一种LDPC的解码方法与流程
本发明涉及译码器领域,尤其涉及一种LDPC的解码方法。
背景技术:
低密度奇偶校验码(LDPC)是一类线性分组码,其译码具有并行译码结构的特点,处理速度快,随着VLSI技术的快速发展,越来越多的通信系统采用LDPC码作为它们的译码方案。LDPC码的理论基础是二分图(又称Tanner图),在码长无限长、二分图无环的情况下,基于软判决的消息传递算法等价于最优的最大似然译码。
LDPC的译码器结构有:洪水式更新、横向和纵向更新。其中洪水式结构是在每次迭代更新时,变量节点和校验节点都采用上次更新时的值;而横向结构(又称turbo结构、分层结构)是在每次迭代更新时,在校验节点更新后,变量节点的更新采用本次校验节点更新后的输入值。纵向结构是在每次迭代更新时,在变量节点更新后,校验节点的更新采用本次变量节点更新后的输入值。LDPC的处理有并行、串行和混合三种处理方式。由于校验矩阵的每行和每列之间没有必然联系,这样在进行校验节点和变量节点更新时可同时进行,即并行处理,可达到最大的译码速度,但所花费的硬件资源也是最大的。与并行处理方式相对应的另一种处理方式是串行处理,即每行和每列的更新采用串行的方式,这样的处理方式速度最慢,但耗费的硬件资源最小。混合处理是在进行硬件设计时,为满足实际系统的要求,需要进行折中的一种处理,可对其一部分进行同时处理,这样在处理速度和硬件资源上达到折中,可以通过调整并行处理因子P来满足实际系统的要求。
对于洪水式、横向和纵向结构,这三种结构在实现方式上各有不同,相应的在每次迭代更新中,需要存储的中间变量也不同。洪水式结构的存储量大约是横向结构和纵向结构的一倍左右,且更新速度较慢,但它适合任何形式的校验矩阵;而对于横向结构和纵向结构来说,由于在校验节点(或变量节点)更新后,变量节点(或校验节点)立刻采用更新后的输入,所以无需存储这个中间变量,相应的存储memory也减少一倍,且由于采用更新后的输入,收敛速度加快,在达到同样的ber时,收敛速度可提高一倍左右;但另一方面的是需仔细设计相应的校验矩阵,以保证这种更新在硬件设计时能够较为方便的得以实现,例如像QC-LDPC这种具有一定规则结构的码集,采用它来实现显得尤为方面。但是现有技术中有其局限性,例如现有技术的算法实现复杂高,存储大,已知的简化算法性能有损失,此外在编码逻辑过程中已有的LLR运算需要存储量大的存储器。
技术实现要素:
针对现有技术中存在的问题,本发明提供了一种LDPC的解码方法,能够减小存储量和迭代次数。
本发明采用如下技术方案:
一种LDPC的解码方法,所述解码方法包括:
在rwsr(Row-Wise Scanning Round,行序串行扫描)阶段,恢复电路读取前次存储的每个符号位、最小值的绝对值、次小值的绝对值和第三小值的绝对值,经恢复电路恢复出前次校验节点更新单元的每个输出,具体为:
对所述比较和选择器的输出进行移位操作后和所述符号位合并,得到所述前次校验节点的更新消息,通过加法电路将所述更新消息从后验概率中减去,得到本次所述更新单元更新的输入;
在cwsr(Column-Wise Scanning Round,列序串行扫描)阶段,将恢复电路输出的每个更新信息,经搜索模块寻找其中的最小值的绝对值、次小值的绝对值和第三小值的绝对值和对应位置,以及每个符号位存储于对应的ram(random access memory,随机存取存储器)中,同时更新后验概率的值。
所述解码方法还包括:
在所述rwsr阶段,重排网络取出所述后验概率中的值,并根据每块矩阵中的偏移地址对应至所述更新单元的输入,以实现重排;
在所述cwsr阶段,所述重排网络根据所述偏移地址将所述更新单元的输出更新回所述后验概率中,以实现反重排。
