一种基于NLMS自适应滤波的信号处理方法与流程
本发明涉及一种基于nlms自适应滤波的信号处理方法,属于信号处理领域。
背景技术:
信息是一个比较抽象的概念,它包含在消息中,是通信系统中传送的对象。消息是具体的但不是物理的,例如语言、文字、符号等。信号是信息的载体,是表示消息的物理量,例如幅度、频率和相位都可代表消息。在接收信号时,符号间干扰和噪声(内部热噪声和外部干扰)都使信号受到损伤。信号处理的核心问题是信号的表示、变换和运算,并且提取其中的特征和信息。
自适应信号处理是信号处理领域的一个非常重要的分支。作为自适应信号处理基础的自适应滤波理论已经成为信号处理学科的重要组成部分。四十多年来,自适应滤波理论一直受到普遍的重视,并得到了不断的发展和完善。尤其是近年来,随着超大规模集成电路技术和计算机技术的迅速发展,出现了许多性能优异的高速信号处理专用芯片和高性能的通用计算机,特别是为自适应滤波器的发展和应用提供了重要的物质基础。另一方面,信号处理理论和应用的发展,也成为自适应滤波理论的进一步发展提供了必要的理论基础。可以这样说,自适应滤波理论和信号处理技术正在日益受到人们的重视,已经并将继续在诸如通信、雷达、声呐、自动控制、图像和语音处理、模式识别、生物医学、以及地震勘探等领域得到广泛的应用,并推动这些领域的进步。
在实际测量中,由于未知因素的影响导致测量结果产生误差,有时甚至与实际数据相差太大,因而怎样通过测量数据获得比较精确的实际数据是一个十分重要的数据处理问题。
技术实现要素:
为了解决上述问题,本发明通过提供一种基于nlms自适应滤波的信号处理方法。
本发明采用的技术方案一方面为一种基于nlms自适应滤波的信号处理方法,其特征在于,包括以下步骤:通过fir滤波器对待处理信号进行预处理,输出滤波器信号;对滤波器信号进行归一化最小均方误差自适应滤波和归一化最小均方误差自适应预测处理。
优选地,所述fir滤波器为基于kasier窗设计,其时域w[n]表达式为:
优选地,所述第一类修正贝塞尔函数基于以下公式:
优选地,对滤波器信号进行归一化最小均方误差自适应滤波步骤包括:
比较原信号和滤波器信号获取误差序列,获取其均值:
获取其均方值:
采用变换步长的方式缩短自适应收敛过程,步长公式为:w(n+1)=w(n)+e(n)x(n),式中,e(n)x(n)为滤波权矢量迭代更新的调整量;使用平方误差代替均方误差以修改权矢量,获得修正的权系数迭代公式:w(n+1)=w(n)+uγ+xt(n)x(n)e(n)x(n),则步长u(n)=w(n+1)-w(n),即u(n)=uγ+xt(n)x(n)e(n)x(n),其中,0≤γ≤1,0<u<2,e(n)x(n)=1,基于γ的变化,使步长由大逐渐变小,加速收敛过程。
优选地,所述归一化最小均方误差自适应预测处理基于自适应算法。
本发明的有益效果为通过对待处理信号先进行fir滤波器处理,然后基于归一化最小均方误差即nlem再次进行处理,通过多次处理以提高信号处理效率和处理效果。
附图说明
图1所示为基于本发明实施例的一种基于nlms自适应滤波的信号处理方法的示意图;
