件数据的压缩主要为无损压缩。而目前的无损压缩算法,都是基于在文件中找相同的、重复的序列进行压缩,即使对文本文件等重复性比较高的数据进行压缩,一般情况下,采用无损压缩,最大的压缩率只能达到70%左右,即压缩后的文件大小是原文件的30%左右。其压缩后的文件仍然占用较大的存储空间。
技术实现要素:
基于此,有必要针对现有的数据存储压缩方法压缩后的文件仍占用较大的存储空间的问题,提供一种数据存储方法和系统。
为实现本发明目的提供的一种数据存储方法,包括如下步骤:
解析媒体文件,获取所述媒体文件的媒体信息及第一码流数据,并保存所述媒体信息至第一预设文件;
采用哈希算法压缩方式压缩所述第一码流数据得到第一压缩码流,并保存所述第一压缩码流至所述第一预设文件;
读取并输出所述第一码流数据至解码器进行解码,获取所述媒体文件的图像信息及第二码流数据,并保存所述图像信息至第二预设文件;
采用所述哈希算法压缩方式压缩所述第二码流数据得到第二压缩码流,并保存所述第二压缩码流至所述第二预设文件。
在其中一个实施例中,还包括如下步骤:
根据采用所述哈希算法压缩方式获取的哈希值,分别比较所述第一压缩码流与第一预设参考文件,以及所述第二压缩码流与第二预设参考文件,获取测试结果,确定所述第一压缩码流和所述第二压缩码流是否正确。
在其中一个实施例中,所述采用哈希算法压缩方式压缩所述第一码流数据得到第一压缩码流,包括如下步骤:
为哈希值计算设置初始化值;
对所述第一码流数据中的每一笔码流进行补位填充,并对补位填充后的所述每一笔码流附加所述每一笔码流的原始长度值;
分割所述每一笔码流,获取多个相同大小的第一数据块M0-Mn;其中,n取正整数;
采用压缩函数分组处理所述每一笔码流的所述第一数据块,直至所述第一码流数据中的所有码流全部处理完成,得到所述第一压缩码流。
在其中一个实施例中,所述采用压缩函数分组处理所述每一笔码流的所述第一数据块,包括如下步骤:
标识计算所述哈希值所需的第一缓冲区、第二缓冲区和第三缓冲区;
其中,所述第一缓冲区为5个32位字的缓冲区;所述第二缓冲区为80个32位字的缓冲区;所述第三缓冲区为1个32位字的缓冲区;且,
所述第一缓冲区标识为H0、H1、H2、H3、H4;所述第二缓冲区标识为W0-W79;所述第三缓冲区标识为TEMP;
将每个所述第一数据块Mi分成16个字:W0-W15;其中,W0为最左边的字;i大于等于0,且小于等于n;
对于i大于等于16,且小于等于79,令Wi=S1(Wi-3xor Wi-8xor Wi-14xor Wi-16);
令A=H0,B=H1,C=H2,D=H3,E=H4;
对于i大于等于0,且小于等于79,执行循环TEMP=S5(A)+fi(B,C,D)+E+Wi+Ki;E=D;D=C;C=S30(B);B=A;A=TEMP;
令H0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E;
其中,fi(B,C,D)为所述压缩函数;Ki为常量字;A为第一中间变量,B为第二中间变量,C为第三中间变量,D为第四中间变量,E为第五中间变量。
在其中一个实施例中,所述压缩函数fi(B,C,D)为:
所述常量字Ki为:
在其中一个实施例中,所述采用所述哈希算法压缩所述第二码流数据得到第二压缩码流,包括如下步骤:
为哈希值计算设置初始化值;
对所述第二码流数据中的每一笔码流进行补位填充,并对补位填充后的所述每一笔码流附加所述每一笔码流的原始长度值;
分割所述每一笔码流,获取多个相同大小的第二数据块M0’-Mn’;其中,n取整数;