在所述cwsr阶段,校验方程计算单元验证当前译出的码字是否有效。
所述恢复电路、所述搜索模块、所述加法电路采用多路并行工作模式。
所述解码方法中的解码公式为:
;
其中,为第k次迭代中,校验节点c传给变量节点v的外部对数似然比信息;为第k-1次迭代中,变量节点n传给校验节点c的外部对数似然比信息;为和校验节点c相连的除了变量节点v以外的其它变量节点结合;是集合中最小的3个值;sgn()为取符号位运算;ɑ为用来减少3-min 在计算中值偏大问题的归一化因子;为单调递减函数。
其中函数采用LLR运算实现。
所述LLR的运算公式为:
;
其中,c为量化因子;a和b的绝对值均为设定取值范围内的数值。
所述解码方法中,在每次校验节点的更新中存储所述最小值的绝对值及其相应的位置和所述次小值的绝对值及其相应的位置和所述第三小值的绝对值及其相应的位置。
所述解码方法中,存储校验节点对应的变量节点的每个符号位。
所述解码方法中,采用两个存储所述后验概率的消息,以进行乒乓动作。
本发明的有益效果是:
本发明的存储量可以是和积算法的一半左右,在达到同样的BER性能时,迭代次数也能达到和积算法的一半左右,在面积和处理速度方面达到折中。本发明根据DTMB LDPC码的结构特点,在综合考虑性能和硬件实现两方面,提出了一种简化的解码方法以及LLR运算的计算方法,在性能上和原算法等价,且其硬件实现资源比原算法可减少较多的存储容量。
附图说明
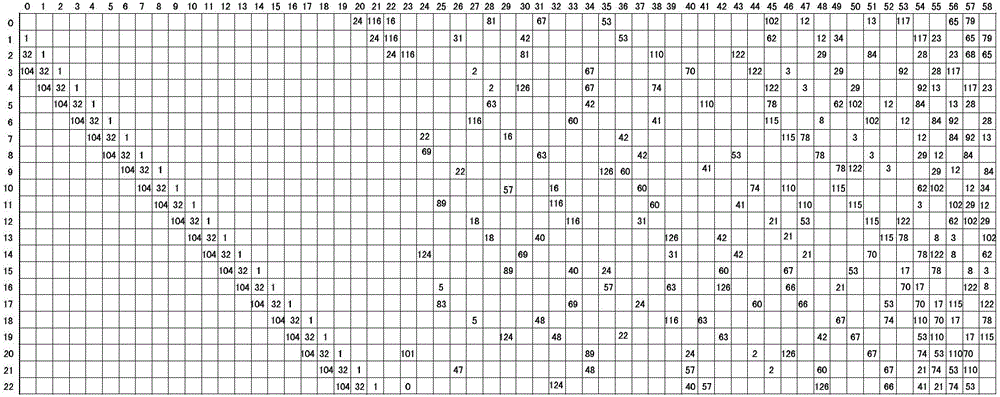
图1a-1c为本发明DTMB所构造的非规律准循环校验矩阵;
图2为本发明恢复电路的工作原理图;
图3为本发明搜索模块的工作原理图;
图4为本发明重排网络的结构示意图;
图5为本发明校验方程模块的工作示意图;
图6为本发明DTMB LDPC的设备连接图;
图7为本发明LDPC的实现流程图;
图8a-8j为本发明的仿真结果图;
图9为本发明中LLR运算单元的仿真结果图。
具体实施方式
需要说明的是,在不冲突的情况下,下述技术方案,技术特征之间可以相互组合。
下面结合附图对本发明的具体实施方式作进一步的说明:
目前使用的LDPC码的构造方式较多,主要有两大类常用的码集:伪随机构造的校验矩阵和准循环构造的校验矩阵。伪随机构造的校验矩阵虽然在性能方面表现良好,但实现起来不太实际;而准循环构造的校验矩阵在性能方面并不亚于随机构造的校验矩阵,且其编码复杂度与码长成线性比例,译码也较为简便,因而在实际系统中得到大量应用。如:新一代dvb标准(dvb-c2,dvb-s2,dvb-t2),cmmb, Ieee 802.11, Ieee 802.16和dtmb。
本发明中的LDPC码的译码有两类:硬判决译码和软判决译码。软判决译码通常比硬判决译码具有更高的编码增益,其中软判决译码算法,即原算法(和-积算法)的步骤主要包括如下部分:
第一步:初始化信道的内部似然比值
第二步:校验节点更新(横向更新)
其中,
第三步:变量节点更新(纵向更新)
第四步:硬判决
第五步:迭代终止
当满足,或者达到设定的最大迭代次数时迭代终止,否则回到第二步继续迭代。
本实施例提出一种解码的修正简化方法和解码过程中的LLR运算过程,由于原算法在校验节点更新时,涉及到复杂的函数,是一个单调递减函数,它的值是由较小的输入决定的。其中,在LDPC译码时,常用到如下的一些符号集,其含义为:
令表示第k次迭代中,校验节点c传给变量节点v的外部对数似然比信息。
令表示第k次迭代中,变量节点v传给校验节点c的外部对数似然比信息。
令表示变量节点v接收到来自信道的内部似然比值。
表示和校验节点c相连的变量节点结合。
表示和校验节点c相连的除了变量节点v以外的其它变量节点结合。
表示和变量节点v相连的校验节点结合。