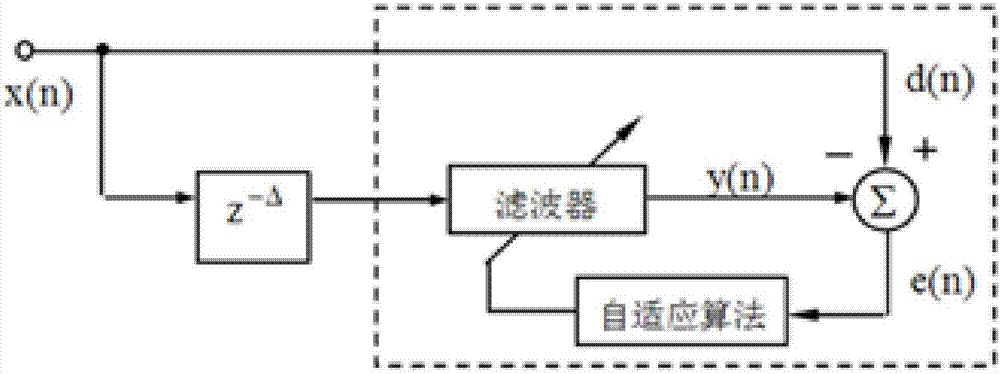
图2所示为基于本发明实施例的自适应预测滤波器结构框架图。
具体实施方式
以下结合实施例对本发明进行说明。
基于发明的实施例,如图1所示一种基于nlms自适应滤波的信号处理方法,其特征在于,包括以下步骤:通过fir滤波器对待处理信号进行预处理,输出滤波器信号;对滤波器信号进行归一化最小均方误差自适应滤波和归一化最小均方误差自适应预测处理。
滤波器的单位脉冲响应是一个有限长序列设单位脉冲响应h(n)长度为n其系统函数h(z)和差分函数分别为:
所述fir滤波器为基于kasier窗设计,其时域w[n]表达式为:
kaiser窗设计的滤波器具有严格的线性相位特性,它由零阶贝塞尔函数构成,其主瓣能量与旁瓣能量之比近乎最大,且可自由选择主瓣宽度和旁瓣高度间的比重。
所述第一类修正贝塞尔函数基于以下公式:
在经过上述kaiser窗设计的滤波器得到测量数据的修正值后,进过nlms自适应滤波进行进一步修正,nlms算法是采用变步长的方法来缩短自适应收敛过程。
对滤波器信号进行归一化最小均方误差自适应滤波步骤包括:
比较原信号和滤波器信号获取误差序列,获取其均值
获取其均方值:
采用变换步长的方式缩短自适应收敛过程,步长公式为:w(n+1)=w(n)+e(n)x(n),式中,e(n)x(n)为滤波权矢量迭代更新的调整量;
式中,e(n)x(n)表示滤波权矢量迭代更新的调整量。为了达到快速收敛的目的,必须合适的选择变步长的值,一个可能策略是尽可能多地减少瞬时平方误差,即用瞬时的平方误差作为均方误差的mse,这也是lms算法的基本思想。
使用平方误差代替均方误差以修改权矢量,获得修正的权系数迭代公式:w(n+1)=w(n)+uγ+xt(n)x(n)e(n)x(n),则步长u(n)=w(n+1)-w(n),即u(n)=uγ+xt(n)x(n)e(n)x(n),其中,0≤γ≤1,0<u<2,e(n)x(n)=1,基于γ的变化,使步长由大逐渐变小,加速收敛过程。
参数γ是为了避免xt(n)x(n)过小导致步长太大而设置的,0≤γ≤1。为了保证自适应滤波器能够稳定工作,固定收敛因子u的选取应满足的数值范围如下:0<u<2。
所述归一化最小均方误差自适应预测处理基于自适应算法。
而在仅知测量数据当前及以前的数据情况下,为进一步修正实际数据和测量数据之间的误差,可采用自适应预测滤波器实现,一种仅由测量数据,得出实际数据的自适应预测滤波器结构框架图如图2所示,其中,
滤波器的输入序列为理想序列:x(n)=[x(n-△)x(n-△-1)…x(n-△-l)]t,
权值为w(n)=[w0(n)w1(n)…wl(n)]t,
则滤波器输出就为:y(n)=xt(n)w(n),
预测误差为:e(n)=d(n)-y(n),
延迟单元z-△。
基于预测的误差的自适应反馈,提高信号处理能力。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。在本发明的保护范围内其技术方案和/或实施方式可以有各种不同的修改和变化。
- 还没有人留言评论。精彩留言会获得点赞!