采用压缩函数分组处理所述每一笔码流中的所述第二数据块,直至所述第二码流数据中的所有码流全部处理完成,得到所述第二压缩码流。
相应的,基于同一发明构思,本发明还提供了一种数据存储系统,包括解析存储模块、第一压缩模块、读取保存模块、解码器和第二压缩模块;其中,
所述解析存储模块,用于解析媒体文件,获取所述媒体文件的媒体信息及第一码流数据,并保存所述媒体信息至第一预设文件;
所述第一压缩模块,用于采用哈希算法压缩方式压缩所述第一码流数据得到第一压缩码流,并保存所述第一压缩码流至所述第一预设文件;
所述读取保存模块,用于读取并输出所述第一码流数据至所述解码器;
所述解码器,用于对所述第一码流数据进行解码,获取所述媒体文件的图像信息及第二码流数据;
所述读取保存模块,还用于保存所述图像信息至第二预设文件;
所述第二压缩模块,用于采用所述哈希算法压缩方式压缩所述第二码流数据得到第二压缩码流,并保存所述第二压缩码流至所述第二预设文件。
在其中一个实施例中,还包括比较模块;
所述比较模块,用于根据所述哈希算法压缩方式获取的哈希值,分别比较所述第一压缩码流与相应的第一预设参考文件,以及所述第二压缩码流与相应的第二预设参考文件,获取测试结果,确定所述第一压缩码流和所述第二压缩码流是否正确。
在其中一个实施例中,所述第一压缩模块包括第一初始化设置单元、第一补位填充单元、第一附加长度值单元、第一分割单元和第一处理单元;其中,
所述第一初始化设置单元,用于为所述哈希值计算设置初始化值;
所述第一补位填充单元,用于对所述第一码流数据中的每一笔码流进行补位填充;
所述第一附加长度值单元,用于对补位填充后的所述每一笔码流附加所述每一笔码流的原始长度值;
所述第一分割单元,用于分割所述每一笔码流,获取多个相同大小的第一数据块M0-Mn;其中,n取正整数;
所述第一处理单元,用于采用压缩函数分组处理所述每一笔码流中的所述第一数据块,直至所述第一码流数据中的所有码流全部处理完成,得到所述第一压缩码流。
在其中一个实施例中,所述第一处理单元包括标识子单元、分字子单元、第一计算子单元、赋值子单元、循环子单元和第二计算子单元;其中,
所述标识子单元,用于标识计算所述哈希值所需的第一缓冲区、第二缓冲区和第三缓冲区;
其中,所述第一缓冲区为5个32位字的缓冲区;所述第二缓冲区为80个32位字的缓冲区;所述第三缓冲区为1个32位字的缓冲区;且,
所述第一缓冲区标识为H0、H1、H2、H3、H4;所述第二缓冲区标识为W0-W79;所述第三缓冲区标识为TEMP;
所述分字子单元,用于将每个所述第一数据块Mi分成16个字:W0-W15;其中,W0为最左边的字;i大于等于0,且小于等于n;
所述第一计算子单元,用于对于i大于等于16,且小于等于79,令Wi=S1(Wi-3xor Wi-8xor Wi-14xor Wi-16);
所述赋值子单元,用于令A=H0,B=H1,C=H2,D=H3,E=H4;
所述循环子单元,用于对于i大于等于0,且小于等于79,执行循环TEMP=S5(A)+fi(B,C,D)+E+Wi+Ki;E=D;D=C;C=S30(B);B=A;A=TEMP;
所述第二计算子单元,用于令H0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E;
其中,fi(B,C,D)为所述压缩函数;Ki为常量字;A为第一中间变量,B为第二中间变量,C为第三中间变量,D为第四中间变量,E为第五中间变量。
上述数据存储方法的有益效果:
在媒体自动化测试中,通过对媒体文件进行解析,获取媒体文件的媒体信息和媒体文件的第一码流数据后,对媒体信息不进行压缩直接存储。同时,采用哈希算法对第一码流数据进行压缩后得到第一压缩码流并存储至第一预设文件中,实现对媒体文件的第一次压缩。然后,将第一码流数据输入至解码器进行解码,获取媒体文件的图像信息以及第二码流数据,其中,图像信息不进行压缩直接存储,而第二码流数据则采用哈希算法进行压缩得到第二压缩码流并存储至第二预设文件。其通过对媒体文件进行两次压缩,并且两次压缩均采用哈希算法来实现,从而使得媒体文件中只有少量媒体信息及图像信息不压缩之外,其余绝大部分的码流数据均进行了压缩,有效地节省了存储空间。最终有效地解决了现有的数据存储压缩方法压缩后的文件仍占用较大的存储空间的问题。
附图说明
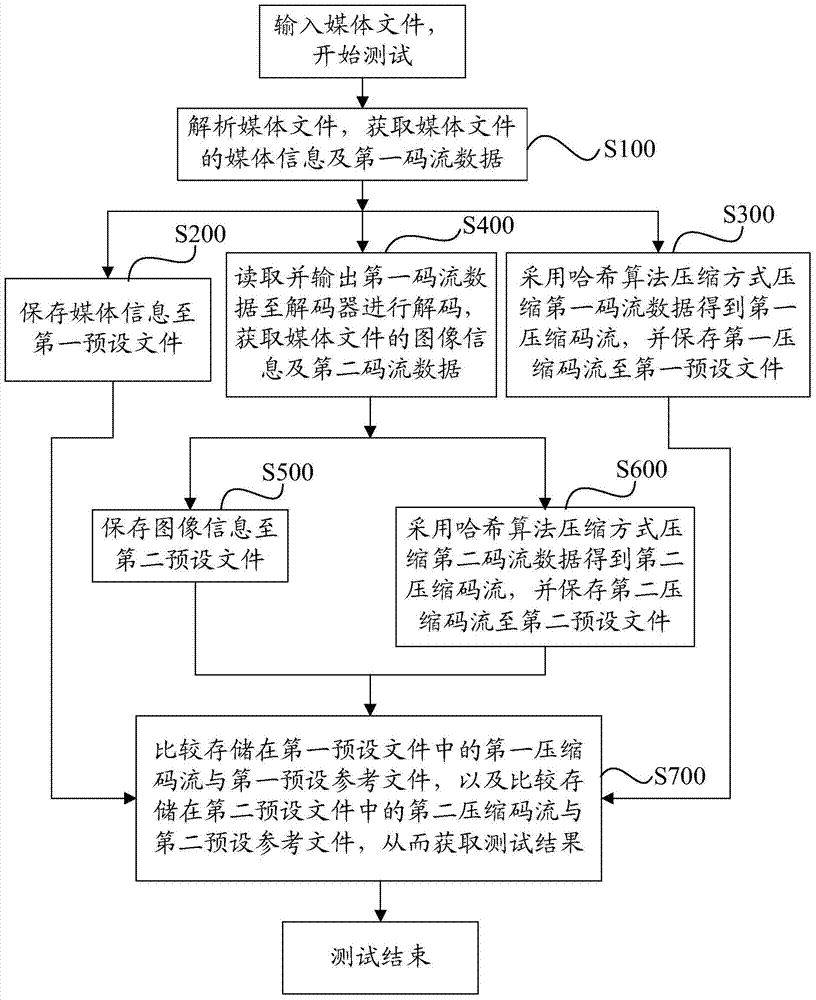
图1为本发明的数据存储方法一具体实施例流程图;
图2为本发明的数据存储方法一具体实施例中,采用哈希算法压缩第一码流数据中的每一笔码流的流程图;
图3为本发明的数据存储系统一具体实施例结构示意图;
图4为本发明的数据存储系统一具体实施例中第一压缩模块结构示意图。
具体实施方式
为使本发明技术方案更加清楚,以下结合附图及具体实施例对本发明做进一步详细说明。
参见图1,作为本发明提供的数据存储方法的一具体实施例,用于对媒体自动化测试中的媒体文件进行处理,包括如下步骤:
步骤S100,解析媒体文件,获取媒体文件的媒体信息及第一码流数据后,执行步骤S200,保存媒体信息至第一预设文件。
同时,执行步骤S300,采用哈希算法压缩方式压缩第一码流数据得到第一压缩码流,并保存第一压缩码流至第一预设文件。
另外,还同时执行步骤S400,读取并输出第一码流数据至解码器进行解码,获取媒体文件的图像信息及第二码流数据后,执行步骤S500,保存图像信息至第二预设文件。
同时,执行步骤S600,采用哈希算法压缩方式压缩第二码流数据得到第二压缩码流,并保存第二压缩码流至第二预设文件。
其通过在媒体自动化测试过程中,对媒体文件进行解析,获取媒体文件的媒体信息(包括媒体文件中的音频、视频、字幕等的大小、时间戳等信息)以及第一码流数据(即媒体文件压缩之前的数据)。其中,媒体信息不进行任何压缩直接存储,第一码流数据则采用哈希算法进行压缩后得到第一压缩码流再进行存储。同时,经第一码流数据输出至解码器进行解码,获取媒体文件的图像信息(包括图像的尺寸、像素比、宽度、高度、输出像素格式等信息)以及第二码流数据(即媒体文件的每一帧图像的码流数据)。其中,图像信息不进行压缩直接存储,而第二码流数据则采用哈希算法进行压缩后得到第二压缩码流再进行存储。也就是说,对媒体文件的一些基本信息,如媒体信息和图像信息不进行压缩,而媒体文件的绝大部分数据码流则采用哈希算法进行压缩后再存储。
由于采用哈希算法进行数据压缩时,始终把需要压缩的码流数据当成一个比特字符串来处理。假设,码流为“8ab”被转换成一个二进制的比特字符串为00111000 01100001 01100010,表示为十六进制的比特字符串为0x386162。因此,采用哈希算法分别对媒体文件的第一码流数据和第二码流数据进行压缩,使得压缩后得到的第一压缩码流和第二压缩码流均为较少比特位数的压缩码流。也就是说,采用哈希算法进行媒体文件压缩时,最终得到压缩后的媒体文件为较少比特位数的压缩码流,从而实现了利用较少比特位数存储大量码流数据的目的,因此节省了存储空间。有效解决了现有的数据存储中即使对数据压缩后再进行存储仍占用较大空间的问题。