表示和变量节点v相连的除了校验节点c以外的其它校验节点结合。
本实施例中,为简化处理,只使用其中3个最小值来简化运算,本实施例以3个最小值举例,基于这个思想,得到如下公式:
其中,是集合中最小的3个值;sgn()是取符号位运算;ɑ为归一化因子,用来减少3-min 在计算中值偏大的问题,我们可通过移位操作来简化运算,在具体实现时,是一个可配置的寄存器。采用LLR运算来实现:
其中LLR定义为:
上式中参数c为量化因子,在本实施例中,校验节点更新单元信息取6bit,其中1位符号,3为整数,2为小数,所以c取值为4。由于这是个超越函数,在具体实现时,我们需用一个查找表预先将其存储起来,其中|a|和|b|的取值范围是0~31,这样需要表的大小为32*32*6=6144bit。为减少存储,本实施例提出了一种等价运算方法,其计算方法如下所示:
首先定义:
z_small = min(|a|,|b|),为|a|和|b|中较小值
z_large = max(|a|,|b|),为|a|和|b|中较大值
z_diff = z_large - z_small 为两者的差值
然后按下式进行判断,求出z1和z2
if(z_small==0 && (z_diff==0 && z_large>=2))
z1 = 3;
else if(z_small==0 && (z_large<=2))
z1 = 2;
else if(z_small==0 && (z_large>=3 && z_large<=6))
z1 = 1;
else if(z_small==1 && (z_large<=7 && z_large!=4))
z1 = 1;
else if(z_large<=3 && z_diff==1)
z1 = 1;
else if(z_large<=5 && (z_diff==2 || z_diff==0))
z1 = 1;
else if(z_small<=2 && (z_diff==6))
z1 = 1;
else if( (z_small<=8 && z_small>=3) && z_diff==8)
z1 = 1;
else
z1 = 0;
if ((z_diff==0 && z_large>=2))
z2 = 3;
else if ((z_diff==1 && z_large>=5))
z2 = 2;
else if(z_large<=10 && z_diff<= 2 || z_large > 10 && z_diff<= 3)
z2 = 2;
else if(z_large<=10 && z_diff<= 6)
z2 = 1;
else if(z_large>10 && z_diff<= 8)
z2 = 1;
else
z2 = 0;
得到z1和z2后,在进行如下计算:
z_adj = z1 - z2;
LLR(|a|,|b|) = z_small + z_adj;
本实施例中,解码的过程主要包括如下步骤:为减少对memory的需求,采用normalized 3-min 进行数据压缩,然后将该算法和turbo调度策略结合起来,以减少存储量和实现复杂度。首先该算法在每次校验节点的更新中只存储6个值:最小值、次小值和第三小值的绝对值(每个5bit表示)和相应的位置(每个5比特表示);然后再存储每一符号位(大小等于H中“1”的总数)。对后验概率消息用两块ram存储(8比特表示,其中高2位两块ram进行合用),进行乒乓工作。具体实现情况如下:解码设备memory的使用情况:Romb和Romo分别用于存储校验矩阵基地址(H_base)和偏移地址(H_offset)表为[35*8 + 23*13 + 11*27] * 6 + [35*8 + 23*13 + 11*27]*7 = 11388bit;