并且,相较于现有的数据压缩存储,本发明的数据存储方法采用哈希算法进行压缩时,每一帧任意长度的码流数据均可以保存为一个定长的比特串,能够充分利用哈希算法的防冲突和散列均匀分布等特性。其中,任意两不同的码流数据,其哈希值相同的概率趋近于1/2N。即任意两帧的码流数据几乎不可能具有相同的哈希值,这也就提高了数据压缩存储的可靠性,从而保证了媒体自动化测试结果的正确性。
同时,采用哈希算法进行数据压缩时,虽然产生的哈希值相同是有概率的,这也是将大空间映射成有限小空间的必然结果。但是,2N的数量仍然非常巨大,两个不同码流数据的哈希值碰撞(即相同)的概率仍然很小。即使发生碰撞,也可以再逐位比对原始码流数据以进一步确认。并且,不同的哈希值一定代表不同的码流数据,因此在媒体自动化测试中,通过采用哈希算法对媒体文件进行压缩存储,其中依靠哈希算法产生的哈希值作为测试中初步判断依据,不需要对压缩后的媒体文件进行解压,从而加快了测试过程中的比对速率,具有高效和可靠性强的特点。
需要说明的是,在媒体自动化测试过程中,需要将压缩后的媒体文件与预设的参考文件进行比较测试,以检测压缩后的媒体文件是否准确。因此,作为本发明的数据存储方法的一具体实施例,其还包括比较检测的步骤。即,步骤S700,根据采用哈希算法压缩方式获取的哈希值,比较存储在第一预设文件中的第一压缩码流与其相应的第一预设参考文件,以及比较存储在第二预设文件中的第二压缩码流与其相应的第二预设参考文件,从而获取测试结果,以确认第一压缩码流和第二压缩码流是否正确。
具体的:
当输入一个45MB的AVI视频文件时,通过媒体格式进行解析,获取媒体信息(包括文件大小、时间戳等),将获取的媒体信息用于初始化解码器,并且不需要经过哈希算法压缩而直接写入到第一预设文件中保存用于测试结果比对。然后,将解析出来的每一笔码流数据读取出来并输出至解码器进行解码,并且将每一笔解析出来的码流数据经过哈希算法压缩之后得到第一压缩码流,并保存至第一预设文件中用于测试结果比对。
接着,将解码获取的每一帧图像信息(包括图像宽度、高度、输出像素格式等),不经过哈希算法压缩直接写入第二预设文件中保存用于测试结果比对。紧接着,采用哈希算法压缩解码之后的码流数据(即第二码流数据)得到第二压缩码流,然后保存至第二预设文件中用于测试结果比对。
最后,分别把保存的结果文件与其相对应的参考文件进行比较,即第一压缩码流与其相应的第一预设参考文件进行比较,第二压缩码流与其相应的第二预设参考文件进行比较,从而得出测试结果。
进一步的,可把得到的测试结果保存成XML文件,以便于后续查看和检阅。
在上述实施例中,只需要压缩第一码流数据和第二码流数据,并且不需要解压缩即可得到原始码流,在媒体自动化测试中,需要保存的媒体文件的媒体信息及12647笔码流数据(即第一码流数据中的所有码流)压缩后所占存储空间为2MB;同时,需要保存的媒体文件的图像信息及相应的12467帧码流数据(即第二码流数据中的所有码流)压缩后所占存储空间为1.3MB。与压缩之前的93MB和92MB相比,需要的存储空间仅为压缩前的1.78%。由此表明,采用本发明提供的数据存储方法,极大地节省了存储空间。同时,由于文件进行比较的时间与文件的大小有关,而本发明的数据存储方法中压缩后的码流容量非常小,因此相对的也就减少了文件比较时间,加快了测试流程。
需要说明的是,当采用哈希算法进行第一码流数据的压缩时,首先要执行步骤S310,对第一码流数据进行一系列的预处理,其中包括分割、补位填充、附加长度值和初始化等操作。需要指出的是,对第一码流数据进行预处理时,可通过分别对第一码流数据中的每一笔码流进行相应的预处理来实现。并且,对第一码流数据中的每一笔码流进行预处理时,分割、补位填充、附加长度和初始化等操作的执行顺序可以相互更换。并不以本发明所提供的顺序为唯一实施例。
另外,进一步的,通过解码器对第一码流数据解码后获取的第二码流数据同样也是采用哈希算法进行压缩,其采用哈希算法进行压缩时的执行步骤与采用哈希算法对第一码流数据进行压缩的步骤相同,因此,以下只以采用哈希算法对第一码流数据进行压缩为例,来详细说明采用哈希算法进行数据的压缩处理过程。
具体的,参见图2,首先执行步骤S311,为哈希值计算设置初始化值。其中,初始化值设置为:H0=0x67452301,H1=0xEFCDAB89,H2=0x98BADCFE,H3=0x10325476,H4=0xC3D2E1F0。也就是说,将第一码流数据中的每一笔码流压缩之后的压缩码流初始化为5个32位字的十六进制字符串。即首先对要进行压缩的每一笔码流设置初始的哈希值,并将设置的初始的哈希值存储至计算哈希值所需的第一缓冲区。其中,第一缓冲区为5个32位字的缓冲区H0,H1,H2,H3,H4。
然后便可对第一码流数据中的每一笔码流进行补位填充和附加长度值。
此处,需要说明的是,在对每一笔码流进行补位填充和附加长度值之前,可优先执行步骤S312,对每一笔码流按照预设单位进行分割,获取多个相同大小的第一数据块M0-Mn,n取正整数。其中,分割获取的每一个第一数据块Mi(i大于等于0,且小于等于n)的大小为512位,最终每一笔码流可分为n组,每组512位。这也就使得对每一笔码流进行处理时,可分别处理每一笔码流中的每一个第一数据块,进而得到压缩后的码流数据。
然后,可执行步骤S313,对每一笔码流进行补位填充。即给每一笔码流填充比特。采用哈希算法进行数据压缩时,码流需要进行补位处理,以使其补位后的码流长度在对512取模后的余数为448。即使长度已经满足对512取模后余数是448,补位也需要进行。具体的补位操作为:先补一个1,然后再补0,直至每一笔码流的码流长度满足对512取模后余数是448。也就是说,对每一笔码流进行补位操作时,补位的个数至少为一位,最多为512位。
接着,执行步骤S314,对补位填充后的每一笔码流附加每一笔码流的原始长度值。即给补位后的每一笔码流附加长度值。其所附加的长度值为每一笔码流在进行补位填充之前的原始长度值。也就是说,将未进行补位填充的每一笔码流的码流长度相应的补到已经进行补位填充的每一笔码流的后面。如果原始的(即未进行补位填充的)的码流的长度超过了512,则将其补成512的倍数。
然后,执行步骤S320,采用压缩函数分组处理每一笔码流,直至第一码流数据中的所有码流全部处理完成后,获取第一压缩码流。
另外,采用压缩函数分组处理每一笔码流时,由于将每一笔码流分割成了多个第一数据块Mi。因此,通过分别处理每个第一数据块Mi,从而最终得到每一笔码流压缩后的字符串。也就是说,采用压缩函数分组处理每一笔码流时,可通过分别处理每一笔码流中的每一个第一数据块Mi来实现。
通过对每一笔码流分割为多个第一数据块Mi,其中每个第一数据块Mi的数据长度为512比特。对每一笔码流以512比特为单位进行处理,在处理过程中需要一系列的压缩函数fi(B,C,D)。其中,i大于等于0,且小于等于79;n的取值为79。每个压缩函数fi(B,C,D)都操作32位字(B、C、D),并且产生32位字作为输出。同时,对每一笔码流进行哈希值的计算时需要三个缓冲区,分别为第一缓冲区、第二缓冲区和第三缓冲区。其中,第一缓冲区如前面所提到的为5个32位字的缓冲区。该5个32位字的缓冲区被标识为H0,H1,H2,H3,H4。第二缓冲区为80个32位字的缓冲区,该80个32位字的缓冲区被标识为W0、W1、W2、……W79。第三缓冲区为1个32位字的缓冲区,该1个32位字的缓冲区被标识为TEMP。另外,还包括一系列的常量字,而一系列的常量字则被标识为Ki。