Rami用于存储输入先验消息为59*127*6=44958bit;
Ramp用于存储后验概率消息为59*127*8 = 59944bit;
Ramm用于存储校验节点更新消息最小值、次小值和第三小值绝对值和相应位置 为35*127*3*10 = 133350bit;
Rams用于存储校验节点更新消息的符号位为299*127*1 = 37973bit。
总的memory大小为:11388 + 44958 + 59944 + 133350+ 37973=287613bit;
相比原算法memory大小为:11388+2*59*127*6+299*127*6 = 329142bit。节约大小为329142-287613=41529bit;
本实施例中的H_base和H_offset:图1a-1c为dtmb所构造的非规则准循环校验矩阵,可以将这个矩阵用基地址H_base和偏移地址H_offset两个矩阵来表示,图中每个小方块表示127*127的小矩阵,里面的数字代表单位阵的偏移地址,无数字的表示“0”矩阵。以0.4码率为列来说明,第0行块所对应的H_base为32,33,34,35,43,51,53;H_offset对应为67,41,21,74,3,13,117;其它的依次类推。码率为0.4的校验矩阵行度row_degree为7和8;列度col_degree为3、4和11;码率为0.6的校验矩阵行度为12和13;列度为3、4、7和16;码率为0.8的校验矩阵行度为26和27;列度为3、4和11。由于DMB-TH的LDPC码字是系统码,且校验位在前,信息位在后,从校验矩阵列的度可看出,处在后面的信息位所对应列的度大,这样具有更高的译码可靠性,即所谓的不等错误保护特性。
本实施例中的LDPC解码器,其逻辑运算单元部分共有5块:恢复电路(recover)、搜索模块(searchor)、加法电路(adder)、重排网络(PMN)和校验方程计算(PEC)。其中recover、searchor、adder和PMN的电路结构如图2-4所示,分为两个工作阶段rwsr和cwsr,每个阶段的处理时间为行块的度(row_degree),也是累加器自加的范围。
在rwsr阶段时,recover读取前次存储在rams(符号位)和ramm(最小值、次小值和第三小值绝对值)的值,经过recover模块,恢复出前次校验节点更新单元(CNU)的每个输出。具体实现为:当累加器的值为最小值位置pos0时,选择器输出llr0;在次小值位置pos1时,输出llr1;在第三小值位置pos2时,输出llr2;在其它位置时,输出llr3;
其中llr0 = LLR(abs1 abs2),llr1 = LLR(abs0, abs2),llr2 = LLR(abs0, abs1),llr3 = LLR(LLR(abs0, abs1),abs2),LLR运算在前面已经给出了其计算方法。
然后对选择器的输出进行移位操作,移位因子alpha=0.9375,是一个可配置的寄存器,再和符号位合并,得到前次校验到比特节点的更新消息,然后经过adder模块将其从ramp(后验概率)中减去得到本次CNU单元更新的输入(比特节点到校验节点的消息)。其中recover、searchor和加法模块为127路单元并行工作。
在cwsr阶段时,根据本次CNU单元更新的输入,searchor模块寻找其中三个最小值的绝对值和对应的位置,然后和每个存储在对应的ramm和rams中的符号位,经过recover模块恢复出本次CNU的每个输出,将其和rwsr阶段adder模块的输出值(用寄存器暂存)相加,然后更新ramp的值。