进一步的,压缩函数fi(B,C,D)可以作如下定义:
常量字Ki则用十六进制表示,为:
为了得到每一笔码流压缩后的160位码流,需要对每个512位的第一数据块M1,M2,...,Mn依次进行处理,处理每个第一数据块Mi包含80个步骤。在处理每个第一数据块Mi之前,第一缓冲区{Hi}被初始化为H0,H1,H2,H3,H4。
具体的,处理M1,M2,……,Mn时,需要进行如下步骤:
步骤S321,将每个第一数据块Mi分成16个字:W0、W1、W2、W3、……W15,W0是最左边的字。
步骤S322,对于i=16到79,令Wi=S1(Wi-3xor Wi-8xor Wi-14xor Wi-16)。
步骤S323,令A=H0,B=H1,C=H2,D=H3,E=H4。
步骤S324,对于i=0到79,执行下面的循环TEMP=S5(A)+fi(B,C,D)+E+Wi+Ki;E=D;D=C;C=S30(B);B=A;A=TEMP。
步骤S325,令H0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E。在处理完所有的第一数据块后,每一笔码流即被压缩成一个160位的字符串。
其中,参见图2,当采用压缩函数处理每一笔码流时,可通过两次判断来确定每一笔码流是否处理完。首先,执行步骤S330,实时判断当前正在处理的该笔码流中的一个第一数据块Mi是否处理完成。若否,则返回步骤S320,继续处理该笔码流中的当前第一数据块Mi。若是,则执行步骤S340,进一步判断当前正在处理的该笔码流中的n组第一数据块是否处理完;若是,则结束处理操作。若否,则返回步骤S310,继续对第一码流数据中的当前正在处理的该笔码流进行分割及处理。
更进一步的,当执行步骤S600,采用哈希算法压缩第二码流数据得到第二压缩码流时,其具体的处理过程同步骤S300相同。即,具体包括如下步骤:
步骤S611,为哈希值计算设置初始化值;其中,初始化值为:H0=0x67452301,H1=0xEFCDAB89,H2=0x98BADCFE,H3=0x10325476,H4=0xC3D2E1F0。
步骤S612,对第二码流数据中的每一笔码流进行补位填充,并对补位填充后的每一笔码流附加每一笔码流的原始长度值。
步骤S613,按预设单位分割每一笔码流,获取多个相同大小的第二数据块M0’–Mn’;其中,n取正整数。
步骤S620,采用压缩函数分组处理每一笔码流,直至第二码流数据中的所有码流全部处理完成后,获取第二压缩码流。
需要说明的是,由于采用哈希算法对第二码流数据进行压缩得到第二压缩码流时的具体的步骤同采用哈希算法对第一码流数据进行压缩的过程相同。因此,此处不再进行赘述。
相应的,基于同一发明构思,本发明还提供了一种数据存储系统。由于本发明提供的数据存储系统的工作原理与本发明提供的数据存储方法的原理相同或相似,因此重复之处不再赘述。
参见图3,作为本发明提供的一种数据存储系统,用于处理媒体自动化测试中的媒体文件,包括解析存储模块100、第一压缩模块200、读取保存模块300、解码器400和第二压缩模块500。其中,
解析存储模块100,用于解析媒体文件,获取媒体文件的媒体信息及第一码流数据,并保存媒体信息至第一预设文件。