PMN如图4所示,分为两个阶段工作;在rwsr阶段时,实现重排功能,将取出ramp中的值(按列方式存储),然后根据每块矩阵中的偏移地址127-H_offset,对应到每个校验节点更新单元(按行方式处理)的输入。在cwsr阶段时,实现反重排功能,根据每块矩阵中的偏移地址H_offset,将CNU的输出(按行方式处理)更新回ramp(按列方式存储)中。由于dtmb ldpc的校验矩阵具有准循环移位的特性,所以用简单的桶型移位(barrel shifter)来实现较为简便。我们对127路数据同时进行处理,这样要实现一个127 x 127的barrel shifter,需要127 x 7 = 889个8bit的选择器。
校验方程计算(PEC),电路结构如图5所示,只工作在cwsr阶段,以验证当前译出的码字是否有效,当一次大迭代完成后,所有的校验方程都满足时,表明当前译出的码字正确,这时不在进行后续迭代(在实际操作中,为防止每次小迭代更新的后验概率信息不是很准确,我们连续判定2次大迭代完成后,所有校验方程都满足)。否则继续进行,直到达到最大迭代次数为止。该电路由异或单元和或单元构成,127路并行运算。
在设计中,我们还需要控制逻辑,用于给出各模块所需的控制信号以及memory的读写使能:分为小迭代(每一行块)控制逻辑和Top控制:包括Romb和Romo的读使能,读地址;Ramp的读、写地址和读、写使能;Ramm和Ramms的读、写地址和读、写使能;rwsr和cwsr的控制,大迭代的循环所需的控制信号。图6为解码器的顶层结构。
图7给出了LDPC的实现流程,整个LDPC码的迭代分为大迭代和小迭代:小迭代是基于校验矩阵的每行所进行的迭代,包括rwsr和cwsr两个阶段,所有行的小迭代完成后,即完成了一次大迭代更新,即所有校验节点和变量节点的值都得到了一次计算,当达到设定的最大迭代次数或校验方程满足后,终止整个解码器的迭代,由硬判决给出最后的结果。
本实施例给出了具体硬件实现结构和仿真性能,对DTMB新测试标准规定的mode1~mode10分别对awgn、rice、rayleigh和0db-echo at 30us的性能进行了仿真,从仿真结果看,这种简化实现的结构在性能上要优于其它专利和文献的简化方法(比如normalized min-sum),在性能上和原算法等价,且其硬件实现资源比原算法可减少大约41K ram的存储。如图8a-8j所示,DTMB新测试标准规定的mode1~mode10在awgn、rice、rayleigh和0db-echo at 30us下的仿真性能。从图8a-8j中可看到,提出的简化方法和原算法在性能上是等价的。
图9是LLR运算单元原始方法和本实施例提出方法(如前所述:可节约存储单元)的仿真结果,从仿真的结果中可看到两者完全一致,图9中“*”代表原始log函数,蓝色“o”代表本文明提出的计算方法。
综上所述,本发明的存储量仅是和积算法的一半左右,在达到同样的BER性能时,迭代次数也是和积算法的一半左右,在面积和处理速度方面达到折中。本发明根据DTMB LDPC码的结构特点,在综合考虑性能和硬件实现两方面,提出了一种简化的解码方法以及LLR运算的计算方法,在性能上和原算法等价,且其硬件实现资源比原算法可减少较多的存储容量。
通过说明和附图,给出了具体实施方式的特定结构的典型实施列,基于本发明精神,还可作其他的转换。尽管上述发明提出了现有的较佳实施例,然而,这些内容并不作为局限。
对于本领域的技术人员而言,阅读上述说明后,各种变化和修正无疑将显而易见。因此,所附的权利要求书应看作是涵盖本发明的真实意图和范围的全部变化和修正。在权利要求书范围内任何和所有等价的范围与内容,都应认为仍属本发明的意图和范围内。
- 还没有人留言评论。精彩留言会获得点赞!