第一压缩模块200,用于采用哈希算法压缩第一码流数据得到第一压缩码流,并保存第一压缩码流至第一预设文件。
读取保存模块300,用于读取并输出第一码流数据至解码器400。
解码器400,用于对第一码流数据进行解码,获取媒体文件的图像信息及第二码流数据;
读取保存模块300,还用于保存图像信息至第二预设文件。
第二压缩模块500,用于采用哈希算法压缩第二码流数据得到第二压缩码流,并保存第二压缩码流至第二预设文件。
其中,还包括比较模块600。比较模块600,用于分别比较第一压缩码流与相应的第一预设参考文件,以及第二压缩码流与相应的第二预设参考文件,获取测试结果。
作为一种可实施方式,参见图4,第一压缩模块200包括第一初始化设置单元210、第一补位填充单元220、第一附加长度值单元230、第一分割单元240和第一处理单元250。
其中,第一初始化设置单元210,用于为哈希值计算设置初始化值;其中,初始化值为:H0=0x67452301,H1=0xEFCDAB89,H2=0x98BADCFE,
H3=0x10325476,H4=0xC3D2E1F0。
第一补位填充单元220,用于对第一码流数据中的每一笔码流进行补位填充。
第一附加长度值单元230,用于对补位填充后的每一笔码流附加每一笔码流的原始长度值。
第一分割单元240,用于分割每一笔码流,获取多个相同大小的第一数据块M0-Mn;其中,n取正整数。
第一处理单元250,用于采用压缩函数分组处理每一笔码流,直至第一码流数据中的所有码流全部处理完成后,获取第一压缩码流。
需要说明的是,第一处理单元250包括标识子单元251、分字子单元252、第一计算子单元253、赋值子单元254、循环子单元255和第二计算子单元256。
其中,标识子单元251,用于标识计算哈希值所需的第一缓冲区、第二缓冲区和第三缓冲区。
其中,第一缓冲区为5个32位字的缓冲区;第二缓冲区为80个32位字的缓冲区;第三缓冲区为1个32位字的缓冲区。并且,第一缓冲区标识为H0、H1、H2、H3、H4、H5;第二缓冲区标识为W0-W79;第三缓冲区标识为TEMP。
分字子单元252,用于将每个第一数据块Mi分成16个字:W0-W15;其中,W0为最左边的字,i大于等于0,且小于等于n。
第一计算子单元253,用于对于i大于等于16,且小于等于79,令Wi=S1(Wi-3xor Wi-8xor Wi-14xor Wi-16)。
赋值子单元254,用于令A=H0,B=H1,C=H2,D=H3,E=H4。
循环子单元255,用于对于i大于等于0,且小于等于79,执行循环TEMP=S5(A)+fi(B,C,D)+E+Wi+Ki;E=D;D=C;C=S30(B);B=A;A=TEMP。
第二计算子单元256,用于令H0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E。
其中,fi(B,C,D)为压缩函数;Ki为常量字;A为第一中间变量,B为第二中间变量,C为第三中间变量,D为第四中间变量,E为第五中间变量。
另外,需要指出的是,由于第二压缩模块500采用哈希算法压缩第二码流数据得到第二压缩码流的工作原理与第一压缩模块200的工作原理相同或相似。因此,相应的,第二压缩模块500包括第二初始化设置单元、第二补位填充单元、第二附加长度值单元、第二分割单元和第二处理单元等单元(图中均未示出)。由于第二压缩模块500的压缩过程与第一压缩模块200相同,因此此处不再赘述。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!